 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Pose Verification for Outdoor Visual Localization with Self-supervised Contrastive Learning
Mar 31, 2022
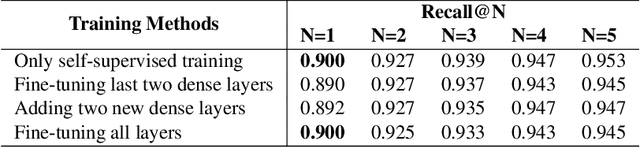
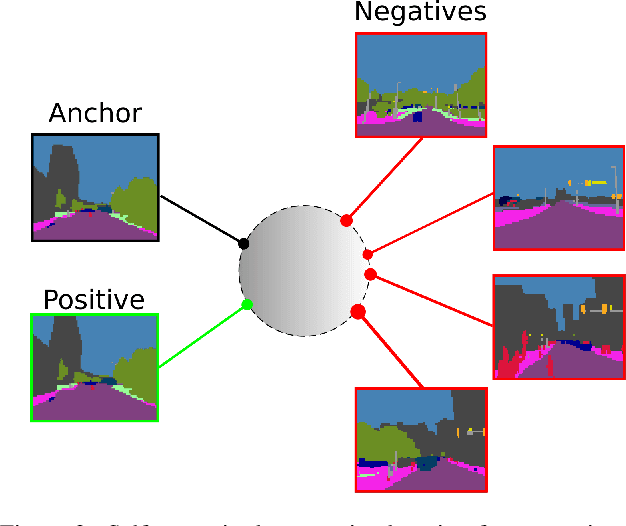
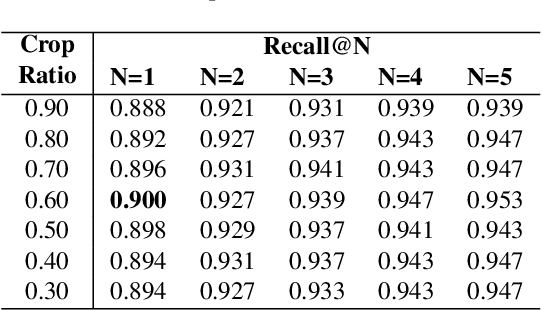
Any city-scale visual localization system has to overcome long-term appearance changes, such as varying illumination conditions or seasonal changes between query and database images. Since semantic content is more robust to such changes, we exploit semantic information to improve visual localization. In our scenario, the database consists of gnomonic views generated from panoramic images (e.g. Google Street View) and query images are collected with a standard field-of-view camera at a different time. To improve localization, we check the semantic similarity between query and database images, which is not trivial since the position and viewpoint of the cameras do not exactly match. To learn similarity, we propose training a CNN in a self-supervised fashion with contrastive learning on a dataset of semantically segmented images. With experiments we showed that this semantic similarity estimation approach works better than measuring the similarity at pixel-level. Finally, we used the semantic similarity scores to verify the retrievals obtained by a state-of-the-art visual localization method and observed that contrastive learning-based pose verification increases top-1 recall value to 0.90 which corresponds to a 2% improvement.
Monocular Vision-based Prediction of Cut-in Maneuvers with LSTM Networks
Mar 21, 2022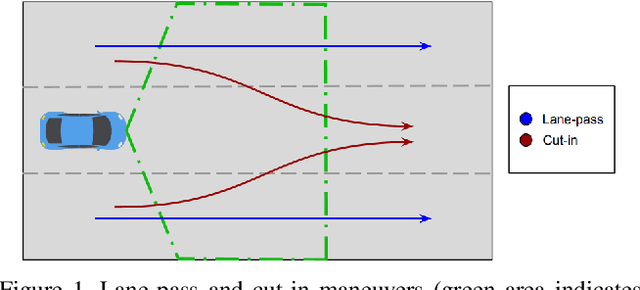
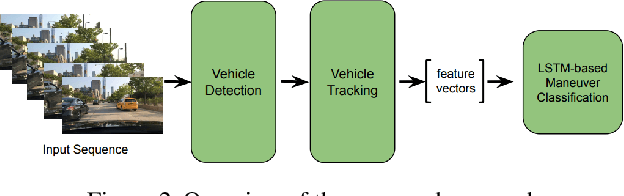
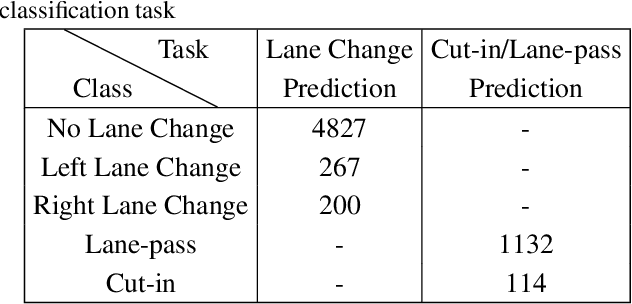
Advanced driver assistance and automated driving systems should be capable of predicting and avoiding dangerous situations. This study proposes a method to predict potentially dangerous cut-in maneuvers happening in the ego lane. We follow a computer vision-based approach that only employs a single in-vehicle RGB camera, and we classify the target vehicle's maneuver based on the recent video frames. Our algorithm consists of a CNN-based vehicle detection and tracking step and an LSTM-based maneuver classification step. It is more computationally efficient than other vision-based methods since it exploits a small number of features for the classification step rather than feeding CNNs with RGB frames. We evaluated our approach on a publicly available driving dataset and a lane change detection dataset. We obtained 0.9585 accuracy with side-aware two-class (cut-in vs. lane-pass) classification models. Experiment results also reveal that our approach outperforms state-of-the-art approaches when used for lane change detection.
Training Semantic Descriptors for Image-Based Localization
Feb 02, 2022Vision based solutions for the localization of vehicles have become popular recently. We employ an image retrieval based visual localization approach. The database images are kept with GPS coordinates and the location of the retrieved database image serves as an approximate position of the query image. We show that localization can be performed via descriptors solely extracted from semantically segmented images. It is reliable especially when the environment is subjected to severe illumination and seasonal changes. Our experiments reveal that the localization performance of a semantic descriptor can increase up to the level of state-of-the-art RGB image based methods.
Reduced egomotion estimation drift using omnidirectional views
Dec 01, 2013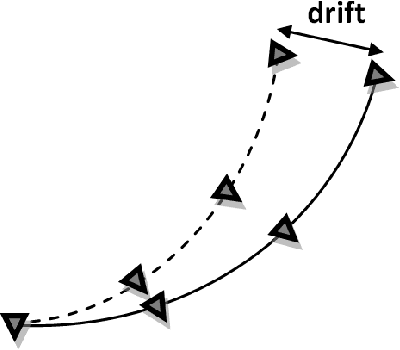
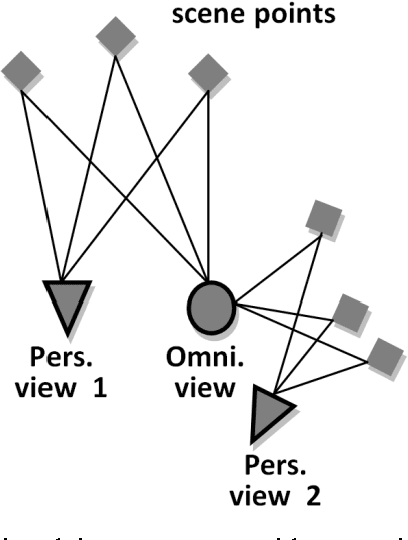
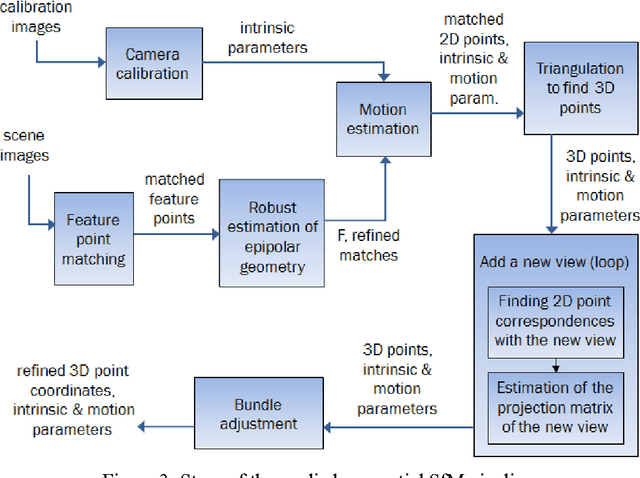
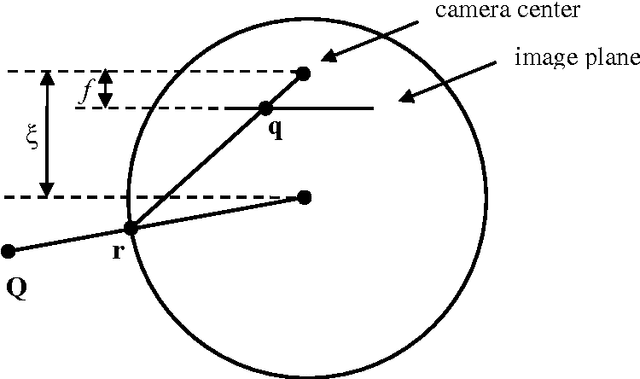
Estimation of camera motion from a given image sequence becomes degraded as the length of the sequence increases. In this letter, this phenomenon is demonstrated and an approach to increase the estimation accuracy is proposed. The proposed method uses an omnidirectional camera in addition to the perspective one and takes advantage of its enlarged view by exploiting the correspondences between the omnidirectional and perspective images. Simulated and real image experiments show that the proposed approach improves the estimation accuracy.
* Another publisher does not want this article to be shared at arxiv.org in order to publish it