 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Pose Verification for Outdoor Visual Localization with Self-supervised Contrastive Learning
Mar 31, 2022
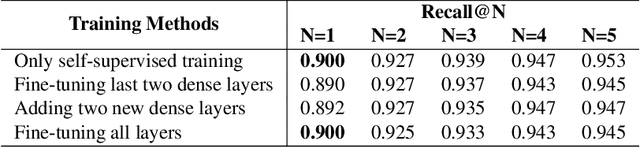
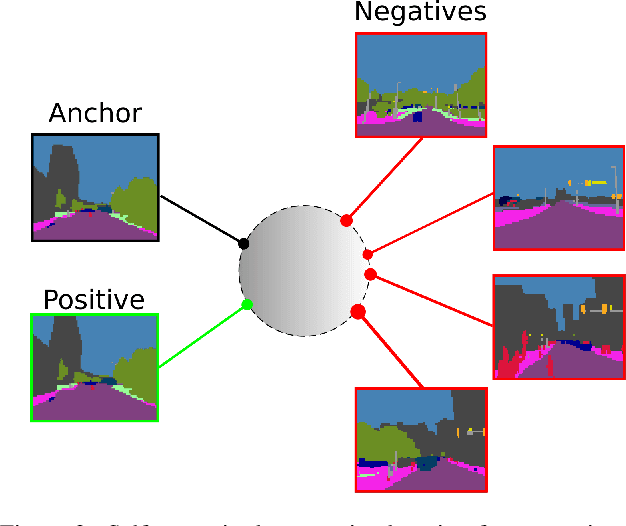
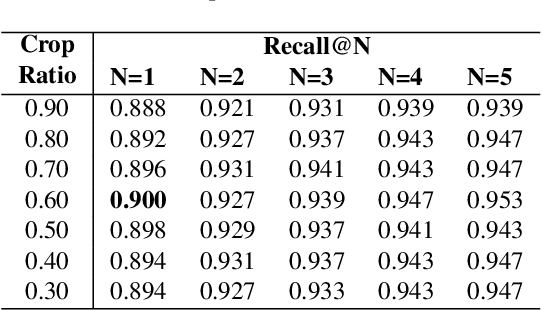
Any city-scale visual localization system has to overcome long-term appearance changes, such as varying illumination conditions or seasonal changes between query and database images. Since semantic content is more robust to such changes, we exploit semantic information to improve visual localization. In our scenario, the database consists of gnomonic views generated from panoramic images (e.g. Google Street View) and query images are collected with a standard field-of-view camera at a different time. To improve localization, we check the semantic similarity between query and database images, which is not trivial since the position and viewpoint of the cameras do not exactly match. To learn similarity, we propose training a CNN in a self-supervised fashion with contrastive learning on a dataset of semantically segmented images. With experiments we showed that this semantic similarity estimation approach works better than measuring the similarity at pixel-level. Finally, we used the semantic similarity scores to verify the retrievals obtained by a state-of-the-art visual localization method and observed that contrastive learning-based pose verification increases top-1 recall value to 0.90 which corresponds to a 2% improvement.