 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Variable Occurrence-Centric Framework for Inconsistency Handling (Extended Version)
Dec 17, 2024In this paper, we introduce a syntactic framework for analyzing and handling inconsistencies in propositional bases. Our approach focuses on examining the relationships between variable occurrences within conflicts. We propose two dual concepts: Minimal Inconsistency Relation (MIR) and Maximal Consistency Relation (MCR). Each MIR is a minimal equivalence relation on variable occurrences that results in inconsistency, while each MCR is a maximal equivalence relation designed to prevent inconsistency. Notably, MIRs capture conflicts overlooked by minimal inconsistent subsets. Using MCRs, we develop a series of non-explosive inference relations. The main strategy involves restoring consistency by modifying the propositional base according to each MCR, followed by employing the classical inference relation to derive conclusions. Additionally, we propose an unusual semantics that assigns truth values to variable occurrences instead of the variables themselves. The associated inference relations are established through Boolean interpretations compatible with the occurrence-based models.
On SAT Models Enumeration in Itemset Mining
Jun 08, 2015
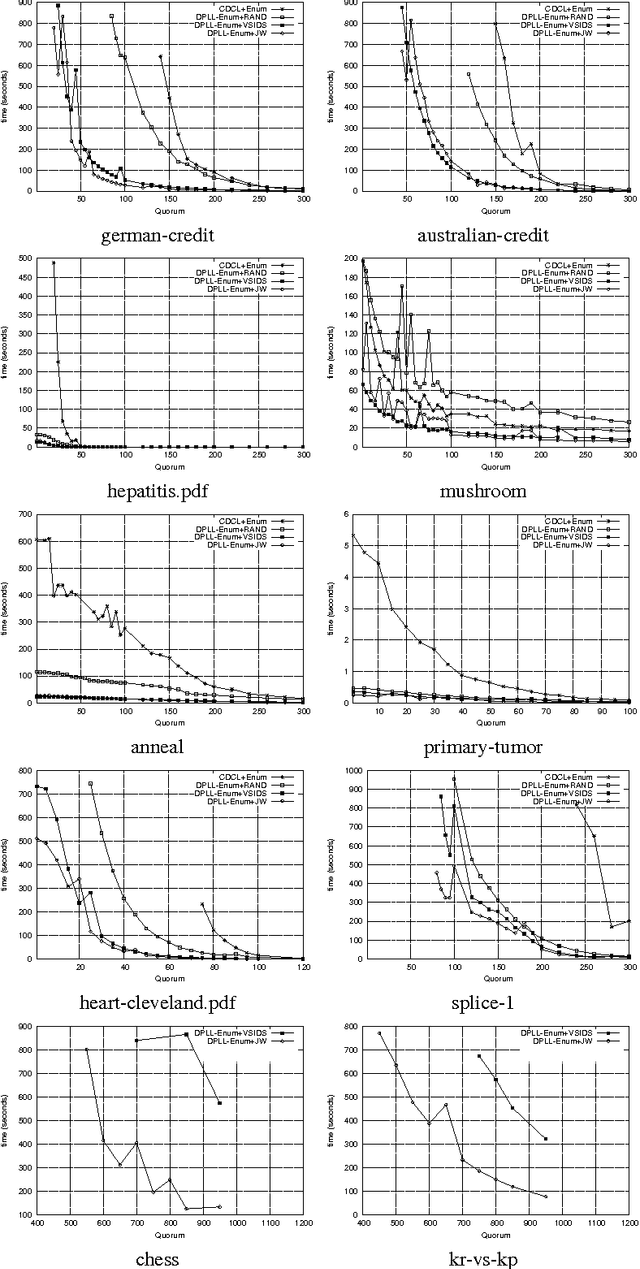
Frequent itemset mining is an essential part of data analysis and data mining. Recent works propose interesting SAT-based encodings for the problem of discovering frequent itemsets. Our aim in this work is to define strategies for adapting SAT solvers to such encodings in order to improve models enumeration. In this context, we deeply study the effects of restart, branching heuristics and clauses learning. We then conduct an experimental evaluation on SAT-Based itemset mining instances to show how SAT solvers can be adapted to obtain an efficient SAT model enumerator.
On the measure of conflicts: A MUS-Decomposition Based Framework
Jun 01, 2014
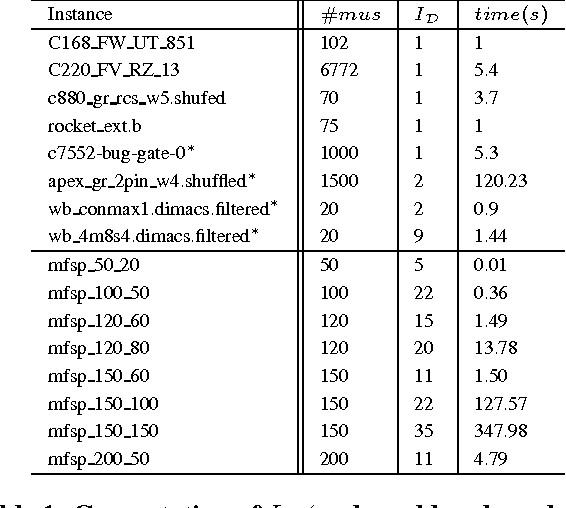
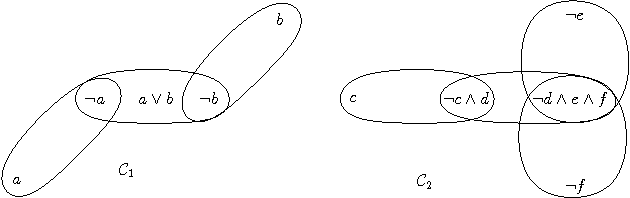
Measuring inconsistency is viewed as an important issue related to handling inconsistencies. Good measures are supposed to satisfy a set of rational properties. However, defining sound properties is sometimes problematic. In this paper, we emphasize one such property, named Decomposability, rarely discussed in the literature due to its modeling difficulties. To this end, we propose an independent decomposition which is more intuitive than existing proposals. To analyze inconsistency in a more fine-grained way, we introduce a graph representation of a knowledge base and various MUSdecompositions. One particular MUS-decomposition, named distributable MUS-decomposition leads to an interesting partition of inconsistencies in a knowledge base such that multiple experts can check inconsistencies in parallel, which is impossible under existing measures. Such particular MUSdecomposition results in an inconsistency measure that satisfies a number of desired properties. Moreover, we give an upper bound complexity of the measure that can be computed using 0/1 linear programming or Min Cost Satisfiability problems, and conduct preliminary experiments to show its feasibility.
Revisiting the Learned Clauses Database Reduction Strategies
Feb 09, 2014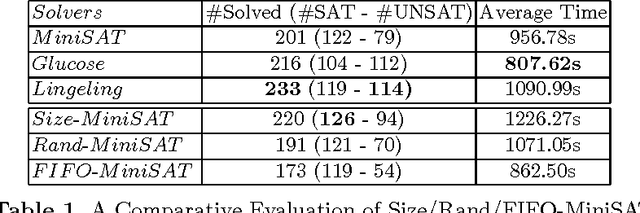

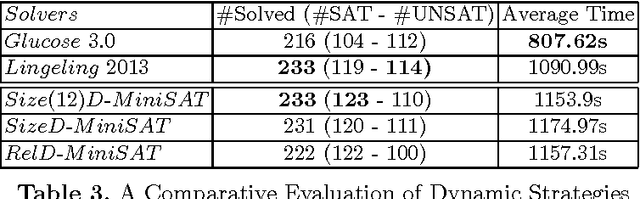

In this paper, we revisit an important issue of CDCL-based SAT solvers, namely the learned clauses database management policies. Our motivation takes its source from a simple observation on the remarkable performances of both random and size-bounded reduction strategies. We first derive a simple reduction strategy, called Size-Bounded Randomized strategy (in short SBR), that combines maintaing short clauses (of size bounded by k), while deleting randomly clauses of size greater than k. The resulting strategy outperform the state-of-the-art, namely the LBD based one, on SAT instances taken from the last SAT competition. Reinforced by the interest of keeping short clauses, we propose several new dynamic variants, and we discuss their performances.
A Mining-Based Compression Approach for Constraint Satisfaction Problems
May 14, 2013

In this paper, we propose an extension of our Mining for SAT framework to Constraint satisfaction Problem (CSP). We consider n-ary extensional constraints (table constraints). Our approach aims to reduce the size of the CSP by exploiting the structure of the constraints graph and of its associated microstructure. More precisely, we apply itemset mining techniques to search for closed frequent itemsets on these two representation. Using Tseitin extension, we rewrite the whole CSP to another compressed CSP equivalent with respect to satisfiability. Our approach contrast with previous proposed approach by Katsirelos and Walsh, as we do not change the structure of the constraints.
Extending Modern SAT Solvers for Enumerating All Models
May 06, 2013In this paper, we address the problem of enumerating all models of a Boolean formula in conjunctive normal form (CNF). We propose an extension of CDCL-based SAT solvers to deal with this fundamental problem. Then, we provide an experimental evaluation of our proposed SAT model enumeration algorithms on both satisfiable SAT instances taken from the last SAT challenge and on instances from the SAT-based encoding of sequence mining problems.
Mining to Compact CNF Propositional Formulae
Apr 16, 2013
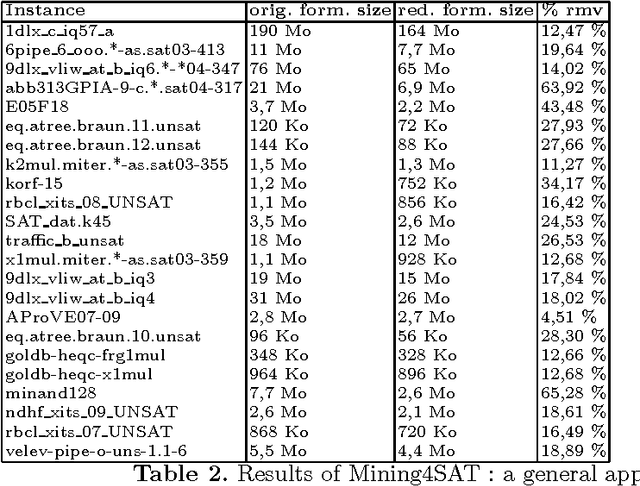
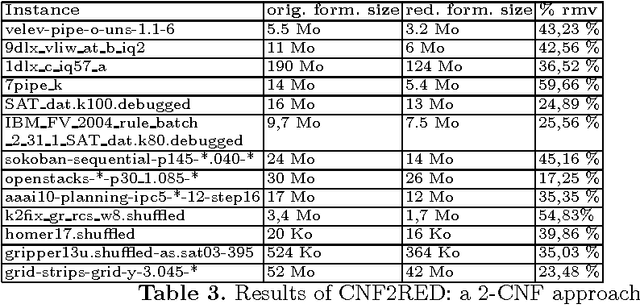
In this paper, we propose a first application of data mining techniques to propositional satisfiability. Our proposed Mining4SAT approach aims to discover and to exploit hidden structural knowledge for reducing the size of propositional formulae in conjunctive normal form (CNF). Mining4SAT combines both frequent itemset mining techniques and Tseitin's encoding for a compact representation of CNF formulae. The experiments of our Mining4SAT approach show interesting reductions of the sizes of many application instances taken from the last SAT competitions.