 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Pattern Loss based Diversified Attention Network for Cross-Modal Retrieval
Jun 25, 2021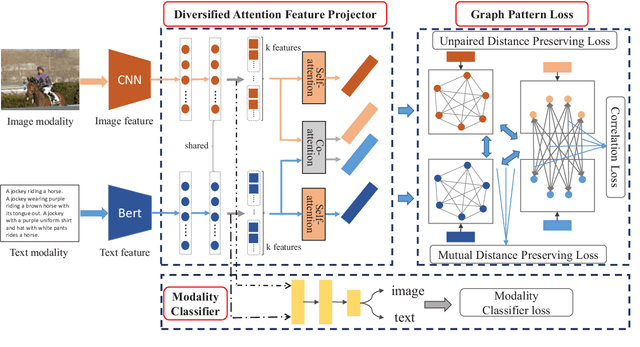
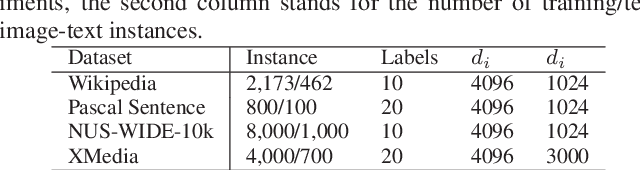
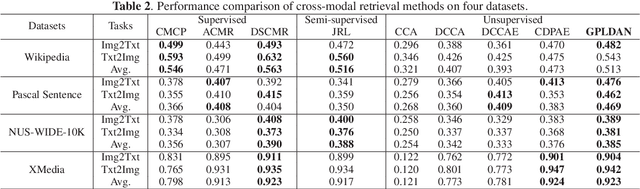
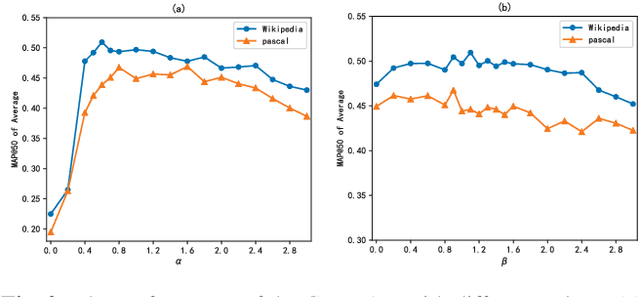
Cross-modal retrieval aims to enable flexible retrieval experience by combining multimedia data such as image, video, text, and audio. One core of unsupervised approaches is to dig the correlations among different object representations to complete satisfied retrieval performance without requiring expensive labels. In this paper, we propose a Graph Pattern Loss based Diversified Attention Network(GPLDAN) for unsupervised cross-modal retrieval to deeply analyze correlations among representations. First, we propose a diversified attention feature projector by considering the interaction between different representations to generate multiple representations of an instance. Then, we design a novel graph pattern loss to explore the correlations among different representations, in this graph all possible distances between different representations are considered. In addition, a modality classifier is added to explicitly declare the corresponding modalities of features before fusion and guide the network to enhance discrimination ability. We test GPLDAN on four public datasets. Compared with the state-of-the-art cross-modal retrieval methods, the experimental results demonstrate the performance and competitiveness of GPLDAN.
* 5 pages, 3 figures
Divide-and-conquer methods for big data analysis
Feb 22, 2021In the context of big data analysis, the divide-and-conquer methodology refers to a multiple-step process: first splitting a data set into several smaller ones; then analyzing each set separately; finally combining results from each analysis together. This approach is effective in handling large data sets that are unsuitable to be analyzed entirely by a single computer due to limits either from memory storage or computational time. The combined results will provide a statistical inference which is similar to the one from analyzing the entire data set. This article reviews some recently developments of divide-and-conquer methods in a variety of settings, including combining based on parametric, semiparametric and nonparametric models, online sequential updating methods, among others. Theoretical development on the efficiency of the divide-and-conquer methods is also discussed.
Feature Fusion Encoder Decoder Network For Automatic Liver Lesion Segmentation
Mar 28, 2019
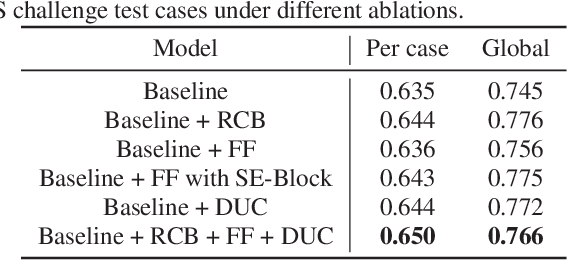


Liver lesion segmentation is a difficult yet critical task for medical image analysis. Recently, deep learning based image segmentation methods have achieved promising performance, which can be divided into three categories: 2D, 2.5D and 3D, based on the dimensionality of the models. However, 2.5D and 3D methods can have very high complexity and 2D methods may not perform satisfactorily. To obtain competitive performance with low complexity, in this paper, we propose a Feature-fusion Encoder-Decoder Network (FED-Net) based 2D segmentation model to tackle the challenging problem of liver lesion segmentation from CT images. Our feature fusion method is based on the attention mechanism, which fuses high-level features carrying semantic information with low-level features having image details. Additionally, to compensate for the information loss during the upsampling process, a dense upsampling convolution and a residual convolutional structure are proposed. We tested our method on the dataset of MICCAI 2017 Liver Tumor Segmentation (LiTS) Challenge and achieved competitive results compared with other state-of-the-art methods.