 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse Attention for Salient Object Detection
Jul 26, 2018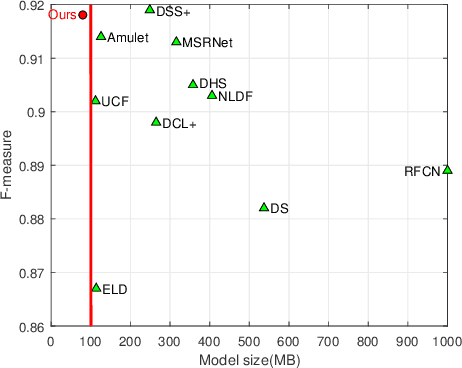

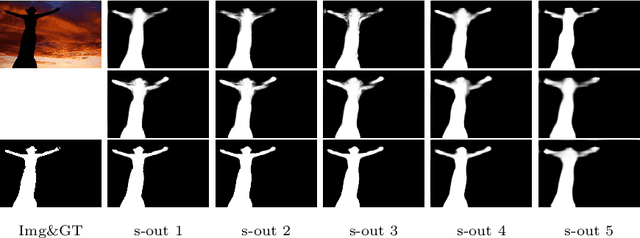
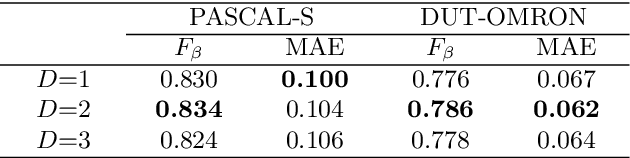
Benefit from the quick development of deep learning techniques, salient object detection has achieved remarkable progresses recently. However, there still exists following two major challenges that hinder its application in embedded devices, low resolution output and heavy model weight. To this end, this paper presents an accurate yet compact deep network for efficient salient object detection. More specifically, given a coarse saliency prediction in the deepest layer, we first employ residual learning to learn side-output residual features for saliency refinement, which can be achieved with very limited convolutional parameters while keep accuracy. Secondly, we further propose reverse attention to guide such side-output residual learning in a top-down manner. By erasing the current predicted salient regions from side-output features, the network can eventually explore the missing object parts and details which results in high resolution and accuracy. Experiments on six benchmark datasets demonstrate that the proposed approach compares favorably against state-of-the-art methods, and with advantages in terms of simplicity, efficiency (45 FPS) and model size (81 MB).
Saliency Detection for Improving Object Proposals
Oct 17, 2016Object proposals greatly benefit object detection task in recent state-of-the-art works. However, the existing object proposals usually have low localization accuracy at high intersection over union threshold. To address it, we apply saliency detection to each bounding box to improve their quality in this paper. We first present a geodesic saliency detection method in contour, which is designed to find closed contours. Then, we apply it to each candidate box with multi-sizes, and refined boxes can be easily produced in the obtained saliency maps which are further used to calculate saliency scores for proposal ranking. Experiments on PASCAL VOC 2007 test dataset demonstrate the proposed refinement approach can greatly improve existing models.