 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Communication in Dynamic Channel Scenarios: Collaborative Optimization of Dual-Pipeline Joint Source-Channel Coding and Personalized Federated Learning
Mar 18, 2025Semantic communication is designed to tackle issues like bandwidth constraints and high latency in communication systems. However, in complex network topologies with multiple users, the enormous combinations of client data and channel state information (CSI) pose significant challenges for existing semantic communication architectures. To improve the generalization ability of semantic communication models in complex scenarios while meeting the personalized needs of each user in their local environments, we propose a novel personalized federated learning framework with dual-pipeline joint source-channel coding based on channel awareness model (PFL-DPJSCCA). Within this framework, we present a method that achieves zero optimization gap for non-convex loss functions. Experiments conducted under varying SNR distributions validate the outstanding performance of our framework across diverse datasets.
Sequential Federated Learning in Hierarchical Architecture on Non-IID Datasets
Aug 19, 2024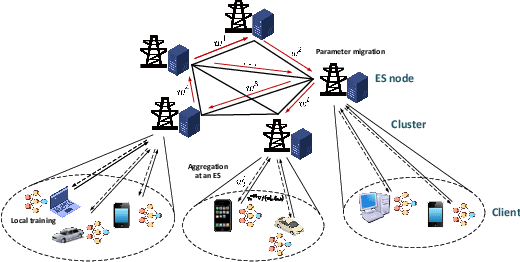
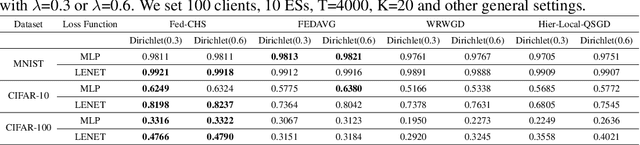
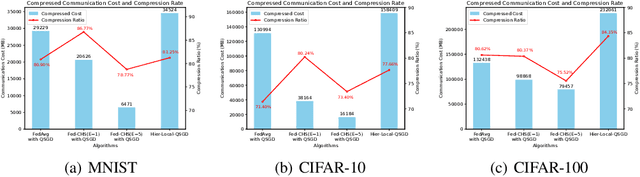
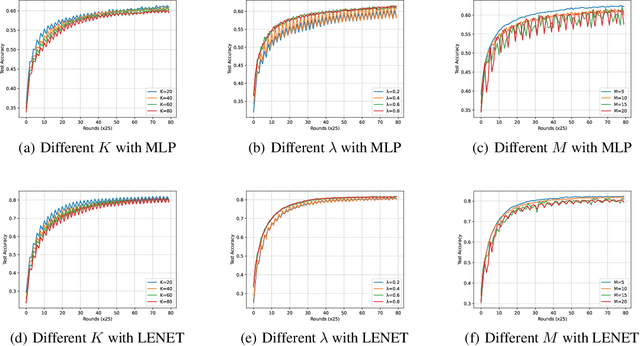
In a real federated learning (FL) system, communication overhead for passing model parameters between the clients and the parameter server (PS) is often a bottleneck. Hierarchical federated learning (HFL) that poses multiple edge servers (ESs) between clients and the PS can partially alleviate communication pressure but still needs the aggregation of model parameters from multiple ESs at the PS. To further reduce communication overhead, we bring sequential FL (SFL) into HFL for the first time, which removes the central PS and enables the model training to be completed only through passing the global model between two adjacent ESs for each iteration, and propose a novel algorithm adaptive to such a combinational framework, referred to as Fed-CHS. Convergence results are derived for strongly convex and non-convex loss functions under various data heterogeneity setups, which show comparable convergence performance with the algorithms for HFL or SFL solely. Experimental results provide evidence of the superiority of our proposed Fed-CHS on both communication overhead saving and test accuracy over baseline methods.
Byzantine-resilient Federated Learning Employing Normalized Gradients on Non-IID Datasets
Aug 18, 2024



In practical federated learning (FL) systems, the presence of malicious Byzantine attacks and data heterogeneity often introduces biases into the learning process. However, existing Byzantine-robust methods typically only achieve a compromise between adaptability to different loss function types (including both strongly convex and non-convex) and robustness to heterogeneous datasets, but with non-zero optimality gap. Moreover, this compromise often comes at the cost of high computational complexity for aggregation, which significantly slows down the training speed. To address this challenge, we propose a federated learning approach called Federated Normalized Gradients Algorithm (Fed-NGA). Fed-NGA simply normalizes the uploaded local gradients to be unit vectors before aggregation, achieving a time complexity of $\mathcal{O}(pM)$, where $p$ represents the dimension of model parameters and $M$ is the number of participating clients. This complexity scale achieves the best level among all the existing Byzantine-robust methods. Furthermore, through rigorous proof, we demonstrate that Fed-NGA transcends the trade-off between adaptability to loss function type and data heterogeneity and the limitation of non-zero optimality gap in existing literature. Specifically, Fed-NGA can adapt to both non-convex loss functions and non-IID datasets simultaneously, with zero optimality gap at a rate of $\mathcal{O} (1/T^{\frac{1}{2} - \delta})$, where T is the iteration number and $\delta \in (0,\frac{1}{2})$. In cases where the loss function is strongly convex, the zero optimality gap achieving rate can be improved to be linear. Experimental results provide evidence of the superiority of our proposed Fed-NGA on time complexity and convergence performance over baseline methods.
Byzantine-resilient Federated Learning With Adaptivity to Data Heterogeneity
Mar 27, 2024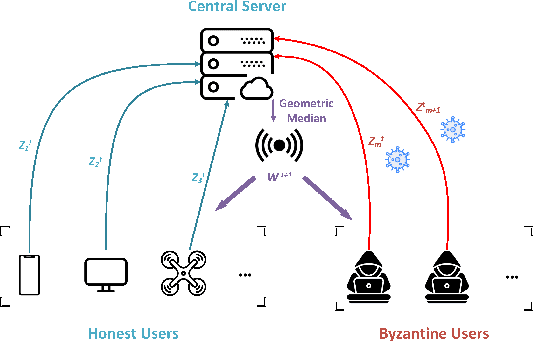
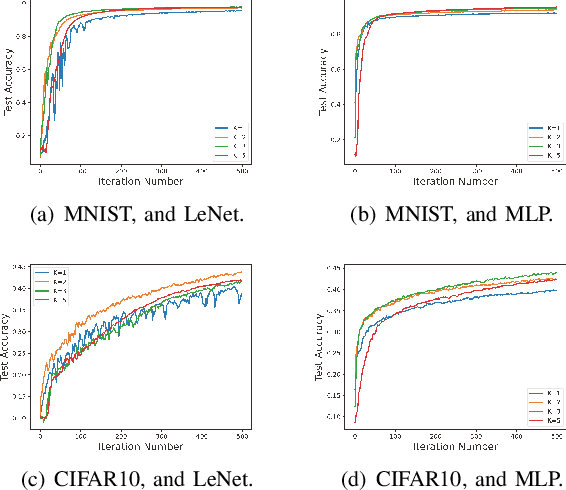
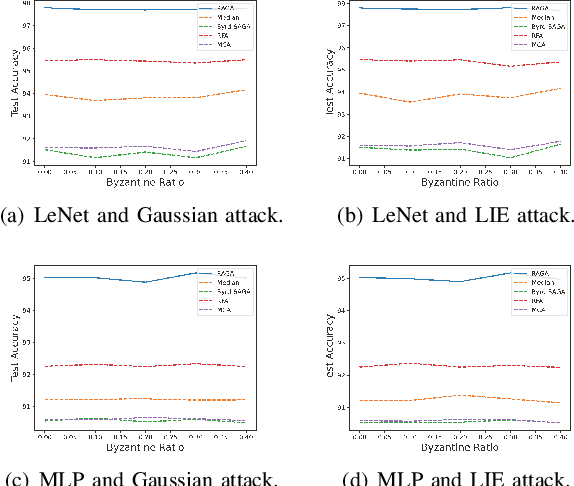
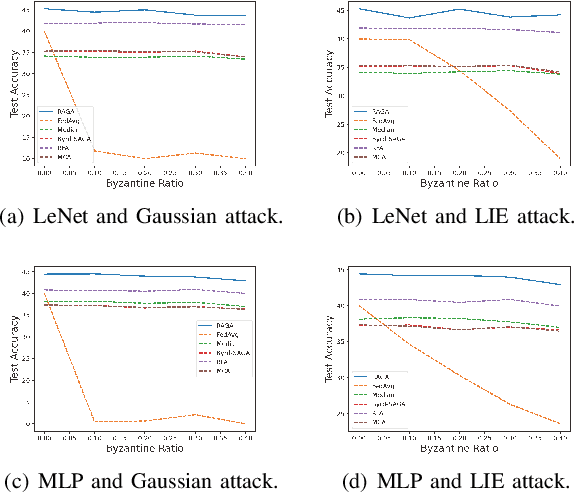
This paper deals with federated learning (FL) in the presence of malicious Byzantine attacks and data heterogeneity. A novel Robust Average Gradient Algorithm (RAGA) is proposed, which leverages the geometric median for aggregation and can freely select the round number for local updating. Different from most existing resilient approaches, which perform convergence analysis based on strongly-convex loss function or homogeneously distributed dataset, we conduct convergence analysis for not only strongly-convex but also non-convex loss function over heterogeneous dataset. According to our theoretical analysis, as long as the fraction of dataset from malicious users is less than half, RAGA can achieve convergence at rate $\mathcal{O}({1}/{T^{2/3- \delta}})$ where $T$ is the iteration number and $\delta \in (0, 2/3)$ for non-convex loss function, and at linear rate for strongly-convex loss function. Moreover, stationary point or global optimal solution is proved to obtainable as data heterogeneity vanishes. Experimental results corroborate the robustness of RAGA to Byzantine attacks and verifies the advantage of RAGA over baselines on convergence performance under various intensity of Byzantine attacks, for heterogeneous dataset.