 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-aware Adaptive Structured Pruning for Large Language Models
Mar 08, 2025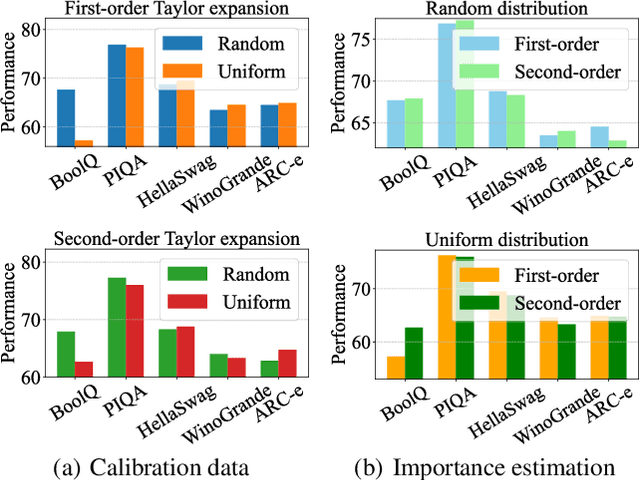
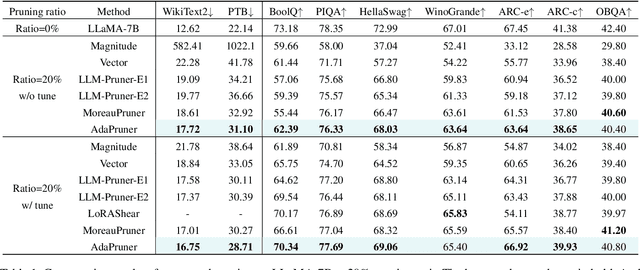
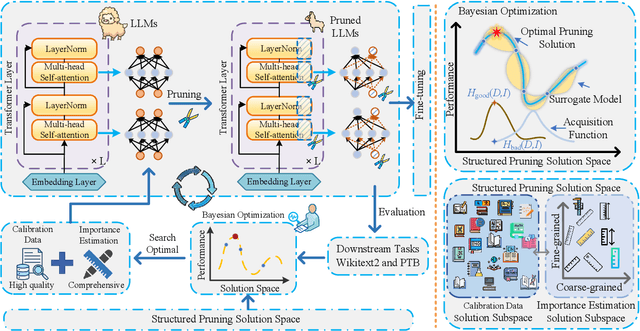
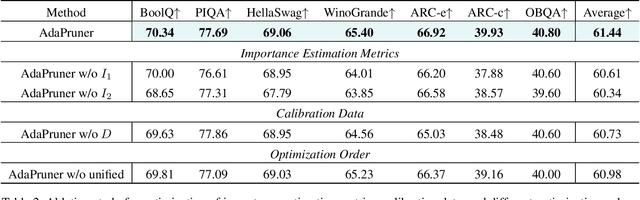
Large language models (LLMs) have achieved outstanding performance in natural language processing, but enormous model sizes and high computational costs limit their practical deployment. Structured pruning can effectively reduce the resource demands for deployment by removing redundant model parameters. However, the randomly selected calibration data and fixed single importance estimation metrics in existing structured pruning methods lead to degraded performance of pruned models. This study introduces AdaPruner, a sample-aware adaptive structured pruning framework for LLMs, aiming to optimize the calibration data and importance estimation metrics in the structured pruning process. Specifically, AdaPruner effectively removes redundant parameters from LLMs by constructing a structured pruning solution space and then employing Bayesian optimization to adaptively search for the optimal calibration data and importance estimation metrics. Experimental results show that the AdaPruner outperforms existing structured pruning methods on a family of LLMs with varying pruning ratios, demonstrating its applicability and robustness. Remarkably, at a 20\% pruning ratio, the model pruned with AdaPruner maintains 97\% of the performance of the unpruned model.
Data-Free Black-Box Federated Learning via Zeroth-Order Gradient Estimation
Mar 08, 2025



Federated learning (FL) enables decentralized clients to collaboratively train a global model under the orchestration of a central server without exposing their individual data. However, the iterative exchange of model parameters between the server and clients imposes heavy communication burdens, risks potential privacy leakage, and even precludes collaboration among heterogeneous clients. Distillation-based FL tackles these challenges by exchanging low-dimensional model outputs rather than model parameters, yet it highly relies on a task-relevant auxiliary dataset that is often not available in practice. Data-free FL attempts to overcome this limitation by training a server-side generator to directly synthesize task-specific data samples for knowledge transfer. However, the update rule of the generator requires clients to share on-device models for white-box access, which greatly compromises the advantages of distillation-based FL. This motivates us to explore a data-free and black-box FL framework via Zeroth-order Gradient Estimation (FedZGE), which estimates the gradients after flowing through on-device models in a black-box optimization manner to complete the training of the generator in terms of fidelity, transferability, diversity, and equilibrium, without involving any auxiliary data or sharing any model parameters, thus combining the advantages of both distillation-based FL and data-free FL. Experiments on large-scale image classification datasets and network architectures demonstrate the superiority of FedZGE in terms of data heterogeneity, model heterogeneity, communication efficiency, and privacy protection.