 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-aware Adaptive Structured Pruning for Large Language Models
Paper and Code
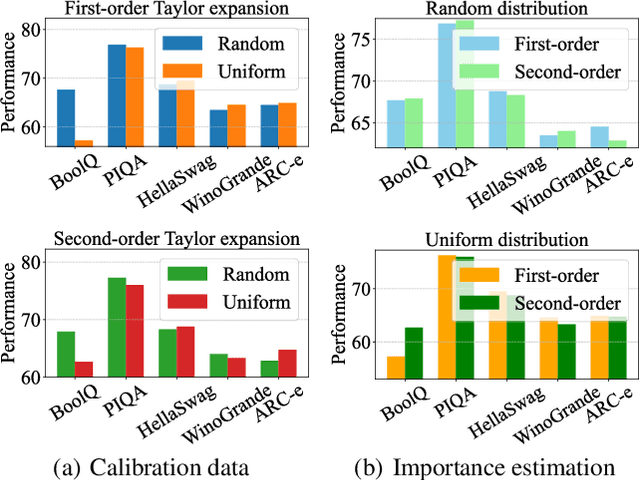
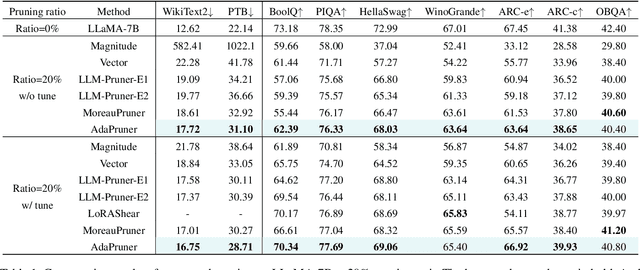
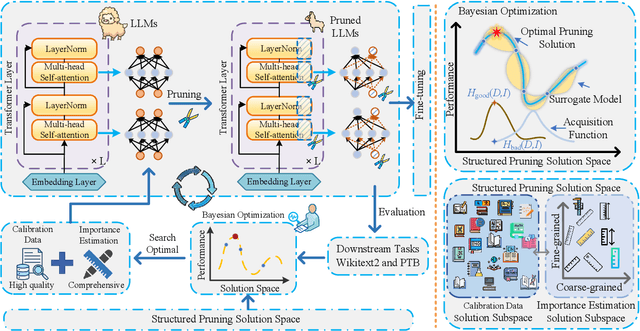
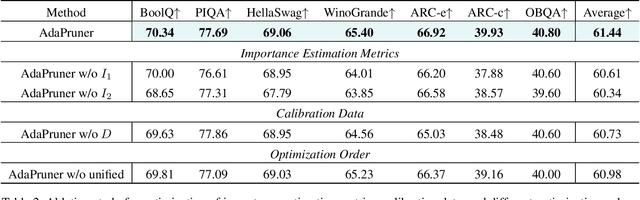
Large language models (LLMs) have achieved outstanding performance in natural language processing, but enormous model sizes and high computational costs limit their practical deployment. Structured pruning can effectively reduce the resource demands for deployment by removing redundant model parameters. However, the randomly selected calibration data and fixed single importance estimation metrics in existing structured pruning methods lead to degraded performance of pruned models. This study introduces AdaPruner, a sample-aware adaptive structured pruning framework for LLMs, aiming to optimize the calibration data and importance estimation metrics in the structured pruning process. Specifically, AdaPruner effectively removes redundant parameters from LLMs by constructing a structured pruning solution space and then employing Bayesian optimization to adaptively search for the optimal calibration data and importance estimation metrics. Experimental results show that the AdaPruner outperforms existing structured pruning methods on a family of LLMs with varying pruning ratios, demonstrating its applicability and robustness. Remarkably, at a 20\% pruning ratio, the model pruned with AdaPruner maintains 97\% of the performance of the unpruned model.