 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral vs. Long-Tailed Age Estimation: An Approach to Kill Two Birds with One Stone
Jul 19, 2023



Facial age estimation has received a lot of attention for its diverse application scenarios. Most existing studies treat each sample equally and aim to reduce the average estimation error for the entire dataset, which can be summarized as General Age Estimation. However, due to the long-tailed distribution prevalent in the dataset, treating all samples equally will inevitably bias the model toward the head classes (usually the adult with a majority of samples). Driven by this, some works suggest that each class should be treated equally to improve performance in tail classes (with a minority of samples), which can be summarized as Long-tailed Age Estimation. However, Long-tailed Age Estimation usually faces a performance trade-off, i.e., achieving improvement in tail classes by sacrificing the head classes. In this paper, our goal is to design a unified framework to perform well on both tasks, killing two birds with one stone. To this end, we propose a simple, effective, and flexible training paradigm named GLAE, which is two-fold. Our GLAE provides a surprising improvement on Morph II, reaching the lowest MAE and CMAE of 1.14 and 1.27 years, respectively. Compared to the previous best method, MAE dropped by up to 34%, which is an unprecedented improvement, and for the first time, MAE is close to 1 year old. Extensive experiments on other age benchmark datasets, including CACD, MIVIA, and Chalearn LAP 2015, also indicate that GLAE outperforms the state-of-the-art approaches significantly.
LAE : Long-tailed Age Estimation
Oct 25, 2021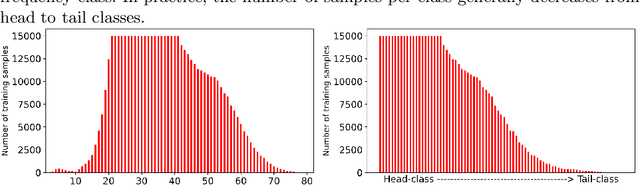


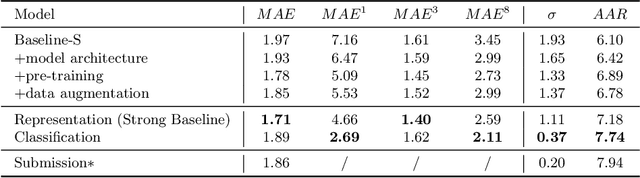
Facial age estimation is an important yet very challenging problem in computer vision. To improve the performance of facial age estimation, we first formulate a simple standard baseline and build a much strong one by collecting the tricks in pre-training, data augmentation, model architecture, and so on. Compared with the standard baseline, the proposed one significantly decreases the estimation errors. Moreover, long-tailed recognition has been an important topic in facial age datasets, where the samples often lack on the elderly and children. To train a balanced age estimator, we propose a two-stage training method named Long-tailed Age Estimation (LAE), which decouples the learning procedure into representation learning and classification. The effectiveness of our approach has been demonstrated on the dataset provided by organizers of Guess The Age Contest 2021.
Represent Items by Items: An Enhanced Representation of the Target Item for Recommendation
Apr 26, 2021



Item-based collaborative filtering (ICF) has been widely used in industrial applications such as recommender system and online advertising. It models users' preference on target items by the items they have interacted with. Recent models use methods such as attention mechanism and deep neural network to learn the user representation and scoring function more accurately. However, despite their effectiveness, such models still overlook a problem that performance of ICF methods heavily depends on the quality of item representation especially the target item representation. In fact, due to the long-tail distribution in the recommendation, most item embeddings can not represent the semantics of items accurately and thus degrade the performance of current ICF methods. In this paper, we propose an enhanced representation of the target item which distills relevant information from the co-occurrence items. We design sampling strategies to sample fix number of co-occurrence items for the sake of noise reduction and computational cost. Considering the different importance of sampled items to the target item, we apply attention mechanism to selectively adopt the semantic information of the sampled items. Our proposed Co-occurrence based Enhanced Representation model (CER) learns the scoring function by a deep neural network with the attentive user representation and fusion of raw representation and enhanced representation of target item as input. With the enhanced representation, CER has stronger representation power for the tail items compared to the state-of-the-art ICF methods. Extensive experiments on two public benchmarks demonstrate the effectiveness of CER.