 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStress-Testing Long-Context Language Models with Lifelong ICL and Task Haystack
Jul 23, 2024We introduce Lifelong ICL, a problem setting that challenges long-context language models (LMs) to learn from a sequence of language tasks through in-context learning (ICL). We further introduce Task Haystack, an evaluation suite dedicated to assessing and diagnosing how long-context LMs utilizes contexts in Lifelong ICL. When given a task instruction and test inputs, long-context LMs are expected to leverage the relevant demonstrations in the Lifelong ICL prompt, avoid distraction and interference from other tasks, and achieve test accuracies that are not significantly worse than the Single-task ICL baseline. Task Haystack draws inspiration from the widely-adopted "needle-in-a-haystack" (NIAH) evaluation, but presents new and unique challenges. It demands that models (1) utilize the contexts with deeper understanding, rather than resorting to simple copying and pasting; (2) navigate through long streams of evolving topics and tasks, which closely approximates the complexities of real-world usage of long-context LMs. Additionally, Task Haystack inherits the controllability aspect of NIAH, providing model developers with tools and visualizations to identify model vulnerabilities effectively. We benchmark 12 long-context LMs using Task Haystack. We find that state-of-the-art closed models such as GPT-4o still struggle in this setting, failing 15% of the cases on average, while all open-weight models we evaluate further lack behind by a large margin, failing up to 61% of the cases. In our controlled analysis, we identify factors such as distraction and recency bias as contributors to these failure cases. Further, we observe declines in performance when task instructions are paraphrased at test time or when ICL demonstrations are repeated excessively, raising concerns about the robustness, instruction understanding, and true context utilization of current long-context LMs.
Boosting Inference Efficiency: Unleashing the Power of Parameter-Shared Pre-trained Language Models
Oct 19, 2023

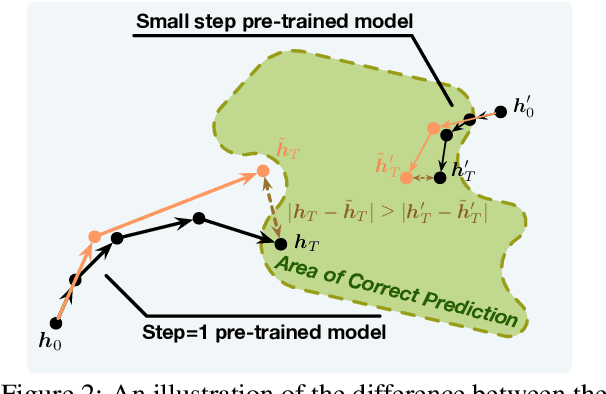

Parameter-shared pre-trained language models (PLMs) have emerged as a successful approach in resource-constrained environments, enabling substantial reductions in model storage and memory costs without significant performance compromise. However, it is important to note that parameter sharing does not alleviate computational burdens associated with inference, thus impeding its practicality in situations characterized by limited stringent latency requirements or computational resources. Building upon neural ordinary differential equations (ODEs), we introduce a straightforward technique to enhance the inference efficiency of parameter-shared PLMs. Additionally, we propose a simple pre-training technique that leads to fully or partially shared models capable of achieving even greater inference acceleration. The experimental results demonstrate the effectiveness of our methods on both autoregressive and autoencoding PLMs, providing novel insights into more efficient utilization of parameter-shared models in resource-constrained settings.