 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Policy Gradient with Variance Reduction in Multi-Agent Reinforcement Learning
Nov 30, 2021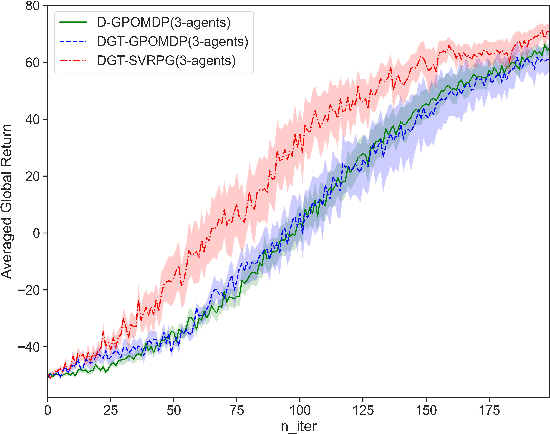
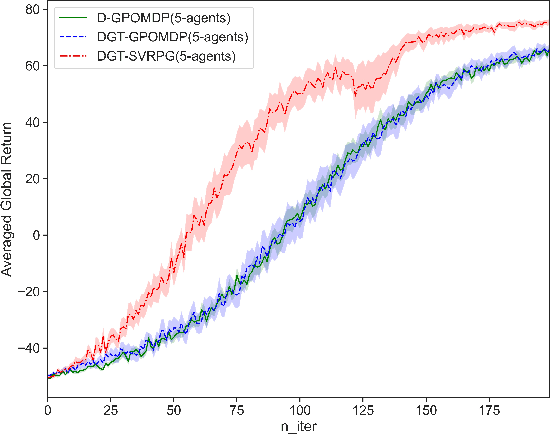
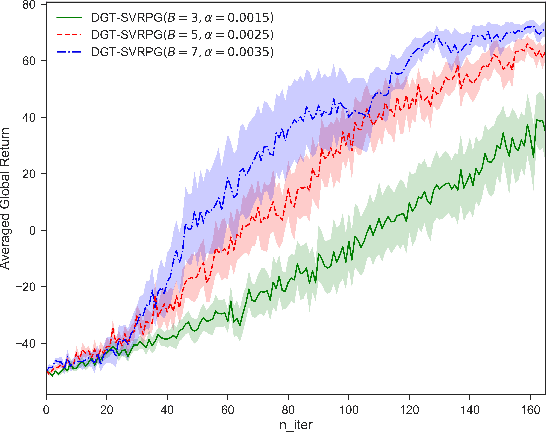
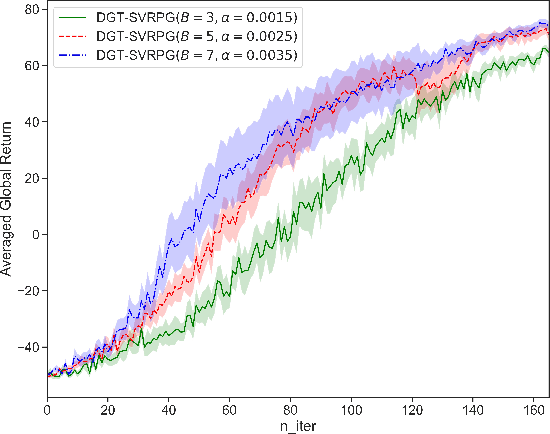
This paper studies a distributed policy gradient in collaborative multi-agent reinforcement learning (MARL), where agents over a communication network aim to find the optimal policy to maximize the average of all agents' local returns. Due to the non-concave performance function of policy gradient, the existing distributed stochastic optimization methods for convex problems cannot be directly used for policy gradient in MARL. This paper proposes a distributed policy gradient with variance reduction and gradient tracking to address the high variances of policy gradient, and utilizes importance weight to solve the non-stationary problem in the sampling process. We then provide an upper bound on the mean-squared stationary gap, which depends on the number of iterations, the mini-batch size, the epoch size, the problem parameters, and the network topology. We further establish the sample and communication complexity to obtain an $\epsilon$-approximate stationary point. Numerical experiments on the control problem in MARL are performed to validate the effectiveness of the proposed algorithm.
Active Crowd Counting with Limited Supervision
Jul 14, 2020
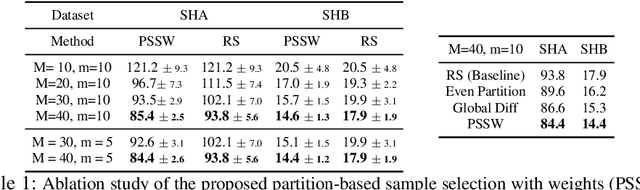
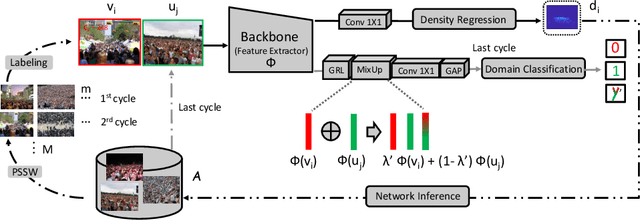

To learn a reliable people counter from crowd images, head center annotations are normally required. Annotating head centers is however a laborious and tedious process in dense crowds. In this paper, we present an active learning framework which enables accurate crowd counting with limited supervision: given a small labeling budget, instead of randomly selecting images to annotate, we first introduce an active labeling strategy to annotate the most informative images in the dataset and learn the counting model upon them. The process is repeated such that in every cycle we select the samples that are diverse in crowd density and dissimilar to previous selections. In the last cycle when the labeling budget is met, the large amount of unlabeled data are also utilized: a distribution classifier is introduced to align the labeled data with unlabeled data; furthermore, we propose to mix up the distribution labels and latent representations of data in the network to particularly improve the distribution alignment in-between training samples. We follow the popular density estimation pipeline for crowd counting. Extensive experiments are conducted on standard benchmarks i.e. ShanghaiTech, UCF CC 50, MAll, TRANCOS, and DCC. By annotating limited number of images (e.g. 10% of the dataset), our method reaches levels of performance not far from the state of the art which utilize full annotations of the dataset.