 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Policy Gradient with Variance Reduction in Multi-Agent Reinforcement Learning
Paper and Code
Nov 30, 2021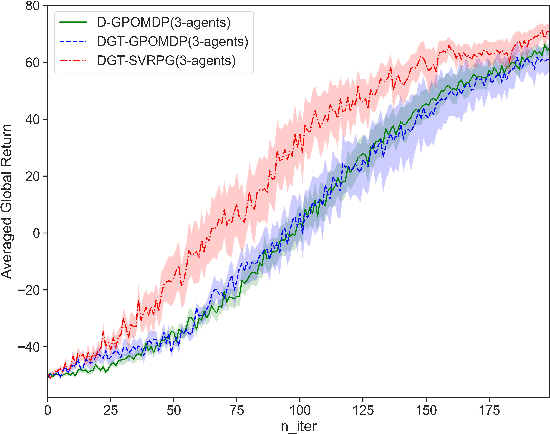
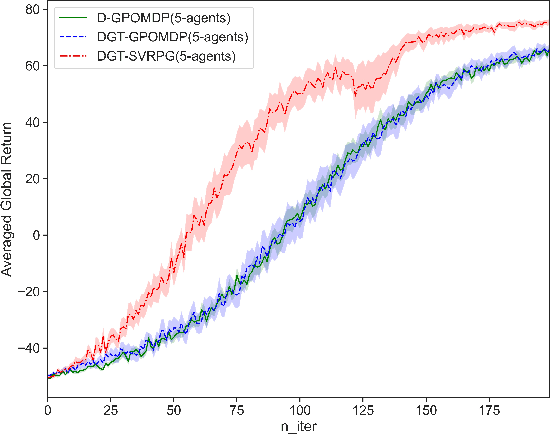
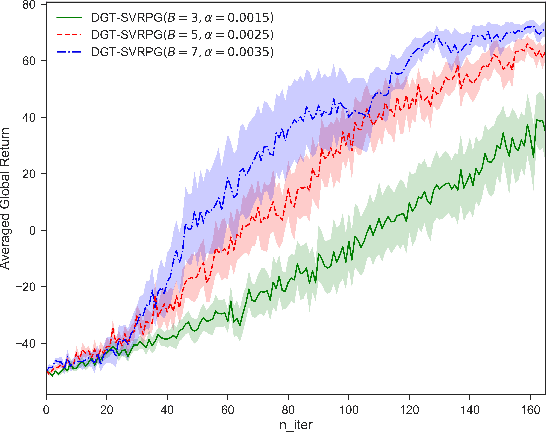
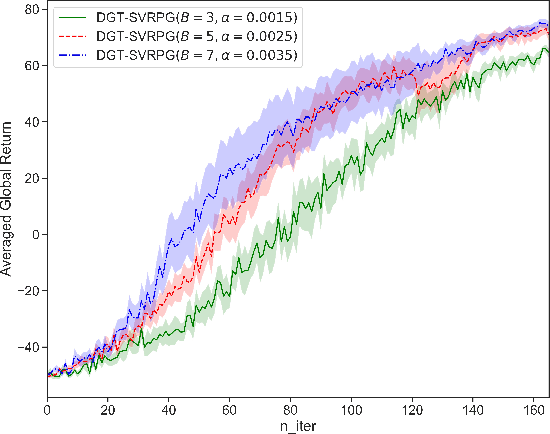
This paper studies a distributed policy gradient in collaborative multi-agent reinforcement learning (MARL), where agents over a communication network aim to find the optimal policy to maximize the average of all agents' local returns. Due to the non-concave performance function of policy gradient, the existing distributed stochastic optimization methods for convex problems cannot be directly used for policy gradient in MARL. This paper proposes a distributed policy gradient with variance reduction and gradient tracking to address the high variances of policy gradient, and utilizes importance weight to solve the non-stationary problem in the sampling process. We then provide an upper bound on the mean-squared stationary gap, which depends on the number of iterations, the mini-batch size, the epoch size, the problem parameters, and the network topology. We further establish the sample and communication complexity to obtain an $\epsilon$-approximate stationary point. Numerical experiments on the control problem in MARL are performed to validate the effectiveness of the proposed algorithm.