 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Contrastive Learning for Online Knowledge Distillation
Jun 07, 2020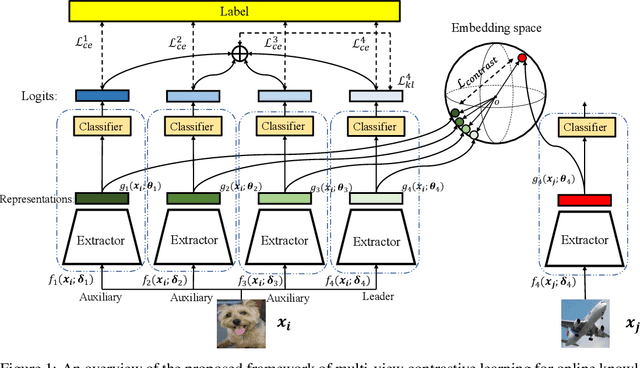
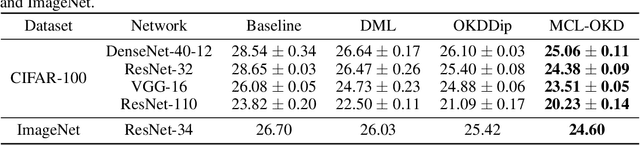

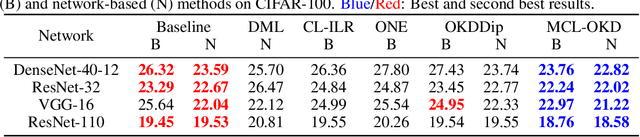
Existing Online Knowledge Distillation (OKD) aims to perform collaborative and mutual learning among multiple peer networks in terms of probabilistic outputs, but ignores the representational knowledge. We thus introduce Multi-view Contrastive Learning (MCL) for OKD to implicitly capture correlations of representations encoded by multiple peer networks, which provide various views for understanding the input data samples. Contrastive loss is applied for maximizing the consensus of positive data pairs, while pushing negative data pairs apart in embedding space among various views. Benefit from MCL, we can learn a more discriminative representation for classification than previous OKD methods. Experimental results on image classification and few-shot learning demonstrate that our MCL-OKD outperforms other state-of-the-art methods of both OKD and KD by large margins without sacrificing additional inference cost.
Localizing Multi-scale Semantic Patches for Image Classification
Jan 31, 2020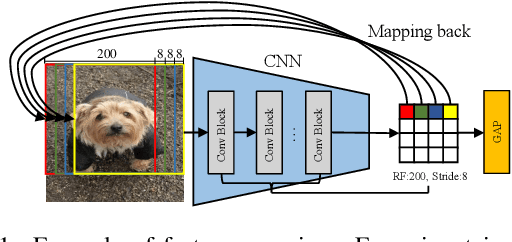
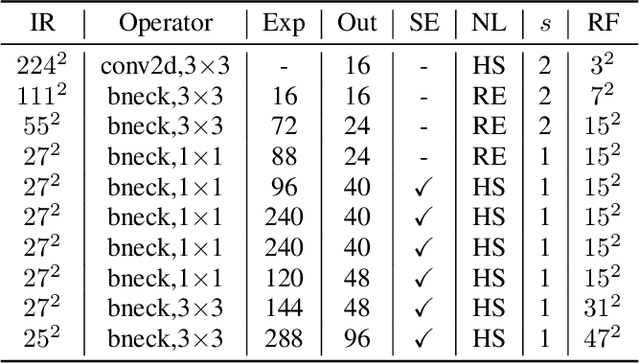


Deep convolutional neural networks (CNN) always non-linearly aggregate the information from the whole input image, which results in the difficult to interpret how relevant regions contribute the final prediction. In this paper, we construct a light-weight AnchorNet combined with our proposed algorithms to localize multi-scale semantic patches, where the contribution of each patch can be determined due to the linearly spatial aggregation before the softmax layer. Visual explanation shows that localized patches can indeed retain the semantics of the original images, while helping us to further analyze the feature extraction of localization branches with various receptive fields. For more practical, we use localized patches for downstream classification tasks across widely applied networks. Experimental results demonstrate that replacing the original images can get a clear inference acceleration with only tiny performance degradation.
Towards More Efficient and Effective Inference: The Joint Decision of Multi-Participants
Jan 19, 2020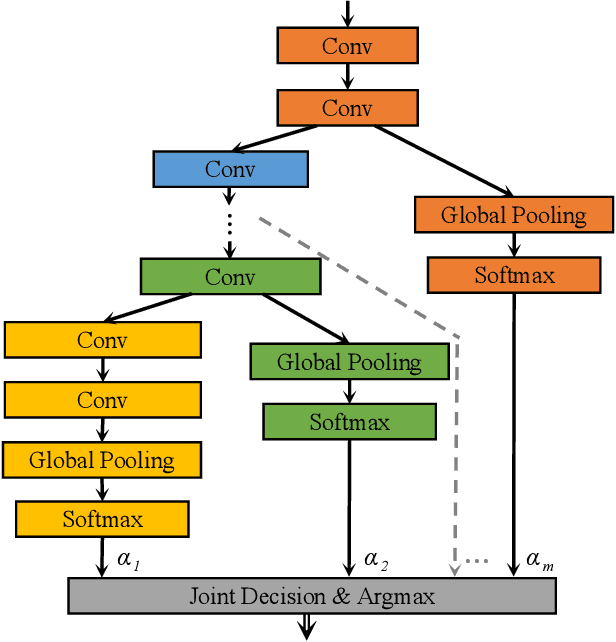
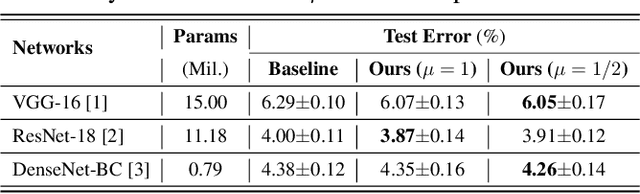
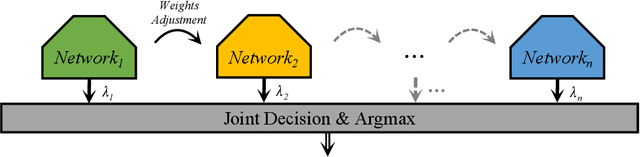
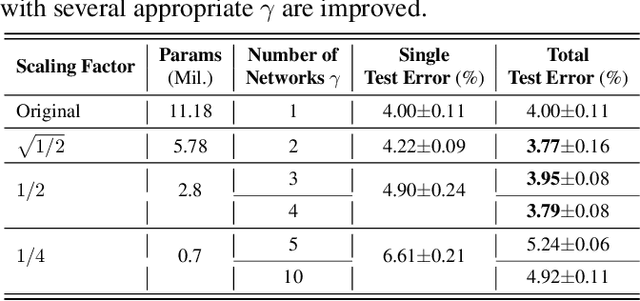
Existing approaches to improve the performances of convolutional neural networks by optimizing the local architectures or deepening the networks tend to increase the size of models significantly. In order to deploy and apply the neural networks to edge devices which are in great demand, reducing the scale of networks are quite crucial. However, It is easy to degrade the performance of image processing by compressing the networks. In this paper, we propose a method which is suitable for edge devices while improving the efficiency and effectiveness of inference. The joint decision of multi-participants, mainly contain multi-layers and multi-networks, can achieve higher classification accuracy (0.26% on CIFAR-10 and 4.49% on CIFAR-100 at most) with similar total number of parameters for classical convolutional neural networks.
DRNet: Dissect and Reconstruct the Convolutional Neural Network via Interpretable Manners
Nov 20, 2019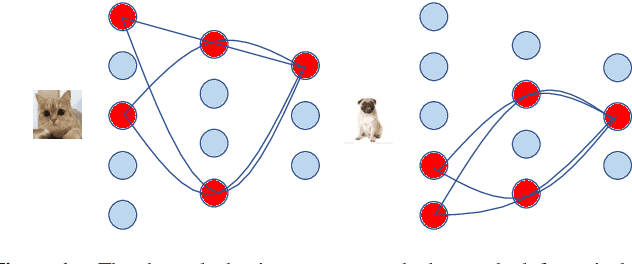
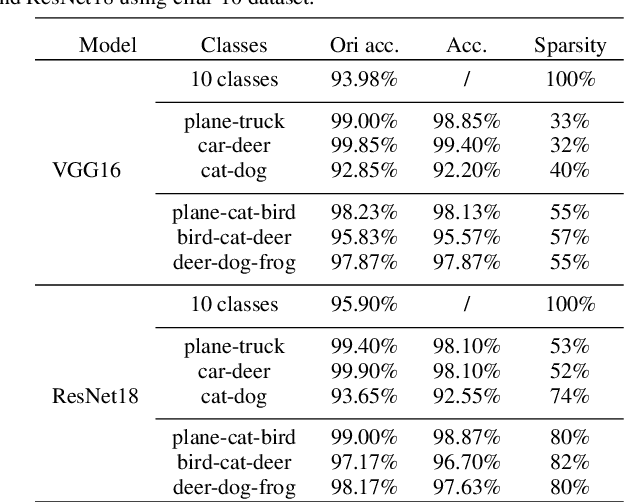


This paper proposes to use an interpretable method to dissect the channels of a large-scale convolutional neural networks (CNNs) into class-wise parts, and reconstruct a CNN using some of these parts. The dissection and reconstruction process can be done in very short time on state-of-the-art networks such as VGG and MobileNetV2. This method allows users to run parts of a CNN according to specific application scenarios, instead of running the whole network or retraining a new one for every task. Experiments on Cifar and ILSVRC 2012 show that the reconstructed CNN runs more efficiently than the original one and achieve a better accuracy. Interpretability analyses show that our method is a new way of applying CNNs on tasks with given knowledge.
Gated Convolutional Networks with Hybrid Connectivity for Image Classification
Sep 08, 2019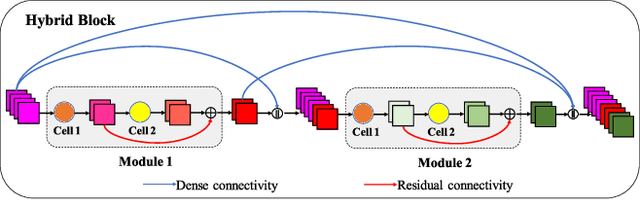
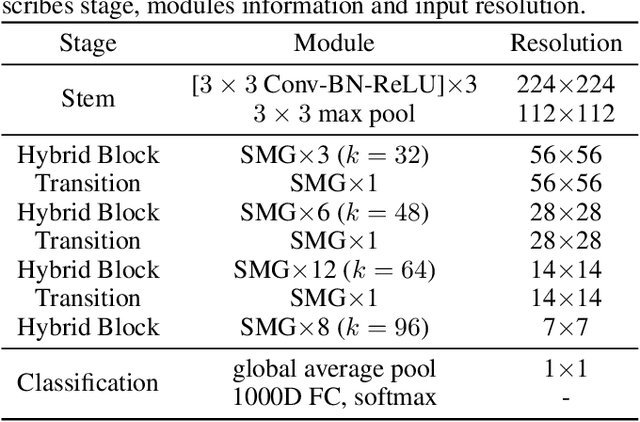
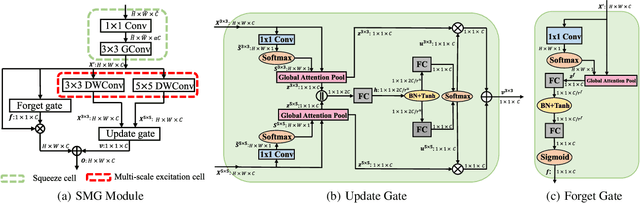
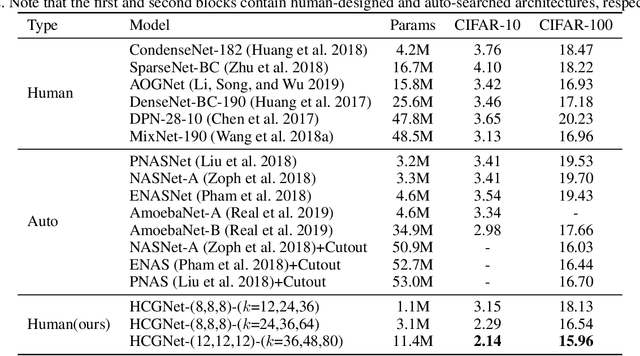
We design a highly efficient architecture called Gated Convolutional Network with Hybrid Connectivity (HCGNet), which is equipped with the combination of local residual and global dense connectivity to enjoy their individual superiorities as well as attention-based gate mechanism to assist feature recalibration. To adapt our hybrid connectivity, we further propose a novel module which includes a squeeze cell for obtaining the compact features from input and then a multi-scale excitation cell attached an update gate to model the global context features for capturing long-range dependency based on multi-scale information. We also locate a forget gate on residual connectivity to decay the reused features, which can be aggergated with newly global context features to form the output that can facilitate effective feature exploration as well as re-exploitation to some extent. Moreover, the number of our proposed modules under dense connectivity can be quite fewer than classical DenseNet thus reducing considerable redundancy but with empirically better performance. On CIFAR-10/100 datasets, HCGNets significantly outperform state-of-the-art both human-designed and auto-searched networks with much fewer parameters. It can also consistently obtain better performance and interpretability than widely applied networks in practice on ImageNet dataset.
Rethinking the Number of Channels for the Convolutional Neural Network
Sep 04, 2019

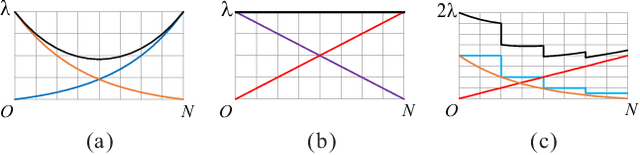

Latest algorithms for automatic neural architecture search perform remarkable but few of them can effectively design the number of channels for convolutional neural networks and consume less computational efforts. In this paper, we propose a method for efficient automatic architecture search which is special to the widths of networks instead of the connections of neural architecture. Our method, functionally incremental search based on function-preserving, will explore the number of channels rapidly while controlling the number of parameters of the target network. On CIFAR-10 and CIFAR-100 classification, our method using minimal computational resources (0.4~1.3 GPU-days) can discover more efficient rules of the widths of networks to improve the accuracy by about 0.5% on CIFAR-10 and a~2.33% on CIFAR-100 with fewer number of parameters. In particular, our method is suitable for exploring the number of channels of almost any convolutional neural network rapidly.