 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Regression under Demographic Parity: A Unified Framework
Jan 15, 2026We propose a unified framework for fair regression tasks formulated as risk minimization problems subject to a demographic parity constraint. Unlike many existing approaches that are limited to specific loss functions or rely on challenging non-convex optimization, our framework is applicable to a broad spectrum of regression tasks. Examples include linear regression with squared loss, binary classification with cross-entropy loss, quantile regression with pinball loss, and robust regression with Huber loss. We derive a novel characterization of the fair risk minimizer, which yields a computationally efficient estimation procedure for general loss functions. Theoretically, we establish the asymptotic consistency of the proposed estimator and derive its convergence rates under mild assumptions. We illustrate the method's versatility through detailed discussions of several common loss functions. Numerical results demonstrate that our approach effectively minimizes risk while satisfying fairness constraints across various regression settings.
Segmenting Watermarked Texts From Language Models
Oct 28, 2024



Watermarking is a technique that involves embedding nearly unnoticeable statistical signals within generated content to help trace its source. This work focuses on a scenario where an untrusted third-party user sends prompts to a trusted language model (LLM) provider, who then generates a text from their LLM with a watermark. This setup makes it possible for a detector to later identify the source of the text if the user publishes it. The user can modify the generated text by substitutions, insertions, or deletions. Our objective is to develop a statistical method to detect if a published text is LLM-generated from the perspective of a detector. We further propose a methodology to segment the published text into watermarked and non-watermarked sub-strings. The proposed approach is built upon randomization tests and change point detection techniques. We demonstrate that our method ensures Type I and Type II error control and can accurately identify watermarked sub-strings by finding the corresponding change point locations. To validate our technique, we apply it to texts generated by several language models with prompts extracted from Google's C4 dataset and obtain encouraging numerical results. We release all code publicly at https://github.com/doccstat/llm-watermark-cpd.
Generalization Bounds and Model Complexity for Kolmogorov-Arnold Networks
Oct 10, 2024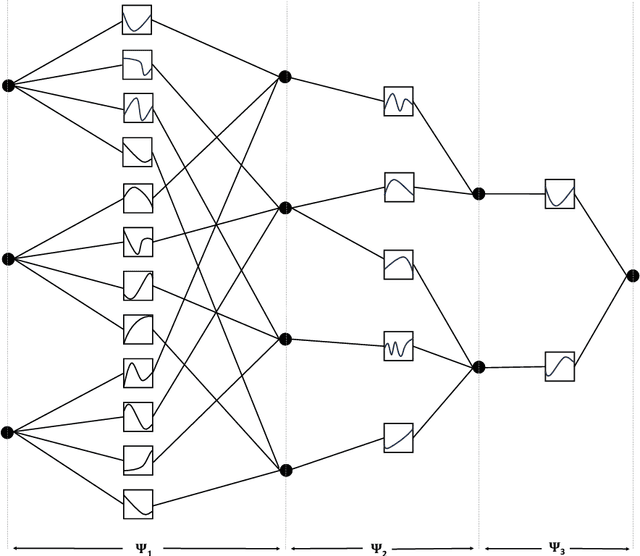
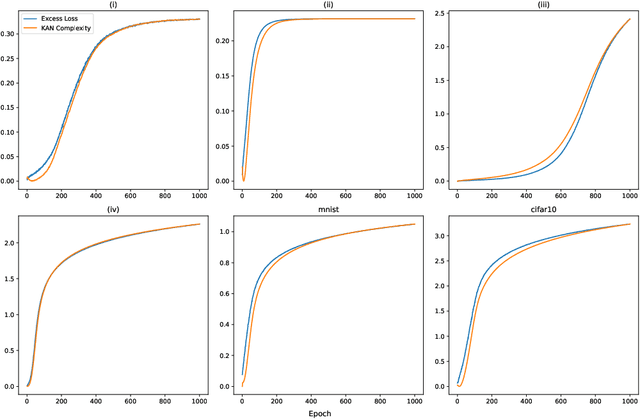
Kolmogorov-Arnold Network (KAN) is a network structure recently proposed by Liu et al. (2024) that offers improved interpretability and a more parsimonious design in many science-oriented tasks compared to multi-layer perceptrons. This work provides a rigorous theoretical analysis of KAN by establishing generalization bounds for KAN equipped with activation functions that are either represented by linear combinations of basis functions or lying in a low-rank Reproducing Kernel Hilbert Space (RKHS). In the first case, the generalization bound accommodates various choices of basis functions in forming the activation functions in each layer of KAN and is adapted to different operator norms at each layer. For a particular choice of operator norms, the bound scales with the $l_1$ norm of the coefficient matrices and the Lipschitz constants for the activation functions, and it has no dependence on combinatorial parameters (e.g., number of nodes) outside of logarithmic factors. Moreover, our result does not require the boundedness assumption on the loss function and, hence, is applicable to a general class of regression-type loss functions. In the low-rank case, the generalization bound scales polynomially with the underlying ranks as well as the Lipschitz constants of the activation functions in each layer. These bounds are empirically investigated for KANs trained with stochastic gradient descent on simulated and real data sets. The numerical results demonstrate the practical relevance of these bounds.
Soft-constrained Schrodinger Bridge: a Stochastic Control Approach
Mar 04, 2024

Schr\"{o}dinger bridge can be viewed as a continuous-time stochastic control problem where the goal is to find an optimally controlled diffusion process with a pre-specified terminal distribution $\mu_T$. We propose to generalize this stochastic control problem by allowing the terminal distribution to differ from $\mu_T$ but penalizing the Kullback-Leibler divergence between the two distributions. We call this new control problem soft-constrained Schr\"{o}dinger bridge (SSB). The main contribution of this work is a theoretical derivation of the solution to SSB, which shows that the terminal distribution of the optimally controlled process is a geometric mixture of $\mu_T$ and some other distribution. This result is further extended to a time series setting. One application of SSB is the development of robust generative diffusion models. We propose a score matching-based algorithm for sampling from geometric mixtures and showcase its use via a numerical example for the MNIST data set.
Kernel Two-Sample Tests in High Dimension: Interplay Between Moment Discrepancy and Dimension-and-Sample Orders
Dec 31, 2021
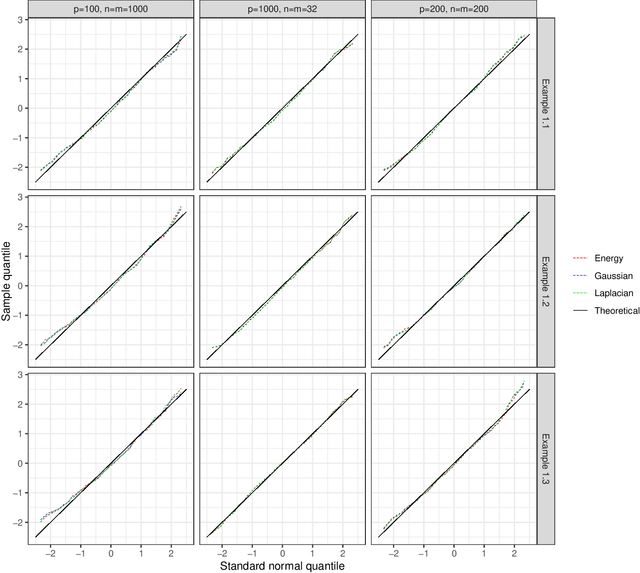

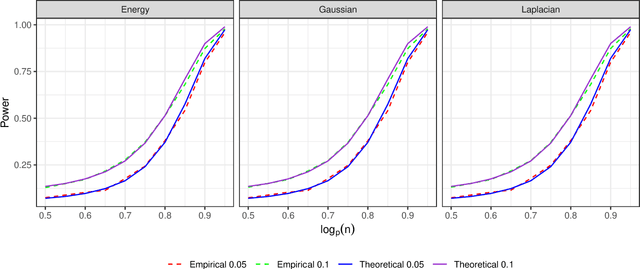
Motivated by the increasing use of kernel-based metrics for high-dimensional and large-scale data, we study the asymptotic behavior of kernel two-sample tests when the dimension and sample sizes both diverge to infinity. We focus on the maximum mean discrepancy (MMD) with the kernel of the form $k(x,y)=f(\|x-y\|_{2}^{2}/\gamma)$, including MMD with the Gaussian kernel and the Laplacian kernel, and the energy distance as special cases. We derive asymptotic expansions of the kernel two-sample statistics, based on which we establish the central limit theorem (CLT) under both the null hypothesis and the local and fixed alternatives. The new non-null CLT results allow us to perform asymptotic exact power analysis, which reveals a delicate interplay between the moment discrepancy that can be detected by the kernel two-sample tests and the dimension-and-sample orders. The asymptotic theory is further corroborated through numerical studies. Our findings complement those in the recent literature and shed new light on the use of kernel two-sample tests for high-dimensional and large-scale data.
A New Framework for Distance and Kernel-based Metrics in High Dimensions
Sep 30, 2019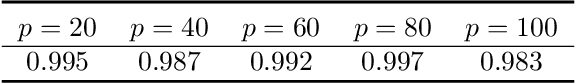
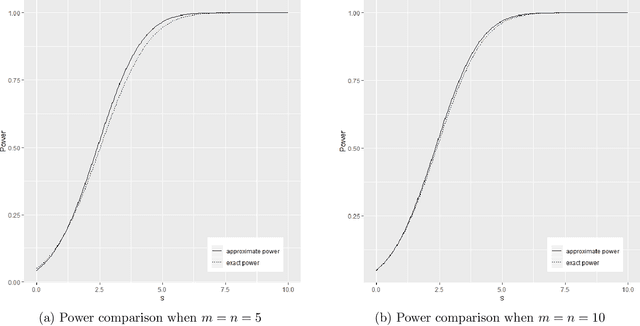
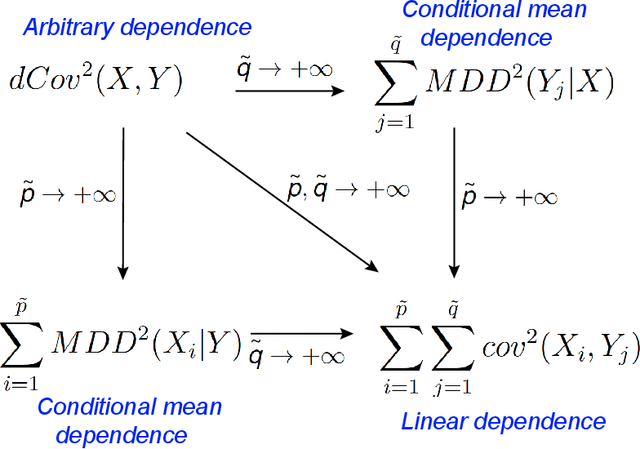

The paper presents new metrics to quantify and test for (i) the equality of distributions and (ii) the independence between two high-dimensional random vectors. We show that the energy distance based on the usual Euclidean distance cannot completely characterize the homogeneity of two high-dimensional distributions in the sense that it only detects the equality of means and the traces of covariance matrices in the high-dimensional setup. We propose a new class of metrics which inherits the desirable properties of the energy distance and maximum mean discrepancy/(generalized) distance covariance and the Hilbert-Schmidt Independence Criterion in the low-dimensional setting and is capable of detecting the homogeneity of/completely characterizing independence between the low-dimensional marginal distributions in the high dimensional setup. We further propose t-tests based on the new metrics to perform high-dimensional two-sample testing/independence testing and study their asymptotic behavior under both high dimension low sample size (HDLSS) and high dimension medium sample size (HDMSS) setups. The computational complexity of the t-tests only grows linearly with the dimension and thus is scalable to very high dimensional data. We demonstrate the superior power behavior of the proposed tests for homogeneity of distributions and independence via both simulated and real datasets.