 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeint in Multi-Player Games
Mar 04, 2024This paper introduces the first formalization, implementation and quantitative evaluation of Feint in Multi-Player Games. Our work first formalizes Feint from the perspective of Multi-Player Games, in terms of the temporal, spatial, and their collective impacts. The formalization is built upon Non-transitive Active Markov Game Model, where Feint can have a considerable amount of impacts. Then, our work considers practical implementation details of Feint in Multi-Player Games, under the state-of-the-art progress of multi-agent modeling to date (namely Multi-Agent Reinforcement Learning). Finally, our work quantitatively examines the effectiveness of our design, and the results show that our design of Feint can (1) greatly improve the reward gains from the game; (2) significantly improve the diversity of Multi-Player Games; and (3) only incur negligible overheads in terms of time consumption. We conclude that our design of Feint is effective and practical, to make Multi-Player Games more interesting.
Polyphonic Sound Event Detection Using Capsule Neural Network on Multi-Type-Multi-Scale Time-Frequency Representation
Nov 25, 2021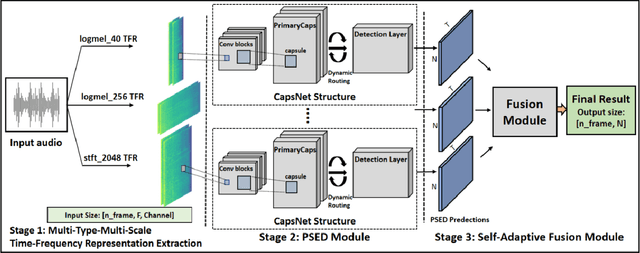
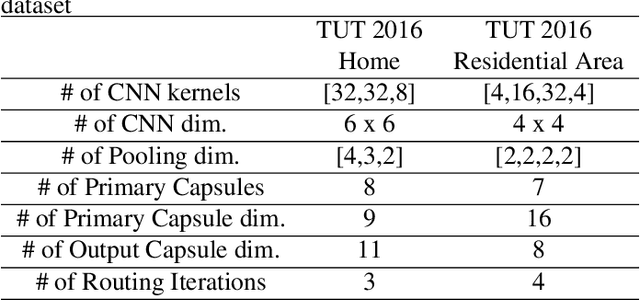
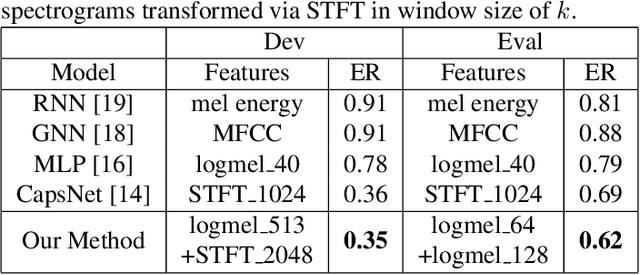
The challenges of polyphonic sound event detection (PSED) stem from the detection of multiple overlapping events in a time series. Recent efforts exploit Deep Neural Networks (DNNs) on Time-Frequency Representations (TFRs) of audio clips as model inputs to mitigate such issues. However, existing solutions often rely on a single type of TFR, which causes under-utilization of input features. To this end, we propose a novel PSED framework, which incorporates Multi-Type-Multi-Scale TFRs. Our key insight is that: TFRs, which are of different types or in different scales, can reveal acoustics patterns in a complementary manner, so that the overlapped events can be best extracted by combining different TFRs. Moreover, our framework design applies a novel approach, to adaptively fuse different models and TFRs symbiotically. Hence, the overall performance can be significantly improved. We quantitatively examine the benefits of our framework by using Capsule Neural Networks, a state-of-the-art approach for PSED. The experimental results show that our method achieves a reduction of 7\% in error rate compared with the state-of-the-art solutions on the TUT-SED 2016 dataset.
Building BROOK: A Multi-modal and Facial Video Database for Human-Vehicle Interaction Research
May 19, 2020
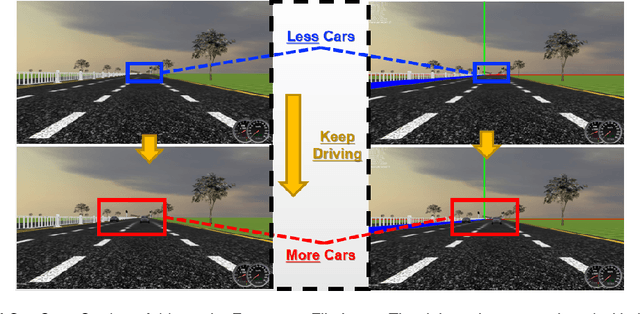
With the growing popularity of Autonomous Vehicles, more opportunities have bloomed in the context of Human-Vehicle Interactions. However, the lack of comprehensive and concrete database support for such specific use case limits relevant studies in the whole design spaces. In this paper, we present our work-in-progress BROOK, a public multi-modal database with facial video records, which could be used to characterize drivers' affective states and driving styles. We first explain how we over-engineer such database in details, and what we have gained through a ten-month study. Then we showcase a Neural Network-based predictor, leveraging BROOK, which supports multi-modal prediction (including physiological data of heart rate and skin conductance and driving status data of speed)through facial videos. Finally, we discuss related issues when building such a database and our future directions in the context of BROOK. We believe BROOK is an essential building block for future Human-Vehicle Interaction Research.