 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Essay Scoring and Feedback Generation in Basque Language Learning
Dec 09, 2025This paper introduces the first publicly available dataset for Automatic Essay Scoring (AES) and feedback generation in Basque, targeting the CEFR C1 proficiency level. The dataset comprises 3,200 essays from HABE, each annotated by expert evaluators with criterion specific scores covering correctness, richness, coherence, cohesion, and task alignment enriched with detailed feedback and error examples. We fine-tune open-source models, including RoBERTa-EusCrawl and Latxa 8B/70B, for both scoring and explanation generation. Our experiments show that encoder models remain highly reliable for AES, while supervised fine-tuning (SFT) of Latxa significantly enhances performance, surpassing state-of-the-art (SoTA) closed-source systems such as GPT-5 and Claude Sonnet 4.5 in scoring consistency and feedback quality. We also propose a novel evaluation methodology for assessing feedback generation, combining automatic consistency metrics with expert-based validation of extracted learner errors. Results demonstrate that the fine-tuned Latxa model produces criterion-aligned, pedagogically meaningful feedback and identifies a wider range of error types than proprietary models. This resource and benchmark establish a foundation for transparent, reproducible, and educationally grounded NLP research in low-resource languages such as Basque.
Extraction of semantic relations from a Basque monolingual dictionary using Constraint Grammar
Oct 17, 2000
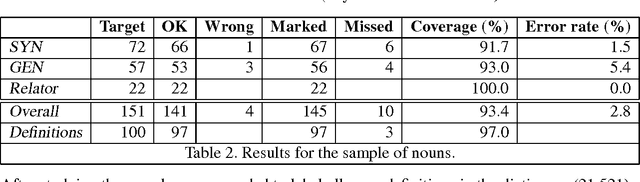
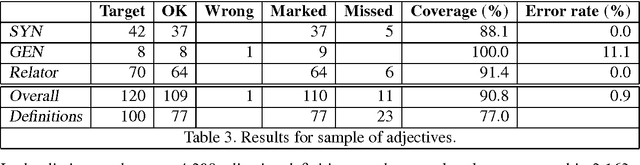
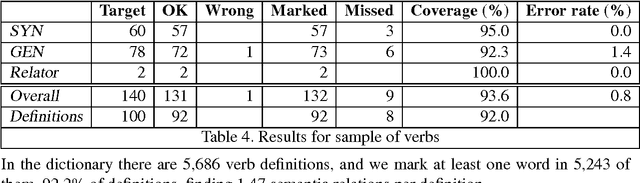
This paper deals with the exploitation of dictionaries for the semi-automatic construction of lexicons and lexical knowledge bases. The final goal of our research is to enrich the Basque Lexical Database with semantic information such as senses, definitions, semantic relations, etc., extracted from a Basque monolingual dictionary. The work here presented focuses on the extraction of the semantic relations that best characterise the headword, that is, those of synonymy, antonymy, hypernymy, and other relations marked by specific relators and derivation. All nominal, verbal and adjectival entries were treated. Basque uses morphological inflection to mark case, and therefore semantic relations have to be inferred from suffixes rather than from prepositions. Our approach combines a morphological analyser and surface syntax parsing (based on Constraint Grammar), and has proven very successful for highly inflected languages such as Basque. Both the effort to write the rules and the actual processing time of the dictionary have been very low. At present we have extracted 42,533 relations, leaving only 2,943 (9%) definitions without any extracted relation. The error rate is extremely low, as only 2.2% of the extracted relations are wrong.
* 11 pages. PostScript format