 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching WordNet concepts with topic signatures
Sep 19, 2001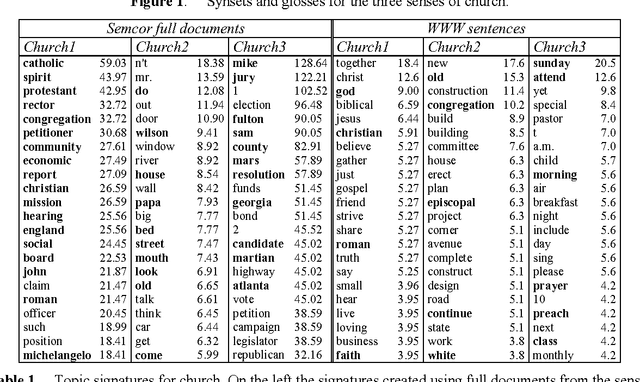
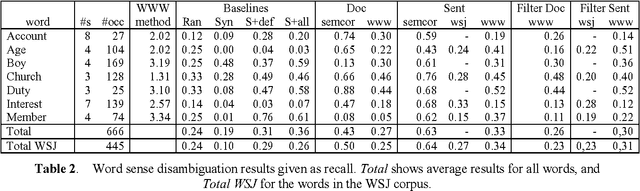
This paper explores the possibility of enriching the content of existing ontologies. The overall goal is to overcome the lack of topical links among concepts in WordNet. Each concept is to be associated to a topic signature, i.e., a set of related words with associated weights. The signatures can be automatically constructed from the WWW or from sense-tagged corpora. Both approaches are compared and evaluated on a word sense disambiguation task. The results show that it is possible to construct clean signatures from the WWW using some filtering techniques.
* Author list corrected
Enriching very large ontologies using the WWW
Oct 17, 2000
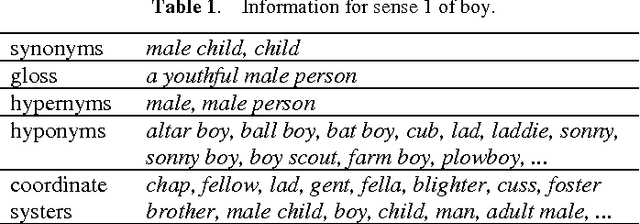
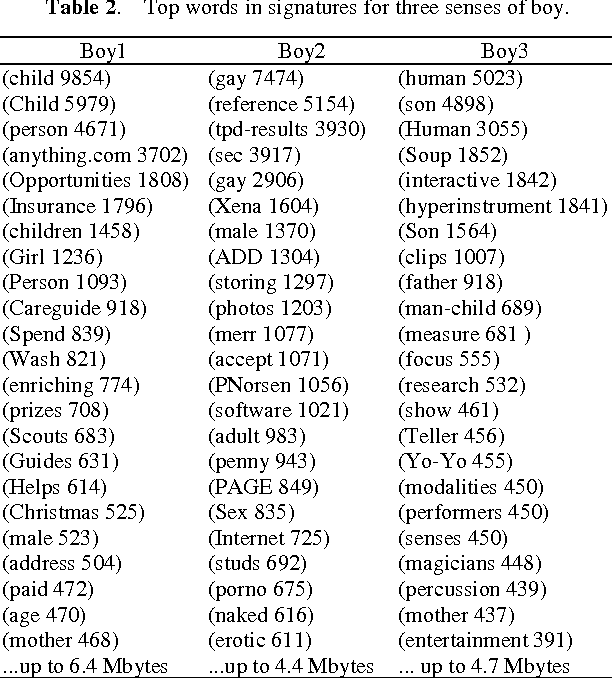
This paper explores the possibility to exploit text on the world wide web in order to enrich the concepts in existing ontologies. First, a method to retrieve documents from the WWW related to a concept is described. These document collections are used 1) to construct topic signatures (lists of topically related words) for each concept in WordNet, and 2) to build hierarchical clusters of the concepts (the word senses) that lexicalize a given word. The overall goal is to overcome two shortcomings of WordNet: the lack of topical links among concepts, and the proliferation of senses. Topic signatures are validated on a word sense disambiguation task with good results, which are improved when the hierarchical clusters are used.
* 6 pages
Extraction of semantic relations from a Basque monolingual dictionary using Constraint Grammar
Oct 17, 2000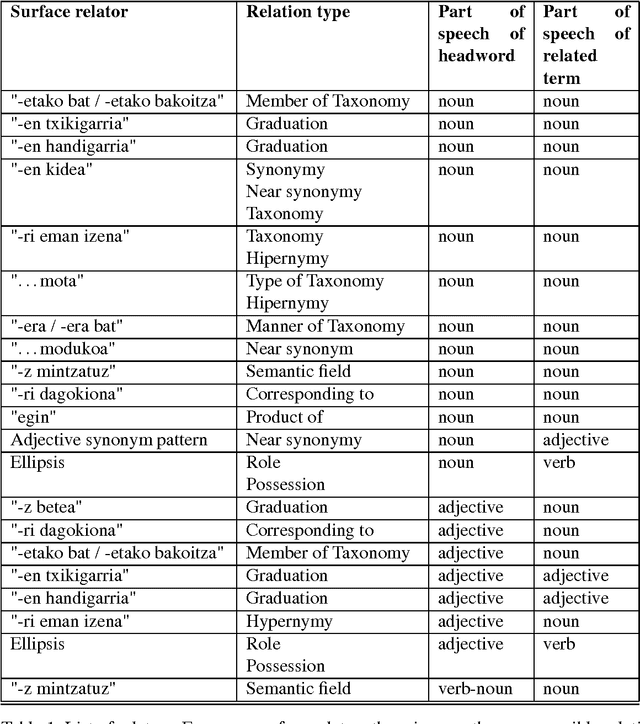
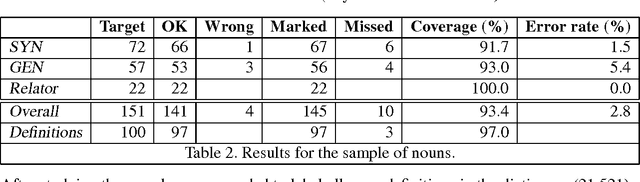
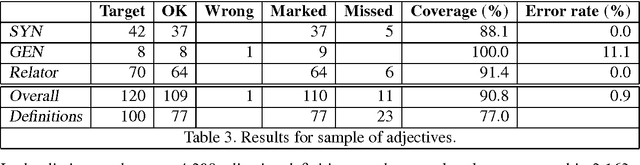
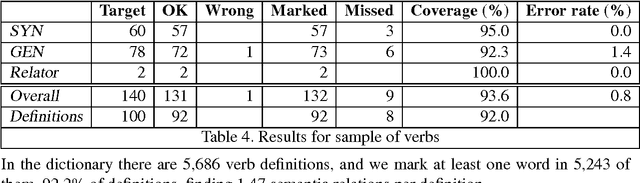
This paper deals with the exploitation of dictionaries for the semi-automatic construction of lexicons and lexical knowledge bases. The final goal of our research is to enrich the Basque Lexical Database with semantic information such as senses, definitions, semantic relations, etc., extracted from a Basque monolingual dictionary. The work here presented focuses on the extraction of the semantic relations that best characterise the headword, that is, those of synonymy, antonymy, hypernymy, and other relations marked by specific relators and derivation. All nominal, verbal and adjectival entries were treated. Basque uses morphological inflection to mark case, and therefore semantic relations have to be inferred from suffixes rather than from prepositions. Our approach combines a morphological analyser and surface syntax parsing (based on Constraint Grammar), and has proven very successful for highly inflected languages such as Basque. Both the effort to write the rules and the actual processing time of the dictionary have been very low. At present we have extracted 42,533 relations, leaving only 2,943 (9%) definitions without any extracted relation. The error rate is extremely low, as only 2.2% of the extracted relations are wrong.
* 11 pages. PostScript format