 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Basque task: did systems perform in the upperbound?
Apr 12, 2002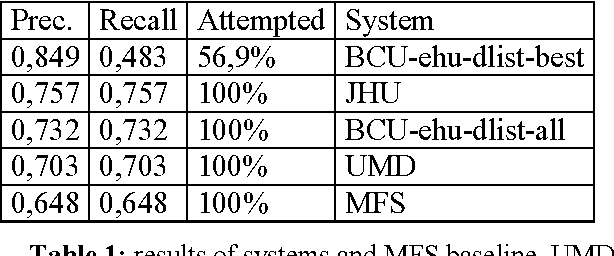
In this paper we describe the Senseval 2 Basque lexical-sample task. The task comprised 40 words (15 nouns, 15 verbs and 10 adjectives) selected from Euskal Hiztegia, the main Basque dictionary. Most examples were taken from the Egunkaria newspaper. The method used to hand-tag the examples produced low inter-tagger agreement (75%) before arbitration. The four competing systems attained results well above the most frequent baseline and the best system scored 75% precision at 100% coverage. The paper includes an analysis of the tagging procedure used, as well as the performance of the competing systems. In particular, we argue that inter-tagger agreement is not a real upperbound for the Basque WSD task.
* 4 pages
Extraction of semantic relations from a Basque monolingual dictionary using Constraint Grammar
Oct 17, 2000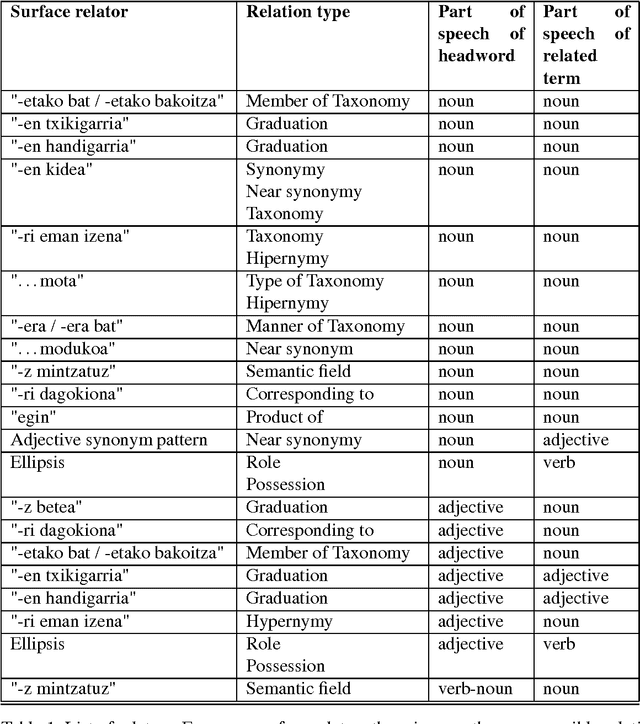
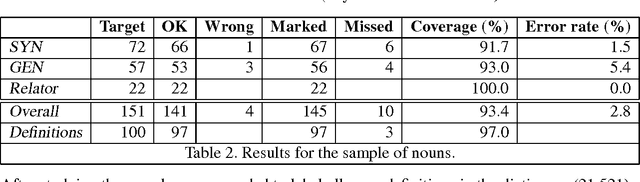
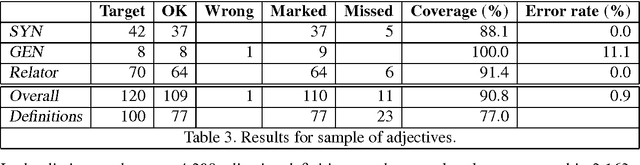
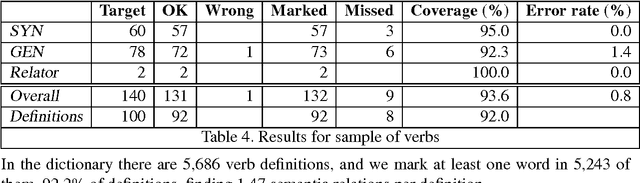
This paper deals with the exploitation of dictionaries for the semi-automatic construction of lexicons and lexical knowledge bases. The final goal of our research is to enrich the Basque Lexical Database with semantic information such as senses, definitions, semantic relations, etc., extracted from a Basque monolingual dictionary. The work here presented focuses on the extraction of the semantic relations that best characterise the headword, that is, those of synonymy, antonymy, hypernymy, and other relations marked by specific relators and derivation. All nominal, verbal and adjectival entries were treated. Basque uses morphological inflection to mark case, and therefore semantic relations have to be inferred from suffixes rather than from prepositions. Our approach combines a morphological analyser and surface syntax parsing (based on Constraint Grammar), and has proven very successful for highly inflected languages such as Basque. Both the effort to write the rules and the actual processing time of the dictionary have been very low. At present we have extracted 42,533 relations, leaving only 2,943 (9%) definitions without any extracted relation. The error rate is extremely low, as only 2.2% of the extracted relations are wrong.
* 11 pages. PostScript format