 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Low-Resource Unsupervised Translation by Language Disentanglement of Multilingual Model
May 31, 2022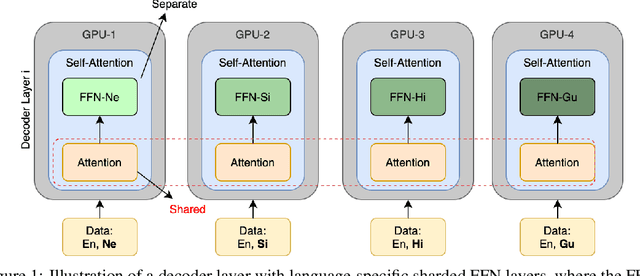

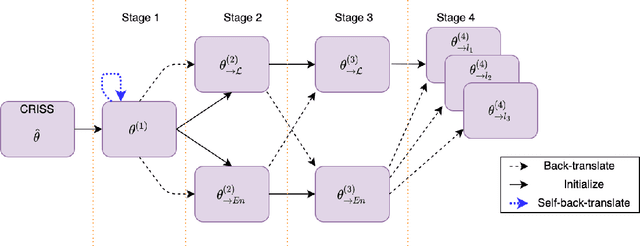
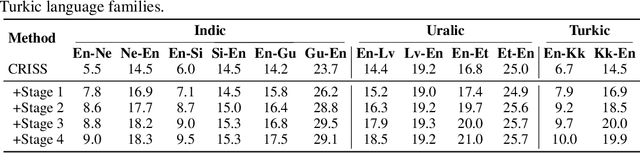
Numerous recent work on unsupervised machine translation (UMT) implies that competent unsupervised translations of low-resource and unrelated languages, such as Nepali or Sinhala, are only possible if the model is trained in a massive multilingual environment, where theses low-resource languages are mixed with high-resource counterparts. Nonetheless, while the high-resource languages greatly help kick-start the target low-resource translation tasks, the language discrepancy between them may hinder their further improvement. In this work, we propose a simple refinement procedure to disentangle languages from a pre-trained multilingual UMT model for it to focus on only the target low-resource task. Our method achieves the state of the art in the fully unsupervised translation tasks of English to Nepali, Sinhala, Gujarati, Latvian, Estonian and Kazakh, with BLEU score gains of 3.5, 3.5, 3.3, 4.1, 4.2, and 3.3, respectively. Our codebase is available at https://github.com/nxphi47/refine_unsup_multilingual_mt
Multi-Agent Cross-Translated Diversification for Unsupervised Machine Translation
Jun 03, 2020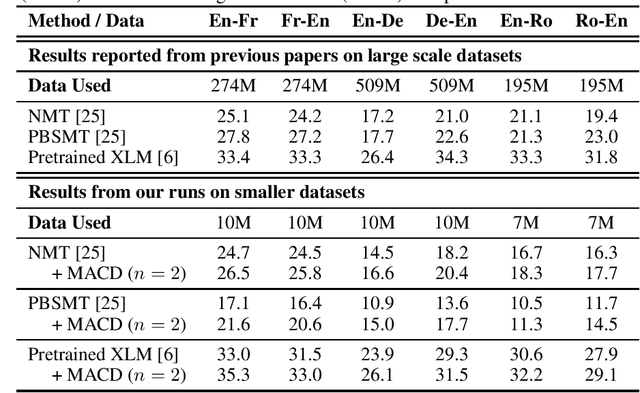

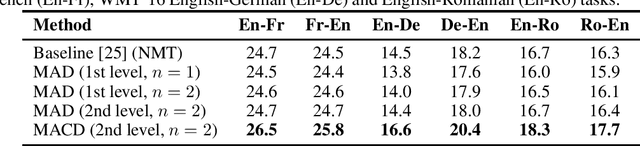
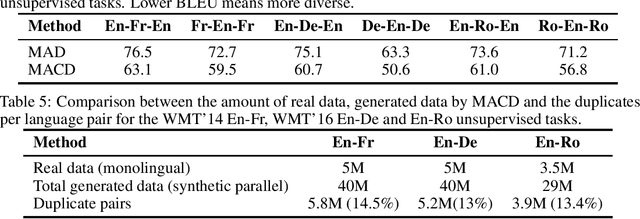
Recent unsupervised machine translation (UMT) systems usually employ three main principles: initialization, language modeling and iterative back-translation, though they may apply these principles differently. This work introduces another component to this framework: Multi-Agent Cross-translated Diversification (MACD). The method trains multiple UMT agents and then translates monolingual data back and forth using non-duplicative agents to acquire synthetic parallel data for supervised MT. MACD is applicable to all previous UMT approaches. In our experiments, the technique boosts the performance for some commonly used UMT methods by 1.5-2.0 BLEU. In particular, in WMT'14 English-French, WMT'16 German-English and English-Romanian, MACD outperforms cross-lingual masked language model pretraining by 2.3, 2.2 and 1.6 BLEU, respectively. It also yields 1.5-3.3 BLEU improvements in IWSLT English-French and English-German translation tasks. Through extensive experimental analyses, we show that MACD is effective because it embraces data diversity while other similar variants do not.
Data Diversification: An Elegant Strategy For Neural Machine Translation
Nov 05, 2019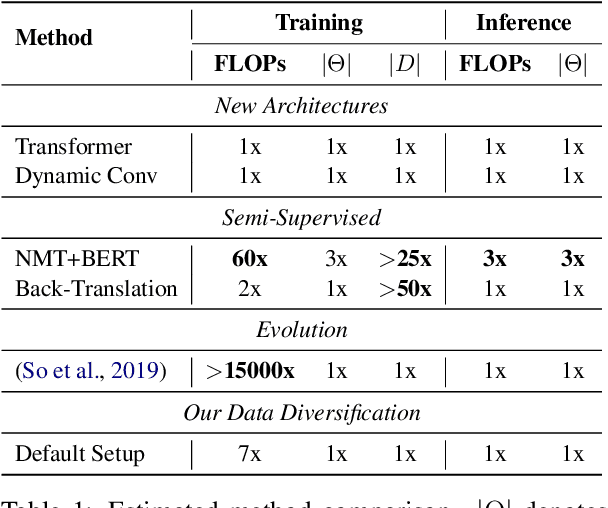
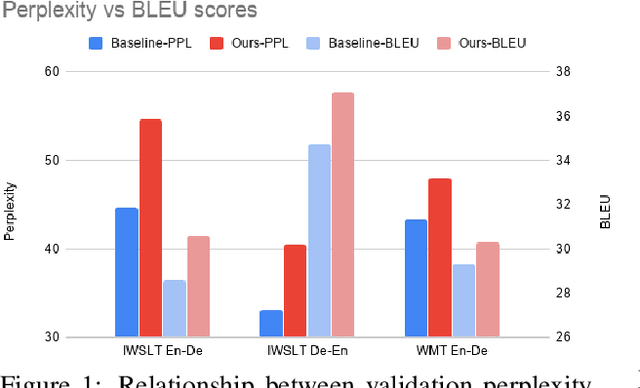
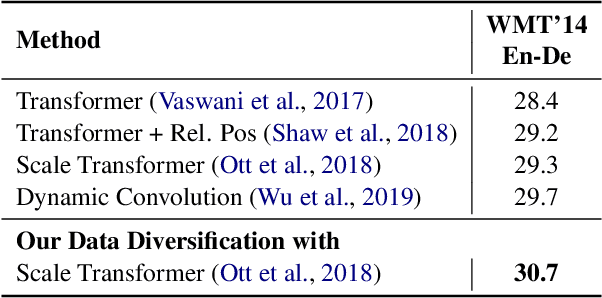
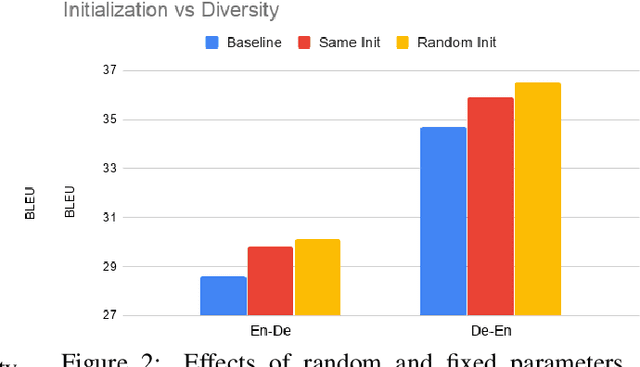
A common approach to improve neural machine translation is to invent new architectures. However, the research process of designing and refining such new models is often exhausting. Another approach is to resort to huge extra monolingual data to conduct semi-supervised training, like back-translation. But extra monolingual data is not always available, especially for low resource languages. In this paper, we propose to diversify the available training data by using multiple forward and backward peer models to augment the original training dataset. Our method does not require extra data like back-translation, nor additional computations and parameters like using pretrained models. Our data diversification method achieves state-of-the-art BLEU score of 30.7 in the WMT'14 English-German task. It also consistently and substantially improves translation quality in 8 other translation tasks: 4 IWSLT tasks (English-German and English-French) and 4 low-resource translation tasks (English-Nepali and English-Sinhala).