 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Diversification: An Elegant Strategy For Neural Machine Translation
Paper and Code
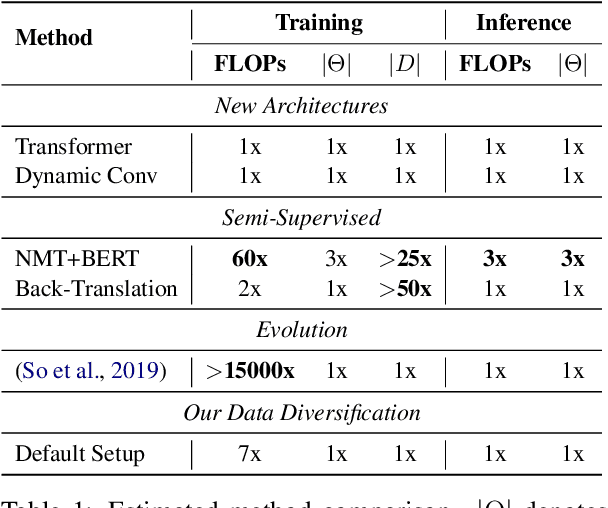
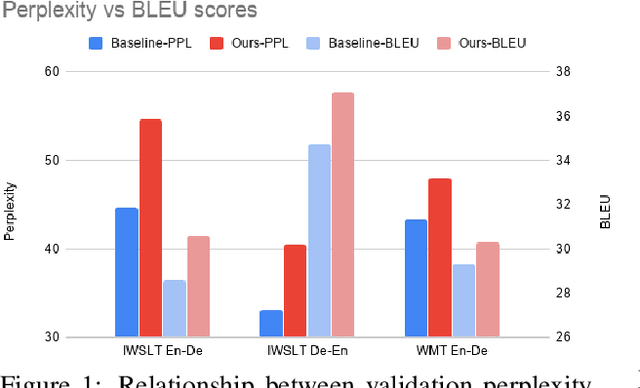
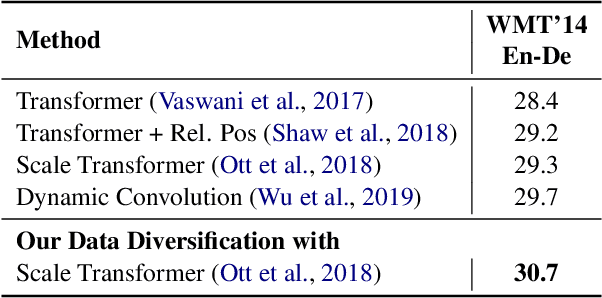
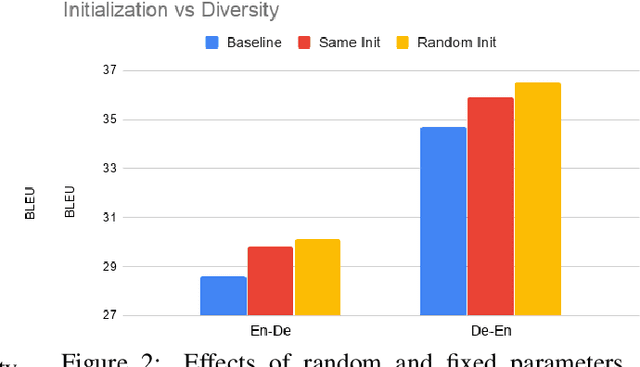
A common approach to improve neural machine translation is to invent new architectures. However, the research process of designing and refining such new models is often exhausting. Another approach is to resort to huge extra monolingual data to conduct semi-supervised training, like back-translation. But extra monolingual data is not always available, especially for low resource languages. In this paper, we propose to diversify the available training data by using multiple forward and backward peer models to augment the original training dataset. Our method does not require extra data like back-translation, nor additional computations and parameters like using pretrained models. Our data diversification method achieves state-of-the-art BLEU score of 30.7 in the WMT'14 English-German task. It also consistently and substantially improves translation quality in 8 other translation tasks: 4 IWSLT tasks (English-German and English-French) and 4 low-resource translation tasks (English-Nepali and English-Sinhala).