 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Graph Traversal
Mar 07, 2025



This research considers Bayesian decision-analytic approaches toward the traversal of an uncertain graph. Namely, a traveler progresses over a graph in which rewards are gained upon a node's first visit and costs are incurred for every edge traversal. The traveler knows the graph's adjacency matrix and his starting position but does not know the rewards and costs. The traveler is a Bayesian who encodes his beliefs about these values using a Gaussian process prior and who seeks to maximize his expected utility over these beliefs. Adopting a decision-analytic perspective, we develop sequential decision-making solution strategies for this coupled information-collection and network-routing problem. We show that the problem is NP-Hard and derive properties of the optimal walk. These properties provide heuristics for the traveler's problem that balance exploration and exploitation. We provide a practical case study focused on the use of unmanned aerial systems for public safety and empirically study policy performance in myriad Erdos-Renyi settings.
Poisoning Bayesian Inference via Data Deletion and Replication
Mar 06, 2025



Research in adversarial machine learning (AML) has shown that statistical models are vulnerable to maliciously altered data. However, despite advances in Bayesian machine learning models, most AML research remains concentrated on classical techniques. Therefore, we focus on extending the white-box model poisoning paradigm to attack generic Bayesian inference, highlighting its vulnerability in adversarial contexts. A suite of attacks are developed that allow an attacker to steer the Bayesian posterior toward a target distribution through the strategic deletion and replication of true observations, even when only sampling access to the posterior is available. Analytic properties of these algorithms are proven and their performance is empirically examined in both synthetic and real-world scenarios. With relatively little effort, the attacker is able to substantively alter the Bayesian's beliefs and, by accepting more risk, they can mold these beliefs to their will. By carefully constructing the adversarial posterior, surgical poisoning is achieved such that only targeted inferences are corrupted and others are minimally disturbed.
Indiscriminate Disruption of Conditional Inference on Multivariate Gaussians
Nov 21, 2024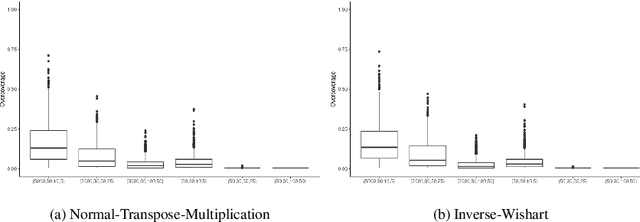
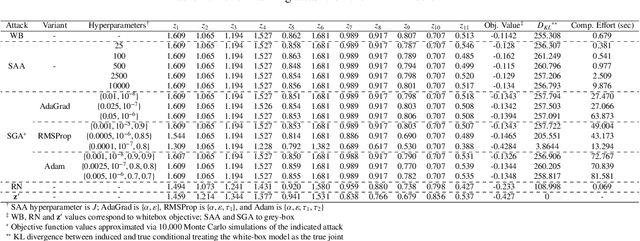
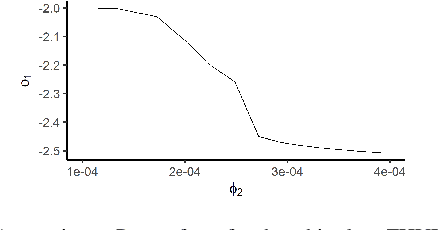
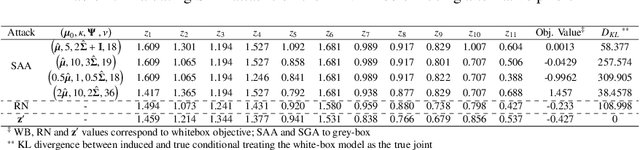
The multivariate Gaussian distribution underpins myriad operations-research, decision-analytic, and machine-learning models (e.g., Bayesian optimization, Gaussian influence diagrams, and variational autoencoders). However, despite recent advances in adversarial machine learning (AML), inference for Gaussian models in the presence of an adversary is notably understudied. Therefore, we consider a self-interested attacker who wishes to disrupt a decisionmaker's conditional inference and subsequent actions by corrupting a set of evidentiary variables. To avoid detection, the attacker also desires the attack to appear plausible wherein plausibility is determined by the density of the corrupted evidence. We consider white- and grey-box settings such that the attacker has complete and incomplete knowledge about the decisionmaker's underlying multivariate Gaussian distribution, respectively. Select instances are shown to reduce to quadratic and stochastic quadratic programs, and structural properties are derived to inform solution methods. We assess the impact and efficacy of these attacks in three examples, including, real estate evaluation, interest rate estimation and signals processing. Each example leverages an alternative underlying model, thereby highlighting the attacks' broad applicability. Through these applications, we also juxtapose the behavior of the white- and grey-box attacks to understand how uncertainty and structure affect attacker behavior.
On Large Language Models in National Security Applications
Jul 03, 2024The overwhelming success of GPT-4 in early 2023 highlighted the transformative potential of large language models (LLMs) across various sectors, including national security. This article explores the implications of LLM integration within national security contexts, analyzing their potential to revolutionize information processing, decision-making, and operational efficiency. Whereas LLMs offer substantial benefits, such as automating tasks and enhancing data analysis, they also pose significant risks, including hallucinations, data privacy concerns, and vulnerability to adversarial attacks. Through their coupling with decision-theoretic principles and Bayesian reasoning, LLMs can significantly improve decision-making processes within national security organizations. Namely, LLMs can facilitate the transition from data to actionable decisions, enabling decision-makers to quickly receive and distill available information with less manpower. Current applications within the US Department of Defense and beyond are explored, e.g., the USAF's use of LLMs for wargaming and automatic summarization, that illustrate their potential to streamline operations and support decision-making. However, these applications necessitate rigorous safeguards to ensure accuracy and reliability. The broader implications of LLM integration extend to strategic planning, international relations, and the broader geopolitical landscape, with adversarial nations leveraging LLMs for disinformation and cyber operations, emphasizing the need for robust countermeasures. Despite exhibiting "sparks" of artificial general intelligence, LLMs are best suited for supporting roles rather than leading strategic decisions. Their use in training and wargaming can provide valuable insights and personalized learning experiences for military personnel, thereby improving operational readiness.
Manipulating hidden-Markov-model inferences by corrupting batch data
Feb 19, 2024



Time-series models typically assume untainted and legitimate streams of data. However, a self-interested adversary may have incentive to corrupt this data, thereby altering a decision maker's inference. Within the broader field of adversarial machine learning, this research provides a novel, probabilistic perspective toward the manipulation of hidden Markov model inferences via corrupted data. In particular, we provision a suite of corruption problems for filtering, smoothing, and decoding inferences leveraging an adversarial risk analysis approach. Multiple stochastic programming models are set forth that incorporate realistic uncertainties and varied attacker objectives. Three general solution methods are developed by alternatively viewing the problem from frequentist and Bayesian perspectives. The efficacy of each method is illustrated via extensive, empirical testing. The developed methods are characterized by their solution quality and computational effort, resulting in a stratification of techniques across varying problem-instance architectures. This research highlights the weaknesses of hidden Markov models under adversarial activity, thereby motivating the need for robustification techniques to ensure their security.
* 42 pages, 8 figures, 11 tables