 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurrogate Search As a Way to Combat Harmful Effects of Ill-behaved Evaluation Functions
Nov 01, 2014
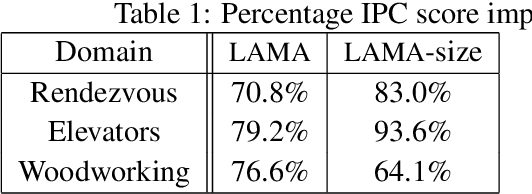
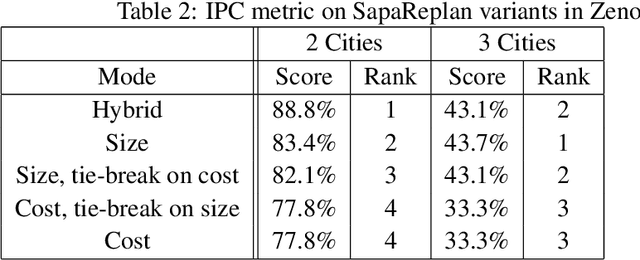
Recently, several researchers have found that cost-based satisficing search with A* often runs into problems. Although some "work arounds" have been proposed to ameliorate the problem, there has been little concerted effort to pinpoint its origin. In this paper, we argue that the origins of this problem can be traced back to the fact that most planners that try to optimize cost also use cost-based evaluation functions (i.e., f(n) is a cost estimate). We show that cost-based evaluation functions become ill-behaved whenever there is a wide variance in action costs; something that is all too common in planning domains. The general solution to this malady is what we call a surrogatesearch, where a surrogate evaluation function that doesn't directly track the cost objective, and is resistant to cost-variance, is used. We will discuss some compelling choices for surrogate evaluation functions that are based on size rather that cost. Of particular practical interest is a cost-sensitive version of size-based evaluation function -- where the heuristic estimates the size of cheap paths, as it provides attractive quality vs. speed tradeoffs
Cost Based Satisficing Search Considered Harmful
Mar 18, 2011

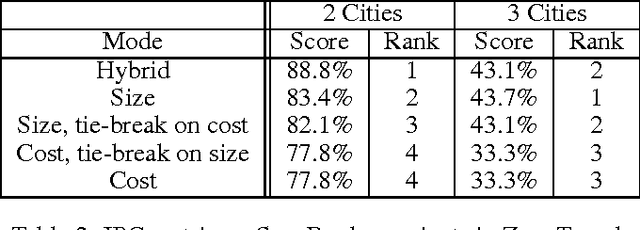

Recently, several researchers have found that cost-based satisficing search with A* often runs into problems. Although some "work arounds" have been proposed to ameliorate the problem, there has not been any concerted effort to pinpoint its origin. In this paper, we argue that the origins can be traced back to the wide variance in action costs that is observed in most planning domains. We show that such cost variance misleads A* search, and that this is no trifling detail or accidental phenomenon, but a systemic weakness of the very concept of "cost-based evaluation functions + systematic search + combinatorial graphs". We show that satisficing search with sized-based evaluation functions is largely immune to this problem.
Learning Probabilistic Hierarchical Task Networks to Capture User Preferences
Jun 02, 2010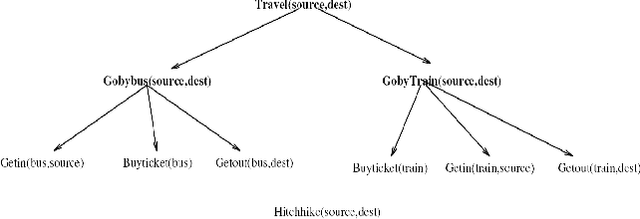



We propose automatically learning probabilistic Hierarchical Task Networks (pHTNs) in order to capture a user's preferences on plans, by observing only the user's behavior. HTNs are a common choice of representation for a variety of purposes in planning, including work on learning in planning. Our contributions are (a) learning structure and (b) representing preferences. In contrast, prior work employing HTNs considers learning method preconditions (instead of structure) and representing domain physics or search control knowledge (rather than preferences). Initially we will assume that the observed distribution of plans is an accurate representation of user preference, and then generalize to the situation where feasibility constraints frequently prevent the execution of preferred plans. In order to learn a distribution on plans we adapt an Expectation-Maximization (EM) technique from the discipline of (probabilistic) grammar induction, taking the perspective of task reductions as productions in a context-free grammar over primitive actions. To account for the difference between the distributions of possible and preferred plans we subsequently modify this core EM technique, in short, by rescaling its input.