 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Solving Mixed-Hierarchy Games with Quasi-Policy Approximations
Feb 02, 2026Multi-robot coordination often exhibits hierarchical structure, with some robots' decisions depending on the planned behaviors of others. While game theory provides a principled framework for such interactions, existing solvers struggle to handle mixed information structures that combine simultaneous (Nash) and hierarchical (Stackelberg) decision-making. We study N-robot forest-structured mixed-hierarchy games, in which each robot acts as a Stackelberg leader over its subtree while robots in different branches interact via Nash equilibria. We derive the Karush-Kuhn-Tucker (KKT) first-order optimality conditions for this class of games and show that they involve increasingly high-order derivatives of robots' best-response policies as the hierarchy depth grows, rendering a direct solution intractable. To overcome this challenge, we introduce a quasi-policy approximation that removes higher-order policy derivatives and develop an inexact Newton method for efficiently solving the resulting approximated KKT systems. We prove local exponential convergence of the proposed algorithm for games with non-quadratic objectives and nonlinear constraints. The approach is implemented in a highly optimized Julia library (MixedHierarchyGames.jl) and evaluated in simulated experiments, demonstrating real-time convergence for complex mixed-hierarchy information structures.
Stochastic Convergence Results for Regularized Actor-Critic Methods
Jul 13, 2019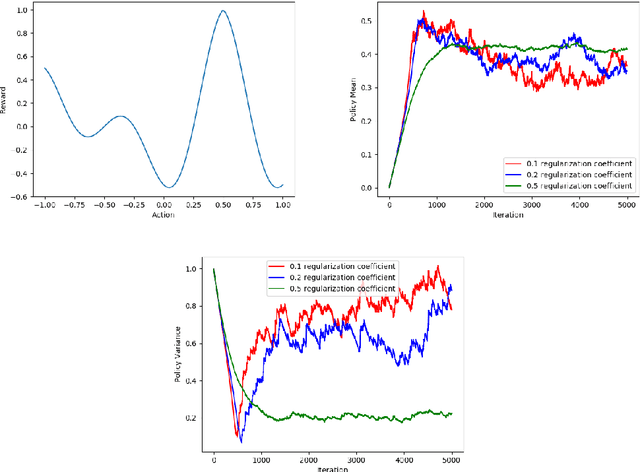
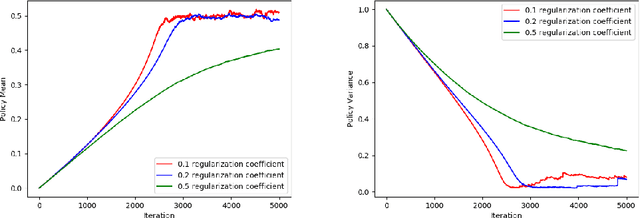
In this paper, we present a stochastic convergence proof, under suitable conditions, of a certain class of actor-critic algorithms for finding approximate solutions to entropy-regularized MDPs using the machinery of stochastic approximation. To obtain this overall result, we provide three fundamental results that are all of both practical and theoretical interest: we prove the convergence of policy evaluation with general regularizers when using linear approximation architectures, we derive an entropy-regularized policy gradient theorem, and we show convergence of entropy-regularized policy improvement. We also provide a simple, illustrative empirical study corroborating our theoretical results. To the best of our knowledge, this is the first time such results have been provided for approximate solution methods for regularized MDPs.
A Multi-Agent Off-Policy Actor-Critic Algorithm for Distributed Reinforcement Learning
Mar 18, 2019This paper extends off-policy reinforcement learning to the multi-agent case in which a set of networked agents communicating with their neighbors according to a time-varying graph collaboratively evaluates and improves a target policy while following a distinct behavior policy. To this end, the paper develops a multi-agent version of emphatic temporal difference learning for off-policy policy evaluation, and proves convergence under linear function approximation. The paper then leverages this result, in conjunction with a novel multi-agent off-policy policy gradient theorem and recent work in both multi-agent on-policy and single-agent off-policy actor-critic methods, to develop and give convergence guarantees for a new multi-agent off-policy actor-critic algorithm.