 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Measurement Model
May 10, 2026Interactive assessments generate sequential process data that are not well handled by conventional item response models. Existing MDP-based measurement approaches, such as the Markov decision process measurement model (MDP-MM, LaMar, 2018), link action choices to state-action values, but their reliance on person-specific tabular value functions makes them difficult to scale beyond small, fully enumerated tasks. We propose the Reinforcement Learning Measurement Model (RLMM), a measurement framework that decouples person-level choice sensitivity from task-level value representation through a shared parametric action-value function, making estimation more computationally efficient for larger process-data settings. The model combines a Boltzmann choice rule with normalized advantages, a soft Bellman consistency penalty, and a block-coordinate MAP procedure for joint estimation, while also yielding step-level influence diagnostics for identifying behaviorally critical decisions. In peg-solitaire simulations, the RLMM achieved higher estimation accuracy and substantially lower runtime than the original MDP-MM, with advantages increasing as task complexity grew. In AQUALAB gameplay logs, the estimated person parameter was positively associated with cumulative reward, task completion, and behavioral efficiency. These results show that the RLMM extends decision-process-based psychometric models to larger and more behaviorally realistic environments while preserving an interpretable latent trait tied to decision making steps.
Image Segmentation using U-Net Architecture for Powder X-ray Diffraction Images
Oct 24, 2023



Scientific researchers frequently use the in situ synchrotron high-energy powder X-ray diffraction (XRD) technique to examine the crystallographic structures of materials in functional devices such as rechargeable battery materials. We propose a method for identifying artifacts in experimental XRD images. The proposed method uses deep learning convolutional neural network architectures, such as tunable U-Nets to identify the artifacts. In particular, the predicted artifacts are evaluated against the corresponding ground truth (manually implemented) using the overall true positive rate or recall. The result demonstrates that the U-Nets can consistently produce great recall performance at 92.4% on the test dataset, which is not included in the training, with a 34% reduction in average false positives in comparison to the conventional method. The U-Nets also reduce the time required to identify and separate artifacts by more than 50%. Furthermore, the exclusion of the artifacts shows major changes in the integrated 1D XRD pattern, enhancing further analysis of the post-processing XRD data.
Artifact Identification in X-ray Diffraction Data using Machine Learning Methods
Jul 29, 2022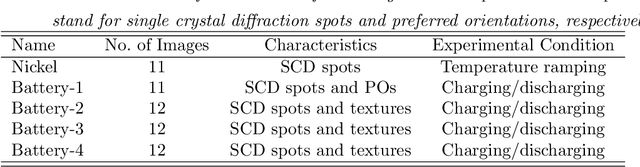
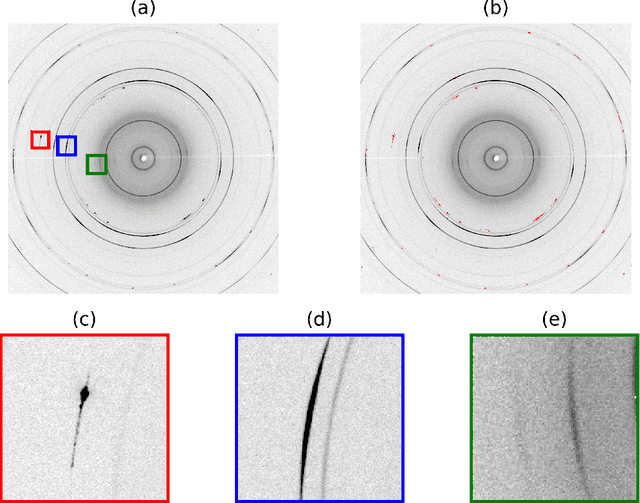
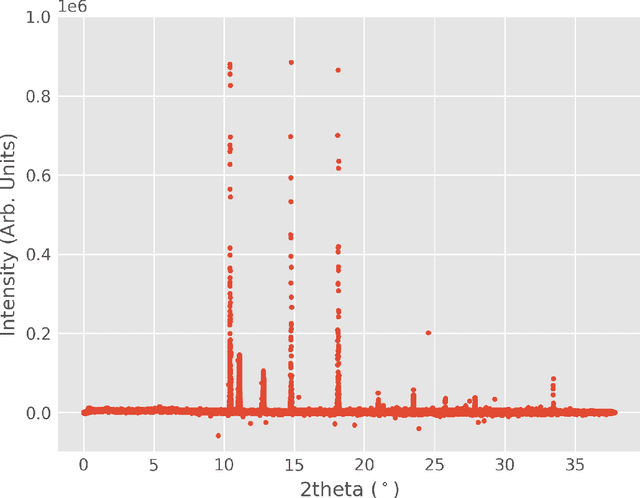
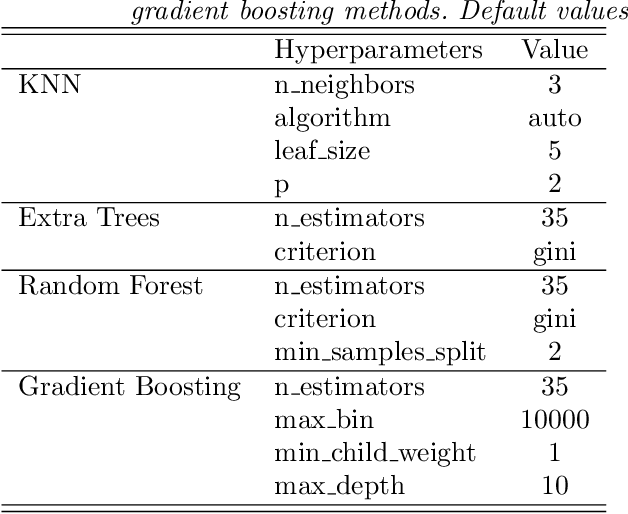
The in situ synchrotron high-energy X-ray powder diffraction (XRD) technique is highly utilized by researchers to analyze the crystallographic structures of materials in functional devices (e.g., battery materials) or in complex sample environments (e.g., diamond anvil cells or syntheses reactors). An atomic structure of a material can be identified by its diffraction pattern, along with detailed analysis such as Rietveld refinement which indicates how the measured structure deviates from the ideal structure (e.g., internal stresses or defects). For in situ experiments, a series of XRD images is usually collected on the same sample at different conditions (e.g., adiabatic conditions), yielding different states of matter, or simply collected continuously as a function of time to track the change of a sample over a chemical or physical process. In situ experiments are usually performed with area detectors, collecting 2D images composed of diffraction rings for ideal powders. Depending on the material's form, one may observe different characteristics other than the typical Debye Scherrer rings for a realistic sample and its environments, such as textures or preferred orientations and single crystal diffraction spots in the 2D XRD image. In this work, we present an investigation of machine learning methods for fast and reliable identification and separation of the single crystal diffraction spots in XRD images. The exclusion of artifacts during an XRD image integration process allows a precise analysis of the powder diffraction rings of interest. We observe that the gradient boosting method can consistently produce high accuracy results when it is trained with small subsets of highly diverse datasets. The method dramatically decreases the amount of time spent on identifying and separating single crystal spots in comparison to the conventional method.
Dual Perceptual Loss for Single Image Super-Resolution Using ESRGAN
Jan 17, 2022



The proposal of perceptual loss solves the problem that per-pixel difference loss function causes the reconstructed image to be overly-smooth, which acquires a significant progress in the field of single image super-resolution reconstruction. Furthermore, the generative adversarial networks (GAN) is applied to the super-resolution field, which effectively improves the visual quality of the reconstructed image. However, under the condtion of high upscaling factors, the excessive abnormal reasoning of the network produces some distorted structures, so that there is a certain deviation between the reconstructed image and the ground-truth image. In order to fundamentally improve the quality of reconstructed images, this paper proposes a effective method called Dual Perceptual Loss (DP Loss), which is used to replace the original perceptual loss to solve the problem of single image super-resolution reconstruction. Due to the complementary property between the VGG features and the ResNet features, the proposed DP Loss considers the advantages of learning two features simultaneously, which significantly improves the reconstruction effect of images. The qualitative and quantitative analysis on benchmark datasets demonstrates the superiority of our proposed method over state-of-the-art super-resolution methods.