 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTR-GQN: Scene Representation and Rendering for Unknown Cameras Based on Spatial Transformation Routing
Aug 06, 2021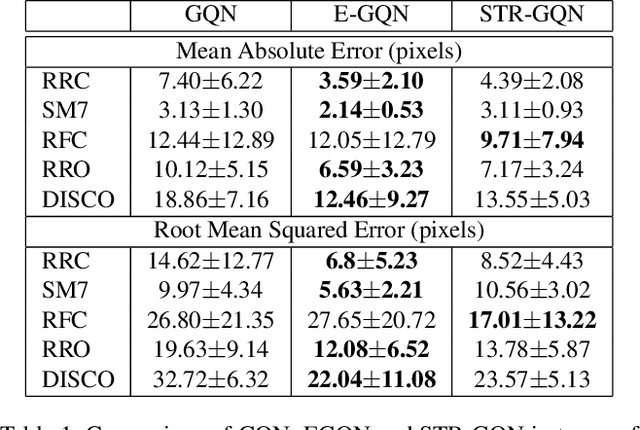
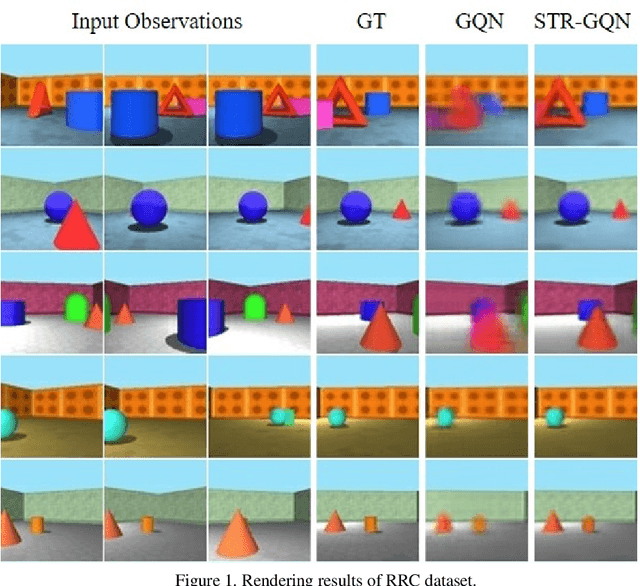
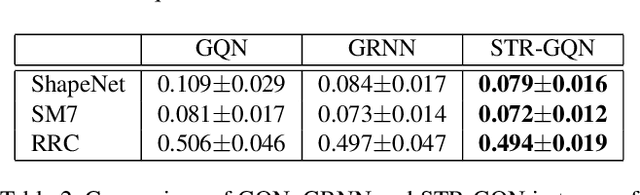

Geometry-aware modules are widely applied in recent deep learning architectures for scene representation and rendering. However, these modules require intrinsic camera information that might not be obtained accurately. In this paper, we propose a Spatial Transformation Routing (STR) mechanism to model the spatial properties without applying any geometric prior. The STR mechanism treats the spatial transformation as the message passing process, and the relation between the view poses and the routing weights is modeled by an end-to-end trainable neural network. Besides, an Occupancy Concept Mapping (OCM) framework is proposed to provide explainable rationals for scene-fusion processes. We conducted experiments on several datasets and show that the proposed STR mechanism improves the performance of the Generative Query Network (GQN). The visualization results reveal that the routing process can pass the observed information from one location of some view to the associated location in the other view, which demonstrates the advantage of the proposed model in terms of spatial cognition.
IMMVP: An Efficient Daytime and Nighttime On-Road Object Detector
Oct 28, 2019

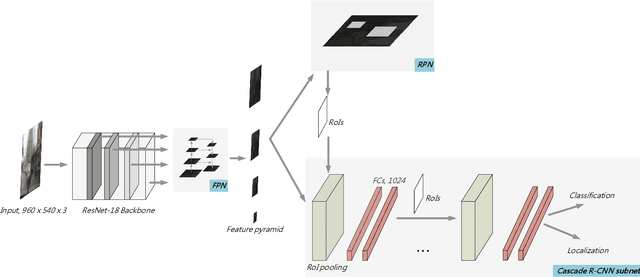

It is hard to detect on-road objects under various lighting conditions. To improve the quality of the classifier, three techniques are used. We define subclasses to separate daytime and nighttime samples. Then we skip similar samples in the training set to prevent overfitting. With the help of the outside training samples, the detection accuracy is also improved. To detect objects in an edge device, Nvidia Jetson TX2 platform, we exert the lightweight model ResNet-18 FPN as the backbone feature extractor. The FPN (Feature Pyramid Network) generates good features for detecting objects over various scales. With Cascade R-CNN technique, the bounding boxes are iteratively refined for better results.
SyncGAN: Synchronize the Latent Space of Cross-modal Generative Adversarial Networks
Apr 02, 2018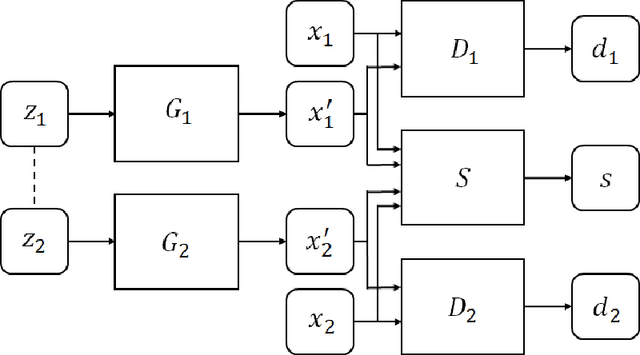

Generative adversarial network (GAN) has achieved impressive success on cross-domain generation, but it faces difficulty in cross-modal generation due to the lack of a common distribution between heterogeneous data. Most existing methods of conditional based cross-modal GANs adopt the strategy of one-directional transfer and have achieved preliminary success on text-to-image transfer. Instead of learning the transfer between different modalities, we aim to learn a synchronous latent space representing the cross-modal common concept. A novel network component named synchronizer is proposed in this work to judge whether the paired data is synchronous/corresponding or not, which can constrain the latent space of generators in the GANs. Our GAN model, named as SyncGAN, can successfully generate synchronous data (e.g., a pair of image and sound) from identical random noise. For transforming data from one modality to another, we recover the latent code by inverting the mappings of a generator and use it to generate data of different modality. In addition, the proposed model can achieve semi-supervised learning, which makes our model more flexible for practical applications.