 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyncGAN: Synchronize the Latent Space of Cross-modal Generative Adversarial Networks
Apr 02, 2018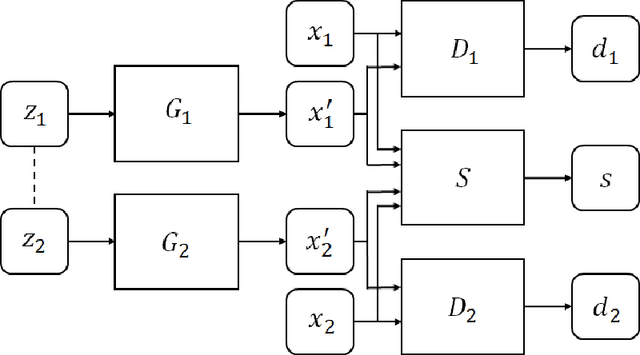
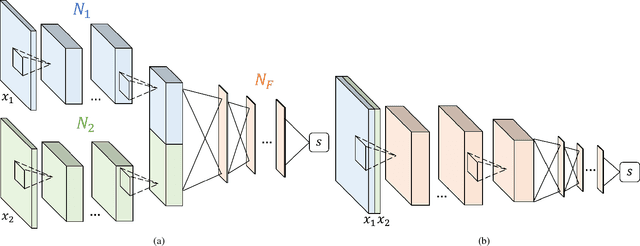

Generative adversarial network (GAN) has achieved impressive success on cross-domain generation, but it faces difficulty in cross-modal generation due to the lack of a common distribution between heterogeneous data. Most existing methods of conditional based cross-modal GANs adopt the strategy of one-directional transfer and have achieved preliminary success on text-to-image transfer. Instead of learning the transfer between different modalities, we aim to learn a synchronous latent space representing the cross-modal common concept. A novel network component named synchronizer is proposed in this work to judge whether the paired data is synchronous/corresponding or not, which can constrain the latent space of generators in the GANs. Our GAN model, named as SyncGAN, can successfully generate synchronous data (e.g., a pair of image and sound) from identical random noise. For transforming data from one modality to another, we recover the latent code by inverting the mappings of a generator and use it to generate data of different modality. In addition, the proposed model can achieve semi-supervised learning, which makes our model more flexible for practical applications.