 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylizing 3D Scene via Implicit Representation and HyperNetwork
Jun 05, 2021
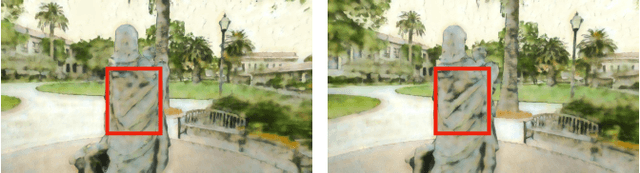

In this work, we aim to address the 3D scene stylization problem - generating stylized images of the scene at arbitrary novel view angles. A straightforward solution is to combine existing novel view synthesis and image/video style transfer approaches, which often leads to blurry results or inconsistent appearance. Inspired by the high quality results of the neural radiance fields (NeRF) method, we propose a joint framework to directly render novel views with the desired style. Our framework consists of two components: an implicit representation of the 3D scene with the neural radiance field model, and a hypernetwork to transfer the style information into the scene representation. In particular, our implicit representation model disentangles the scene into the geometry and appearance branches, and the hypernetwork learns to predict the parameters of the appearance branch from the reference style image. To alleviate the training difficulties and memory burden, we propose a two-stage training procedure and a patch sub-sampling approach to optimize the style and content losses with the neural radiance field model. After optimization, our model is able to render consistent novel views at arbitrary view angles with arbitrary style. Both quantitative evaluation and human subject study have demonstrated that the proposed method generates faithful stylization results with consistent appearance across different views.
Real-time Localized Photorealistic Video Style Transfer
Oct 20, 2020
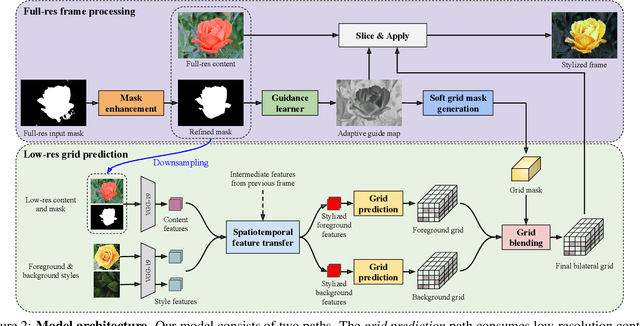
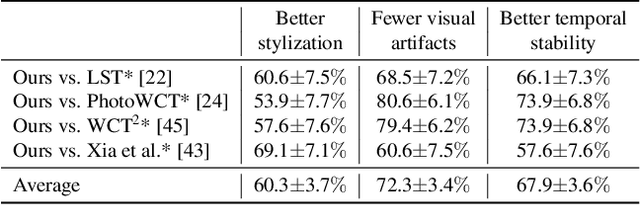

We present a novel algorithm for transferring artistic styles of semantically meaningful local regions of an image onto local regions of a target video while preserving its photorealism. Local regions may be selected either fully automatically from an image, through using video segmentation algorithms, or from casual user guidance such as scribbles. Our method, based on a deep neural network architecture inspired by recent work in photorealistic style transfer, is real-time and works on arbitrary inputs without runtime optimization once trained on a diverse dataset of artistic styles. By augmenting our video dataset with noisy semantic labels and jointly optimizing over style, content, mask, and temporal losses, our method can cope with a variety of imperfections in the input and produce temporally coherent videos without visual artifacts. We demonstrate our method on a variety of style images and target videos, including the ability to transfer different styles onto multiple objects simultaneously, and smoothly transition between styles in time.