 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Feature Learning from Partial Point Clouds via Pose Disentanglement
Jan 09, 2022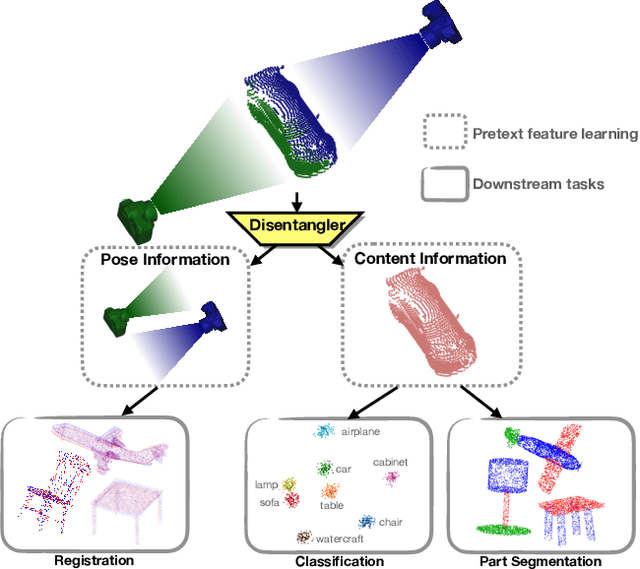
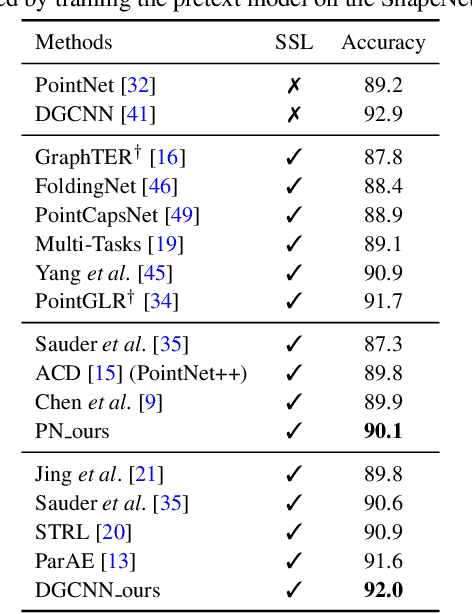
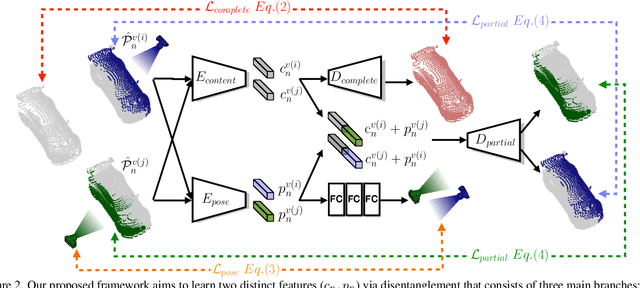
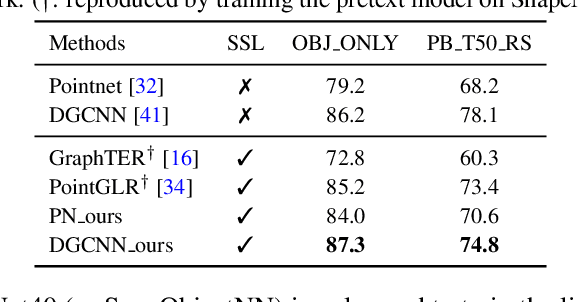
Self-supervised learning on point clouds has gained a lot of attention recently, since it addresses the label-efficiency and domain-gap problems on point cloud tasks. In this paper, we propose a novel self-supervised framework to learn informative representations from partial point clouds. We leverage partial point clouds scanned by LiDAR that contain both content and pose attributes, and we show that disentangling such two factors from partial point clouds enhances feature representation learning. To this end, our framework consists of three main parts: 1) a completion network to capture holistic semantics of point clouds; 2) a pose regression network to understand the viewing angle where partial data is scanned from; 3) a partial reconstruction network to encourage the model to learn content and pose features. To demonstrate the robustness of the learnt feature representations, we conduct several downstream tasks including classification, part segmentation, and registration, with comparisons against state-of-the-art methods. Our method not only outperforms existing self-supervised methods, but also shows a better generalizability across synthetic and real-world datasets.
Stylizing 3D Scene via Implicit Representation and HyperNetwork
Jun 05, 2021
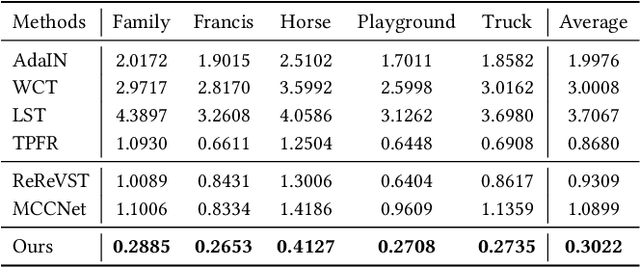
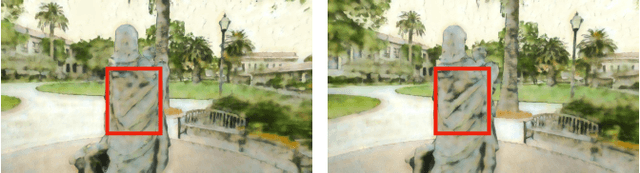

In this work, we aim to address the 3D scene stylization problem - generating stylized images of the scene at arbitrary novel view angles. A straightforward solution is to combine existing novel view synthesis and image/video style transfer approaches, which often leads to blurry results or inconsistent appearance. Inspired by the high quality results of the neural radiance fields (NeRF) method, we propose a joint framework to directly render novel views with the desired style. Our framework consists of two components: an implicit representation of the 3D scene with the neural radiance field model, and a hypernetwork to transfer the style information into the scene representation. In particular, our implicit representation model disentangles the scene into the geometry and appearance branches, and the hypernetwork learns to predict the parameters of the appearance branch from the reference style image. To alleviate the training difficulties and memory burden, we propose a two-stage training procedure and a patch sub-sampling approach to optimize the style and content losses with the neural radiance field model. After optimization, our model is able to render consistent novel views at arbitrary view angles with arbitrary style. Both quantitative evaluation and human subject study have demonstrated that the proposed method generates faithful stylization results with consistent appearance across different views.