 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Convergence of Average Reward Constrained MDPs with Neural Critic and General Policy Parameterization
Mar 08, 2026We study infinite-horizon Constrained Markov Decision Processes (CMDPs) with general policy parameterizations and multi-layer neural network critics. Existing theoretical analyses for constrained reinforcement learning largely rely on tabular policies or linear critics, which limits their applicability to high-dimensional and continuous control problems. We propose a primal-dual natural actor-critic algorithm that integrates neural critic estimation with natural policy gradient updates and leverages Neural Tangent Kernel (NTK) theory to control function-approximation error under Markovian sampling, without requiring access to mixing-time oracles. We establish global convergence and cumulative constraint violation rates of $\tilde{\mathcal{O}}(T^-1/4)$ up to approximation errors induced by the policy and critic classes. Our results provide the first such guarantees for CMDPs with general policies and multi-layer neural critics, substantially extending the theoretical foundations of actor-critic methods beyond the linear-critic regime.
Global Convergence for Average Reward Constrained MDPs with Primal-Dual Actor Critic Algorithm
May 21, 2025This paper investigates infinite-horizon average reward Constrained Markov Decision Processes (CMDPs) with general parametrization. We propose a Primal-Dual Natural Actor-Critic algorithm that adeptly manages constraints while ensuring a high convergence rate. In particular, our algorithm achieves global convergence and constraint violation rates of $\tilde{\mathcal{O}}(1/\sqrt{T})$ over a horizon of length $T$ when the mixing time, $\tau_{\mathrm{mix}}$, is known to the learner. In absence of knowledge of $\tau_{\mathrm{mix}}$, the achievable rates change to $\tilde{\mathcal{O}}(1/T^{0.5-\epsilon})$ provided that $T \geq \tilde{\mathcal{O}}\left(\tau_{\mathrm{mix}}^{2/\epsilon}\right)$. Our results match the theoretical lower bound for Markov Decision Processes and establish a new benchmark in the theoretical exploration of average reward CMDPs.
Finite-Sample Analysis of Policy Evaluation for Robust Average Reward Reinforcement Learning
Feb 24, 2025We present the first finite-sample analysis for policy evaluation in robust average-reward Markov Decision Processes (MDPs). Prior works in this setting have established only asymptotic convergence guarantees, leaving open the question of sample complexity. In this work, we address this gap by establishing that the robust Bellman operator is a contraction under the span semi-norm, and developing a stochastic approximation framework with controlled bias. Our approach builds upon Multi-Level Monte Carlo (MLMC) techniques to estimate the robust Bellman operator efficiently. To overcome the infinite expected sample complexity inherent in standard MLMC, we introduce a truncation mechanism based on a geometric distribution, ensuring a finite constant sample complexity while maintaining a small bias that decays exponentially with the truncation level. Our method achieves the order-optimal sample complexity of $\tilde{\mathcal{O}}(\epsilon^{-2})$ for robust policy evaluation and robust average reward estimation, marking a significant advancement in robust reinforcement learning theory.
Last-Iterate Convergence of General Parameterized Policies in Constrained MDPs
Aug 21, 2024
We consider the problem of learning a Constrained Markov Decision Process (CMDP) via general parameterization. Our proposed Primal-Dual based Regularized Accelerated Natural Policy Gradient (PDR-ANPG) algorithm uses entropy and quadratic regularizers to reach this goal. For a parameterized policy class with transferred compatibility approximation error, $\epsilon_{\mathrm{bias}}$, PDR-ANPG achieves a last-iterate $\epsilon$ optimality gap and $\epsilon$ constraint violation (up to some additive factor of $\epsilon_{\mathrm{bias}}$) with a sample complexity of $\tilde{\mathcal{O}}(\epsilon^{-2}\min\{\epsilon^{-2},\epsilon_{\mathrm{bias}}^{-\frac{1}{3}}\})$. If the class is incomplete ($\epsilon_{\mathrm{bias}}>0$), then the sample complexity reduces to $\tilde{\mathcal{O}}(\epsilon^{-2})$ for $\epsilon<(\epsilon_{\mathrm{bias}})^{\frac{1}{6}}$. Moreover, for complete policies with $\epsilon_{\mathrm{bias}}=0$, our algorithm achieves a last-iterate $\epsilon$ optimality gap and $\epsilon$ constraint violation with $\tilde{\mathcal{O}}(\epsilon^{-4})$ sample complexity. It is a significant improvement of the state-of-the-art last-iterate guarantees of general parameterized CMDPs.
Sample-Efficient Constrained Reinforcement Learning with General Parameterization
May 17, 2024
We consider a constrained Markov Decision Problem (CMDP) where the goal of an agent is to maximize the expected discounted sum of rewards over an infinite horizon while ensuring that the expected discounted sum of costs exceeds a certain threshold. Building on the idea of momentum-based acceleration, we develop the Primal-Dual Accelerated Natural Policy Gradient (PD-ANPG) algorithm that guarantees an $\epsilon$ global optimality gap and $\epsilon$ constraint violation with $\mathcal{O}(\epsilon^{-3})$ sample complexity. This improves the state-of-the-art sample complexity in CMDP by a factor of $\mathcal{O}(\epsilon^{-1})$.
Variance-Reduced Policy Gradient Approaches for Infinite Horizon Average Reward Markov Decision Processes
Apr 02, 2024We present two Policy Gradient-based methods with general parameterization in the context of infinite horizon average reward Markov Decision Processes. The first approach employs Implicit Gradient Transport for variance reduction, ensuring an expected regret of the order $\tilde{\mathcal{O}}(T^{3/5})$. The second approach, rooted in Hessian-based techniques, ensures an expected regret of the order $\tilde{\mathcal{O}}(\sqrt{T})$. These results significantly improve the state of the art of the problem, which achieves a regret of $\tilde{\mathcal{O}}(T^{3/4})$.
Learning General Parameterized Policies for Infinite Horizon Average Reward Constrained MDPs via Primal-Dual Policy Gradient Algorithm
Feb 03, 2024This paper explores the realm of infinite horizon average reward Constrained Markov Decision Processes (CMDP). To the best of our knowledge, this work is the first to delve into the regret and constraint violation analysis of average reward CMDPs with a general policy parametrization. To address this challenge, we propose a primal dual based policy gradient algorithm that adeptly manages the constraints while ensuring a low regret guarantee toward achieving a global optimal policy. In particular, we demonstrate that our proposed algorithm achieves $\tilde{\mathcal{O}}({T}^{3/4})$ objective regret and $\tilde{\mathcal{O}}({T}^{3/4})$ constraint violation bounds.
Improved Sample Complexity Analysis of Natural Policy Gradient Algorithm with General Parameterization for Infinite Horizon Discounted Reward Markov Decision Processes
Oct 18, 2023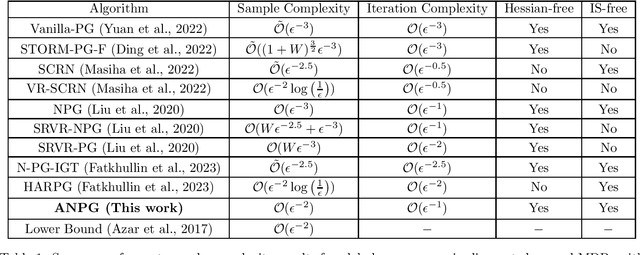
We consider the problem of designing sample efficient learning algorithms for infinite horizon discounted reward Markov Decision Process. Specifically, we propose the Accelerated Natural Policy Gradient (ANPG) algorithm that utilizes an accelerated stochastic gradient descent process to obtain the natural policy gradient. ANPG achieves $\mathcal{O}({\epsilon^{-2}})$ sample complexity and $\mathcal{O}(\epsilon^{-1})$ iteration complexity with general parameterization where $\epsilon$ defines the optimality error. This improves the state-of-the-art sample complexity by a $\log(\frac{1}{\epsilon})$ factor. ANPG is a first-order algorithm and unlike some existing literature, does not require the unverifiable assumption that the variance of importance sampling (IS) weights is upper bounded. In the class of Hessian-free and IS-free algorithms, ANPG beats the best-known sample complexity by a factor of $\mathcal{O}(\epsilon^{-\frac{1}{2}})$ and simultaneously matches their state-of-the-art iteration complexity.
Regret Analysis of Policy Gradient Algorithm for Infinite Horizon Average Reward Markov Decision Processes
Sep 05, 2023In this paper, we consider an infinite horizon average reward Markov Decision Process (MDP). Distinguishing itself from existing works within this context, our approach harnesses the power of the general policy gradient-based algorithm, liberating it from the constraints of assuming a linear MDP structure. We propose a policy gradient-based algorithm and show its global convergence property. We then prove that the proposed algorithm has $\tilde{\mathcal{O}}({T}^{3/4})$ regret. Remarkably, this paper marks a pioneering effort by presenting the first exploration into regret-bound computation for the general parameterized policy gradient algorithm in the context of average reward scenarios.
Cooperating Graph Neural Networks with Deep Reinforcement Learning for Vaccine Prioritization
May 09, 2023



This study explores the vaccine prioritization strategy to reduce the overall burden of the pandemic when the supply is limited. Existing methods conduct macro-level or simplified micro-level vaccine distribution by assuming the homogeneous behavior within subgroup populations and lacking mobility dynamics integration. Directly applying these models for micro-level vaccine allocation leads to sub-optimal solutions due to the lack of behavioral-related details. To address the issue, we first incorporate the mobility heterogeneity in disease dynamics modeling and mimic the disease evolution process using a Trans-vaccine-SEIR model. Then we develop a novel deep reinforcement learning to seek the optimal vaccine allocation strategy for the high-degree spatial-temporal disease evolution system. The graph neural network is used to effectively capture the structural properties of the mobility contact network and extract the dynamic disease features. In our evaluation, the proposed framework reduces 7% - 10% of infections and deaths than the baseline strategies. Extensive evaluation shows that the proposed framework is robust to seek the optimal vaccine allocation with diverse mobility patterns in the micro-level disease evolution system. In particular, we find the optimal vaccine allocation strategy in the transit usage restriction scenario is significantly more effective than restricting cross-zone mobility for the top 10% age-based and income-based zones. These results provide valuable insights for areas with limited vaccines and low logistic efficacy.