 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel OctoMapping: A Scalable Framework for Enhanced Path Planning in Autonomous Navigation
Mar 23, 2026Mapping is essential in robotics and autonomous systems because it provides the spatial foundation for path planning. Efficient mapping enables planning algorithms to generate reliable paths while ensuring safety and adapting in real time to complex environments. Fixed-resolution mapping methods often produce overly conservative obstacle representations that lead to suboptimal paths or planning failures in cluttered scenes. To address this issue, we introduce Parallel OctoMapping (POMP), an efficient OctoMap-based mapping technique that maximizes available free space and supports multi-threaded computation. To the best of our knowledge, POMP is the first method that, at a fixed occupancy-grid resolution, refines the representation of free space while preserving map fidelity and compatibility with existing search-based planners. It can therefore be integrated into existing planning pipelines, yielding higher pathfinding success rates and shorter path lengths, especially in cluttered environments, while substantially improving computational efficiency.
Riemannian Lyapunov Optimizer: A Unified Framework for Optimization
Jan 29, 2026We introduce Riemannian Lyapunov Optimizers (RLOs), a family of optimization algorithms that unifies classic optimizers within one geometric framework. Unlike heuristic improvements to existing optimizers, RLOs are systematically derived from a novel control-theoretic framework that reinterprets optimization as an extended state discrete-time controlled dynamical system on a Riemannian parameter manifold. Central to this framework is the identification of a Normally Attracting Invariant Manifold (NAIM), which organizes training dynamics into two distinct stages: rapid alignment of the speed state to a target graph, followed by controlled evolution within it. We formalize this by constructing a strict Lyapunov function that certifies convergence to a target manifold. This perspective yields a constructive ``optimizer generator" that not only recovers classic algorithms but enables the principled design of RLOs. We validate our theory via geometric diagnostics and demonstrate that grounding optimizer design in control theory yields state-of-the-art performance in large-scale benchmarks. Overall, RLOs bridge control theory and modern machine learning optimization, providing a unified language and a systematic toolkit for designing stable, effective optimizers.
Goal inference with Rao-Blackwellized Particle Filters
Dec 10, 2025Inferring the eventual goal of a mobile agent from noisy observations of its trajectory is a fundamental estimation problem. We initiate the study of such intent inference using a variant of a Rao-Blackwellized Particle Filter (RBPF), subject to the assumption that the agent's intent manifests through closed-loop behavior with a state-of-the-art provable practical stability property. Leveraging the assumed closed-form agent dynamics, the RBPF analytically marginalizes the linear-Gaussian substructure and updates particle weights only, improving sample efficiency over a standard particle filter. Two difference estimators are introduced: a Gaussian mixture model using the RBPF weights and a reduced version confining the mixture to the effective sample. We quantify how well the adversary can recover the agent's intent using information-theoretic leakage metrics and provide computable lower bounds on the Kullback-Leibler (KL) divergence between the true intent distribution and RBPF estimates via Gaussian-mixture KL bounds. We also provide a bound on the difference in performance between the two estimators, highlighting the fact that the reduced estimator performs almost as well as the complete one. Experiments illustrate fast and accurate intent recovery for compliant agents, motivating future work on designing intent-obfuscating controllers.
System Identification and Control Using Lyapunov-Based Deep Neural Networks without Persistent Excitation: A Concurrent Learning Approach
May 15, 2025Deep Neural Networks (DNNs) are increasingly used in control applications due to their powerful function approximation capabilities. However, many existing formulations focus primarily on tracking error convergence, often neglecting the challenge of identifying the system dynamics using the DNN. This paper presents the first result on simultaneous trajectory tracking and online system identification using a DNN-based controller, without requiring persistent excitation. Two new concurrent learning adaptation laws are constructed for the weights of all the layers of the DNN, achieving convergence of the DNN's parameter estimates to a neighborhood of their ideal values, provided the DNN's Jacobian satisfies a finite-time excitation condition. A Lyapunov-based stability analysis is conducted to ensure convergence of the tracking error, weight estimation errors, and observer errors to a neighborhood of the origin. Simulations performed on a range of systems and trajectories, with the same initial and operating conditions, demonstrated 40.5% to 73.6% improvement in function approximation performance compared to the baseline, while maintaining a similar tracking error and control effort. Simulations evaluating function approximation capabilities on data points outside of the trajectory resulted in 58.88% and 74.75% improvement in function approximation compared to the baseline.
Lyapunov-Based Dropout Deep Neural Network (Lb-DDNN) Controller
Oct 30, 2023Deep neural network (DNN)-based adaptive controllers can be used to compensate for unstructured uncertainties in nonlinear dynamic systems. However, DNNs are also very susceptible to overfitting and co-adaptation. Dropout regularization is an approach where nodes are randomly dropped during training to alleviate issues such as overfitting and co-adaptation. In this paper, a dropout DNN-based adaptive controller is developed. The developed dropout technique allows the deactivation of weights that are stochastically selected for each individual layer within the DNN. Simultaneously, a Lyapunov-based real-time weight adaptation law is introduced to update the weights of all layers of the DNN for online unsupervised learning. A non-smooth Lyapunov-based stability analysis is performed to ensure asymptotic convergence of the tracking error. Simulation results of the developed dropout DNN-based adaptive controller indicate a 38.32% improvement in the tracking error, a 53.67% improvement in the function approximation error, and 50.44% lower control effort when compared to a baseline adaptive DNN-based controller without dropout regularization.
Efficient model-based reinforcement learning for approximate online optimal
Feb 09, 2015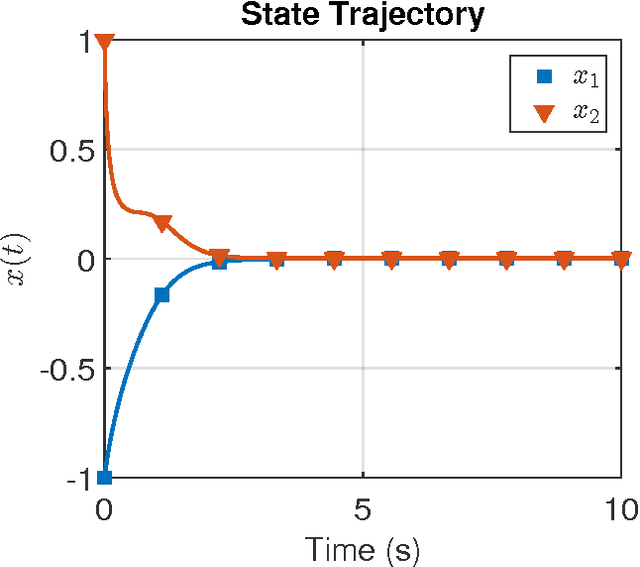
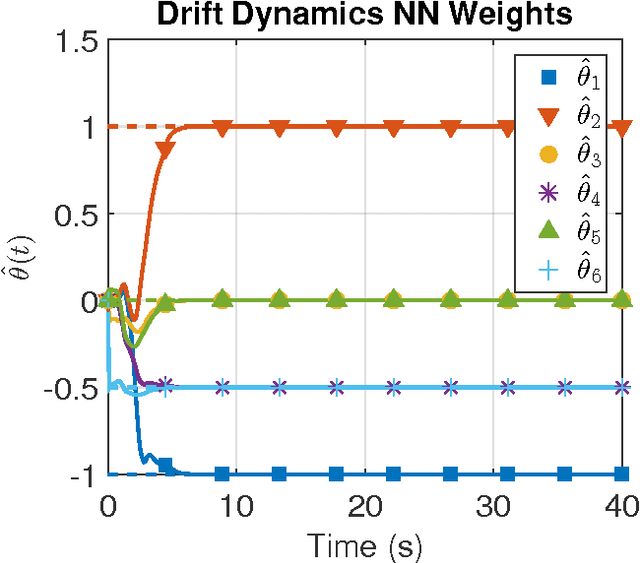
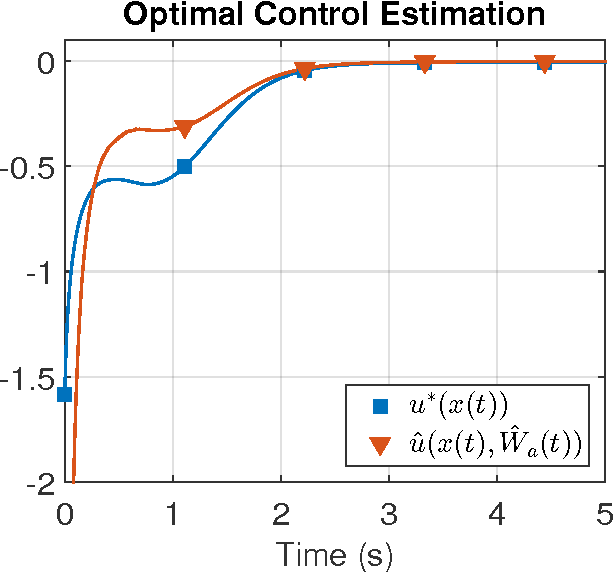
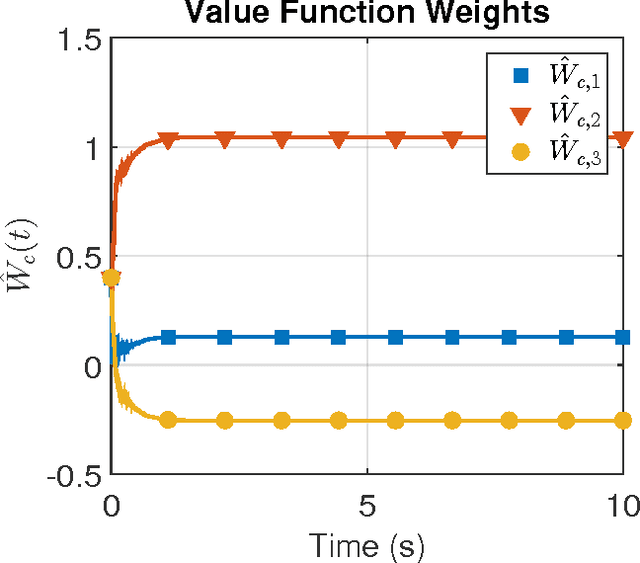
In this paper the infinite horizon optimal regulation problem is solved online for a deterministic control-affine nonlinear dynamical system using the state following (StaF) kernel method to approximate the value function. Unlike traditional methods that aim to approximate a function over a large compact set, the StaF kernel method aims to approximate a function in a small neighborhood of a state that travels within a compact set. Simulation results demonstrate that stability and approximate optimality of the control system can be achieved with significantly fewer basis functions than may be required for global approximation methods.
Online Approximate Optimal Station Keeping of an Autonomous Underwater Vehicle
Apr 01, 2014Online approximation of an optimal station keeping strategy for a fully actuated six degrees-of-freedom autonomous underwater vehicle is considered. The developed controller is an approximation of the solution to a two player zero-sum game where the controller is the minimizing player and an external disturbance is the maximizing player. The solution is approximated using a reinforcement learning-based actor-critic framework. The result guarantees uniformly ultimately bounded (UUB) convergence of the states and UUB convergence of the approximated policies to the optimal polices without the requirement of persistence of excitation.
Decentralized Rendezvous of Nonholonomic Robots with Sensing and Connectivity Constraints
Feb 23, 2014
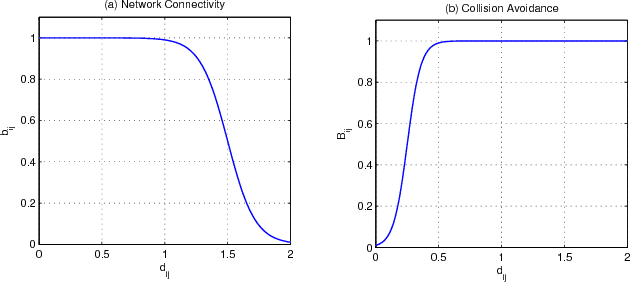
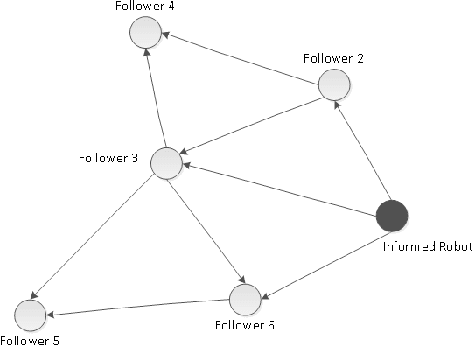
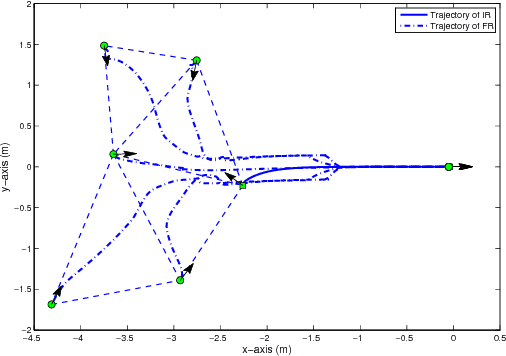
A group of wheeled robots with nonholonomic constraints is considered to rendezvous at a common specified setpoint with a desired orientation while maintaining network connectivity and ensuring collision avoidance within the robots. Given communication and sensing constraints for each robot, only a subset of the robots are aware or informed of the global destination, and the remaining robots must move within the network connectivity constraint so that the informed robots can guide the group to the goal. The mobile robots are also required to avoid collisions with each other outside a neighborhood of the common rendezvous point. To achieve the rendezvous control objective, decentralized time-varying controllers are developed based on a navigation function framework to steer the robots to perform rendezvous while preserving network connectivity and ensuring collision avoidance. Only local sensing feedback, which includes position feedback from immediate neighbors and absolute orientation measurement, is used to navigate the robots and enables radio silence during navigation. Simulation results demonstrate the performance of the developed approach.