 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Information Bottleneck Boosts Adversarial Robustness of Deep Neural Network
Oct 25, 2022



The information bottleneck (IB) method is a feasible defense solution against adversarial attacks in deep learning. However, this method suffers from the spurious correlation, which leads to the limitation of its further improvement of adversarial robustness. In this paper, we incorporate the causal inference into the IB framework to alleviate such a problem. Specifically, we divide the features obtained by the IB method into robust features (content information) and non-robust features (style information) via the instrumental variables to estimate the causal effects. With the utilization of such a framework, the influence of non-robust features could be mitigated to strengthen the adversarial robustness. We make an analysis of the effectiveness of our proposed method. The extensive experiments in MNIST, FashionMNIST, and CIFAR-10 show that our method exhibits the considerable robustness against multiple adversarial attacks. Our code would be released.
Wavelet Regularization Benefits Adversarial Training
Jun 08, 2022

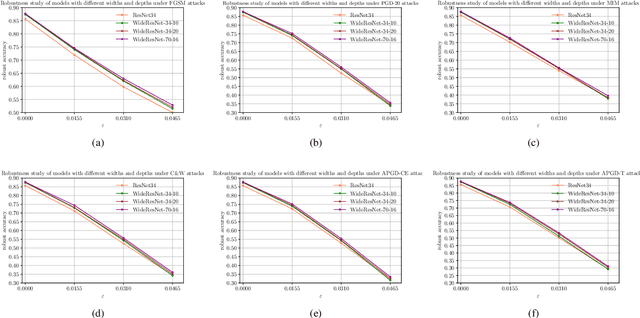
Adversarial training methods are state-of-the-art (SOTA) empirical defense methods against adversarial examples. Many regularization methods have been proven to be effective with the combination of adversarial training. Nevertheless, such regularization methods are implemented in the time domain. Since adversarial vulnerability can be regarded as a high-frequency phenomenon, it is essential to regulate the adversarially-trained neural network models in the frequency domain. Faced with these challenges, we make a theoretical analysis on the regularization property of wavelets which can enhance adversarial training. We propose a wavelet regularization method based on the Haar wavelet decomposition which is named Wavelet Average Pooling. This wavelet regularization module is integrated into the wide residual neural network so that a new WideWaveletResNet model is formed. On the datasets of CIFAR-10 and CIFAR-100, our proposed Adversarial Wavelet Training method realizes considerable robustness under different types of attacks. It verifies the assumption that our wavelet regularization method can enhance adversarial robustness especially in the deep wide neural networks. The visualization experiments of the Frequency Principle (F-Principle) and interpretability are implemented to show the effectiveness of our method. A detailed comparison based on different wavelet base functions is presented. The code is available at the repository: \url{https://github.com/momo1986/AdversarialWaveletTraining}.
On Procedural Adversarial Noise Attack And Defense
Aug 27, 2021
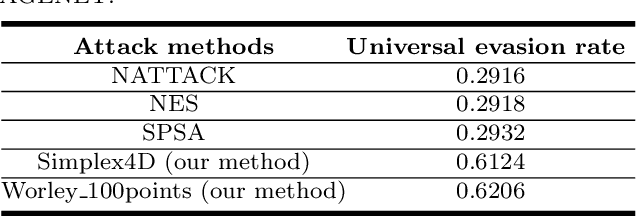
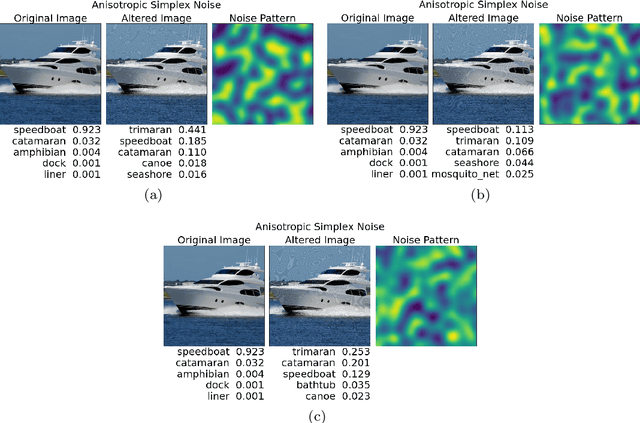
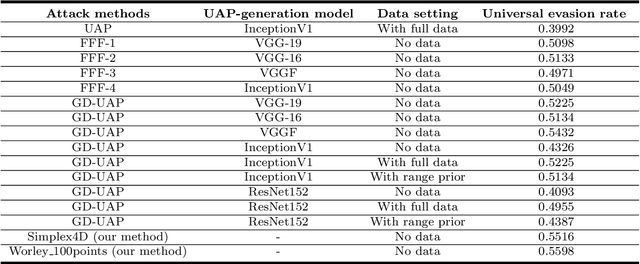
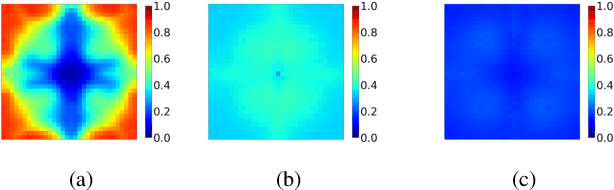
Deep Neural Networks (DNNs) are vulnerable to adversarial examples which would inveigle neural networks to make prediction errors with small perturbations on the input images. Researchers have been devoted to promoting the research on the universal adversarial perturbations (UAPs) which are gradient-free and have little prior knowledge on data distributions. Procedural adversarial noise attack is a data-free universal perturbation generation method. In this paper, we propose two universal adversarial perturbation (UAP) generation methods based on procedural noise functions: Simplex noise and Worley noise. In our framework, the shading which disturbs visual classification is generated with rendering technology. Without changing the semantic representations, the adversarial examples generated via our methods show superior performance on the attack.