 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative Entropy Study of Language Complexity
Jan 15, 2017


We study the entropy of Chinese and English texts, based on characters in case of Chinese texts and based on words for both languages. Significant differences are found between the languages and between different personal styles of debating partners. The entropy analysis points in the direction of lower entropy, that is of higher complexity. Such a text analysis would be applied for individuals of different styles, a single individual at different age, as well as different groups of the population.
Rank-frequency relation for Chinese characters
Jan 26, 2014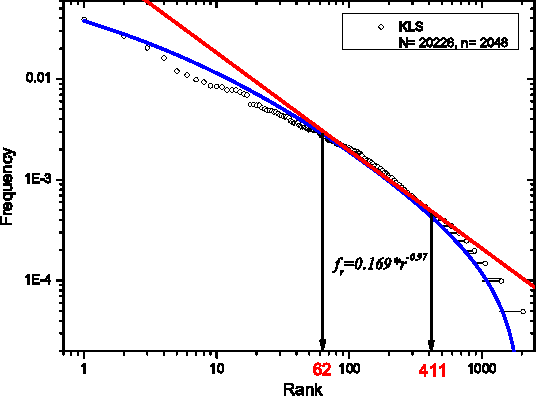
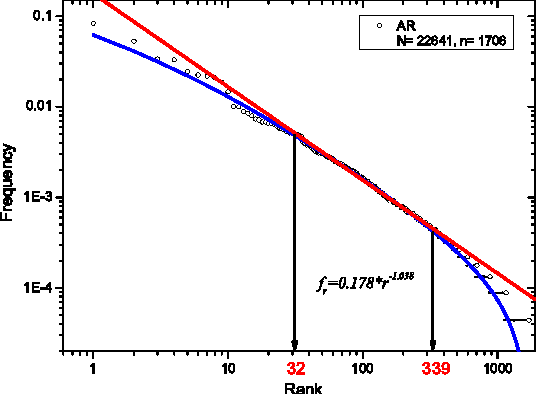
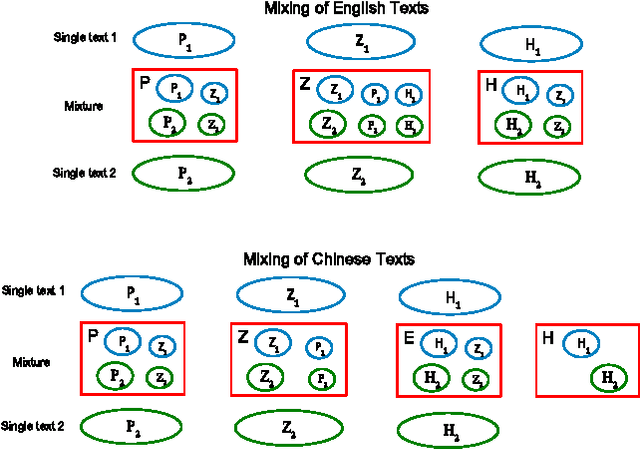
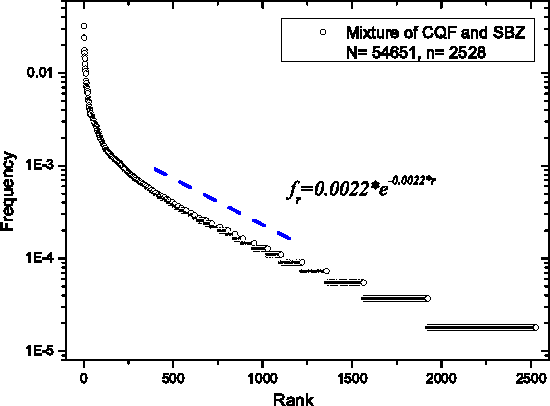
We show that the Zipf's law for Chinese characters perfectly holds for sufficiently short texts (few thousand different characters). The scenario of its validity is similar to the Zipf's law for words in short English texts. For long Chinese texts (or for mixtures of short Chinese texts), rank-frequency relations for Chinese characters display a two-layer, hierarchic structure that combines a Zipfian power-law regime for frequent characters (first layer) with an exponential-like regime for less frequent characters (second layer). For these two layers we provide different (though related) theoretical descriptions that include the range of low-frequency characters (hapax legomena). The comparative analysis of rank-frequency relations for Chinese characters versus English words illustrates the extent to which the characters play for Chinese writers the same role as the words for those writing within alphabetical systems.
* To appear in European Physical Journal B (EPJ B), 2014 (22 pages, 7 figures)