 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManchuTTS: Towards High-Quality Manchu Speech Synthesis via Flow Matching and Hierarchical Text Representation
Dec 27, 2025As an endangered language, Manchu presents unique challenges for speech synthesis, including severe data scarcity and strong phonological agglutination. This paper proposes ManchuTTS(Manchu Text to Speech), a novel approach tailored to Manchu's linguistic characteristics. To handle agglutination, this method designs a three-tier text representation (phoneme, syllable, prosodic) and a cross-modal hierarchical attention mechanism for multi-granular alignment. The synthesis model integrates deep convolutional networks with a flow-matching Transformer, enabling efficient, non-autoregressive generation. This method further introduce a hierarchical contrastive loss to guide structured acoustic-linguistic correspondence. To address low-resource constraints, This method construct the first Manchu TTS dataset and employ a data augmentation strategy. Experiments demonstrate that ManchuTTS attains a MOS of 4.52 using a 5.2-hour training subset derived from our full 6.24-hour annotated corpus, outperforming all baseline models by a notable margin. Ablations confirm hierarchical guidance improves agglutinative word pronunciation accuracy (AWPA) by 31% and prosodic naturalness by 27%.
Quantitative Entropy Study of Language Complexity
Jan 15, 2017

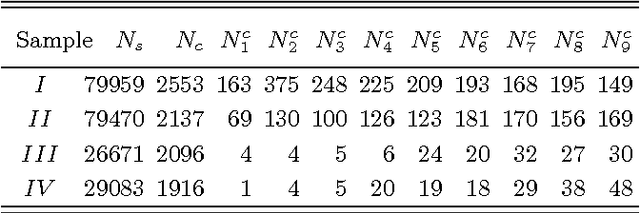

We study the entropy of Chinese and English texts, based on characters in case of Chinese texts and based on words for both languages. Significant differences are found between the languages and between different personal styles of debating partners. The entropy analysis points in the direction of lower entropy, that is of higher complexity. Such a text analysis would be applied for individuals of different styles, a single individual at different age, as well as different groups of the population.