 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand-line Obfuscation Detection using Small Language Models
Aug 05, 2024
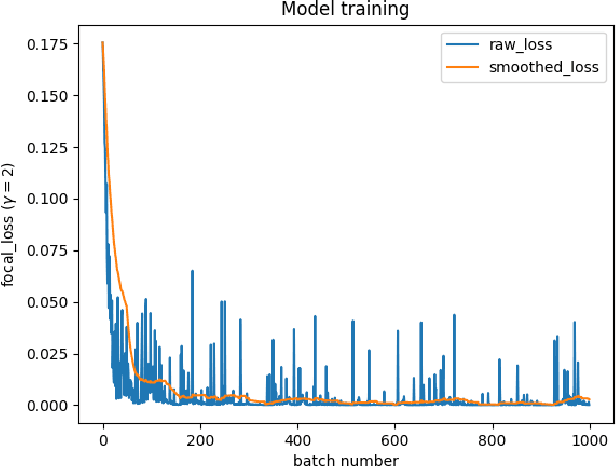
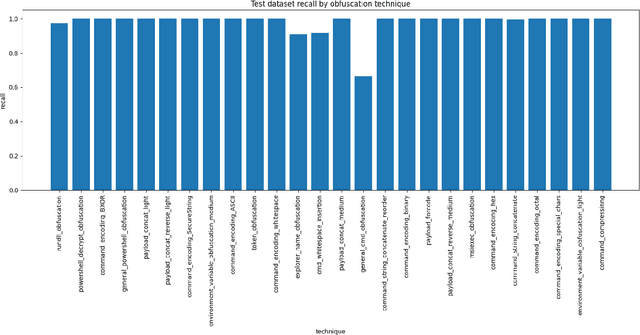
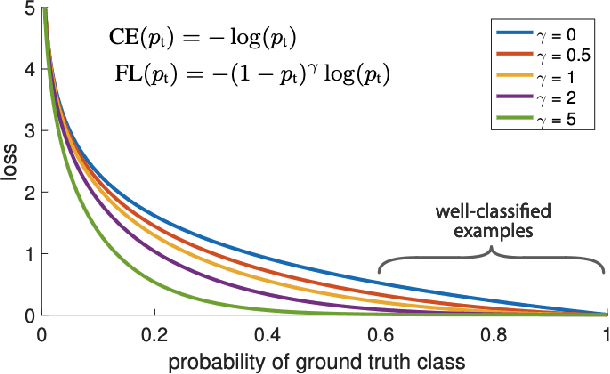
To avoid detection, adversaries often use command-line obfuscation. There are numerous techniques of the command-line obfuscation, all designed to alter the command-line syntax without affecting its original functionality. This variability forces most security solutions to create an exhaustive enumeration of signatures for even a single pattern. In contrast to using signatures, we have implemented a scalable NLP-based detection method that leverages a custom-trained, small transformer language model that can be applied to any source of execution logs. The evaluation on top of real-world telemetry demonstrates that our approach yields high-precision detections even on high-volume telemetry from a diverse set of environments spanning from universities and businesses to healthcare or finance. The practical value is demonstrated in a case study of real-world samples detected by our model. We show the model's superiority to signatures on established malware known to employ obfuscation and showcase previously unseen obfuscated samples detected by our model.
Robot in the mirror: toward an embodied computational model of mirror self-recognition
Nov 09, 2020
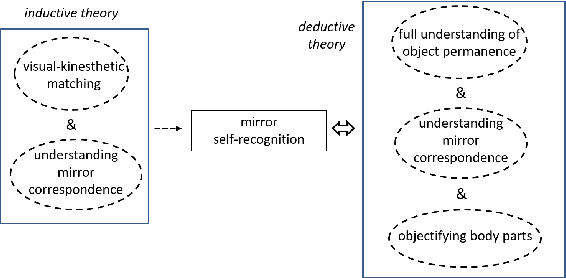
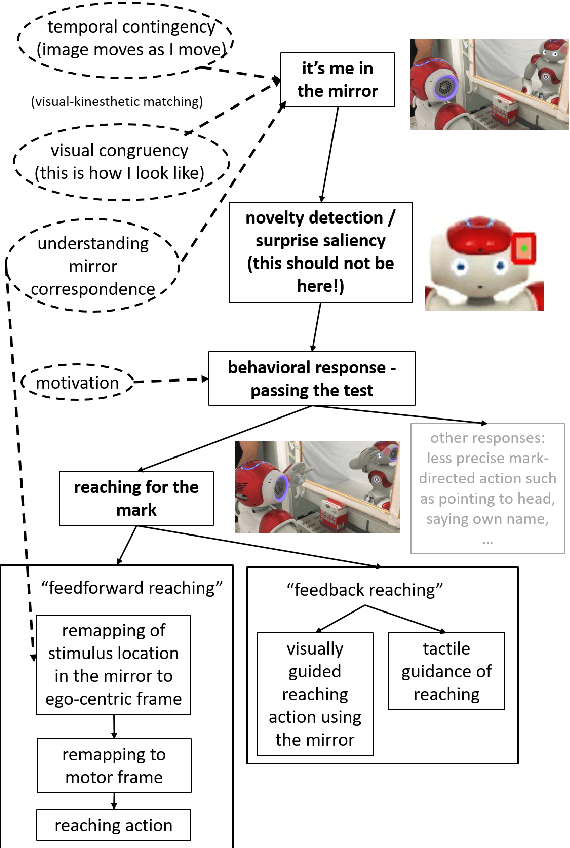
Self-recognition or self-awareness is a capacity attributed typically only to humans and few other species. The definitions of these concepts vary and little is known about the mechanisms behind them. However, there is a Turing test-like benchmark: the mirror self-recognition, which consists in covertly putting a mark on the face of the tested subject, placing her in front of a mirror, and observing the reactions. In this work, first, we provide a mechanistic decomposition, or process model, of what components are required to pass this test. Based on these, we provide suggestions for empirical research. In particular, in our view, the way the infants or animals reach for the mark should be studied in detail. Second, we develop a model to enable the humanoid robot Nao to pass the test. The core of our technical contribution is learning the appearance representation and visual novelty detection by means of learning the generative model of the face with deep auto-encoders and exploiting the prediction error. The mark is identified as a salient region on the face and reaching action is triggered, relying on a previously learned mapping to arm joint angles. The architecture is tested on two robots with a completely different face.