 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Edge Detection And UDF Learning For Shape Representation
May 06, 2024
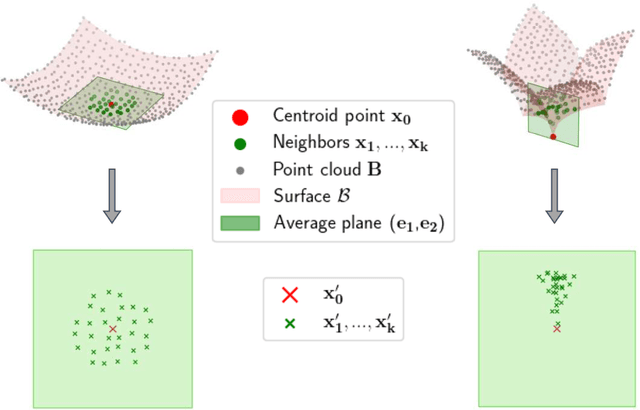


In the field of computer vision, the numerical encoding of 3D surfaces is crucial. It is classical to represent surfaces with their Signed Distance Functions (SDFs) or Unsigned Distance Functions (UDFs). For tasks like representation learning, surface classification, or surface reconstruction, this function can be learned by a neural network, called Neural Distance Function. This network, and in particular its weights, may serve as a parametric and implicit representation for the surface. The network must represent the surface as accurately as possible. In this paper, we propose a method for learning UDFs that improves the fidelity of the obtained Neural UDF to the original 3D surface. The key idea of our method is to concentrate the learning effort of the Neural UDF on surface edges. More precisely, we show that sampling more training points around surface edges allows better local accuracy of the trained Neural UDF, and thus improves the global expressiveness of the Neural UDF in terms of Hausdorff distance. To detect surface edges, we propose a new statistical method based on the calculation of a $p$-value at each point on the surface. Our method is shown to detect surface edges more accurately than a commonly used local geometric descriptor.
On the nonconvexity of some push-forward constraints and its consequences in machine learning
Mar 12, 2024The push-forward operation enables one to redistribute a probability measure through a deterministic map. It plays a key role in statistics and optimization: many learning problems (notably from optimal transport, generative modeling, and algorithmic fairness) include constraints or penalties framed as push-forward conditions on the model. However, the literature lacks general theoretical insights on the (non)convexity of such constraints and its consequences on the associated learning problems. This paper aims at filling this gap. In a first part, we provide a range of sufficient and necessary conditions for the (non)convexity of two sets of functions: the maps transporting one probability measure to another; the maps inducing equal output distributions across distinct probability measures. This highlights that for most probability measures, these push-forward constraints are not convex. In a second time, we show how this result implies critical limitations on the design of convex optimization problems for learning generative models or group-fair predictors. This work will hopefully help researchers and practitioners have a better understanding of the critical impact of push-forward conditions onto convexity.