 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sensitivity of Word Embeddings-based Author Detection Models to Semantic-preserving Adversarial Perturbations
Feb 23, 2021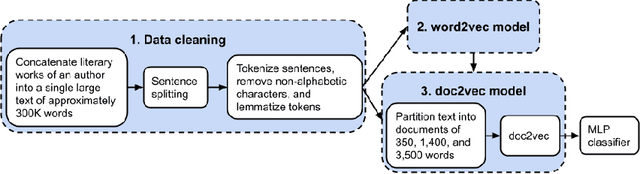

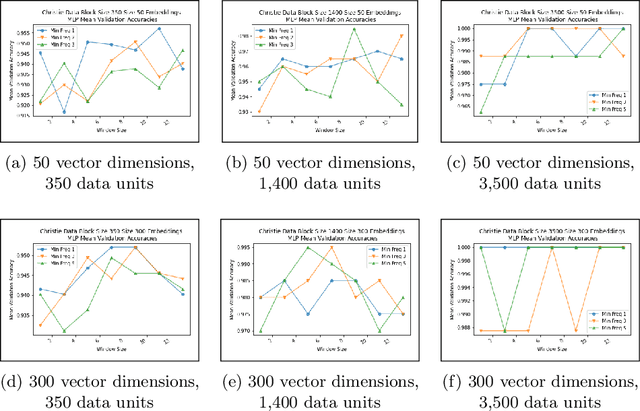

Authorship analysis is an important subject in the field of natural language processing. It allows the detection of the most likely writer of articles, news, books, or messages. This technique has multiple uses in tasks related to authorship attribution, detection of plagiarism, style analysis, sources of misinformation, etc. The focus of this paper is to explore the limitations and sensitiveness of established approaches to adversarial manipulations of inputs. To this end, and using those established techniques, we first developed an experimental frame-work for author detection and input perturbations. Next, we experimentally evaluated the performance of the authorship detection model to a collection of semantic-preserving adversarial perturbations of input narratives. Finally, we compare and analyze the effects of different perturbation strategies, input and model configurations, and the effects of these on the author detection model.
Dynamic data fusion using multi-input models for malware classification
Sep 21, 2019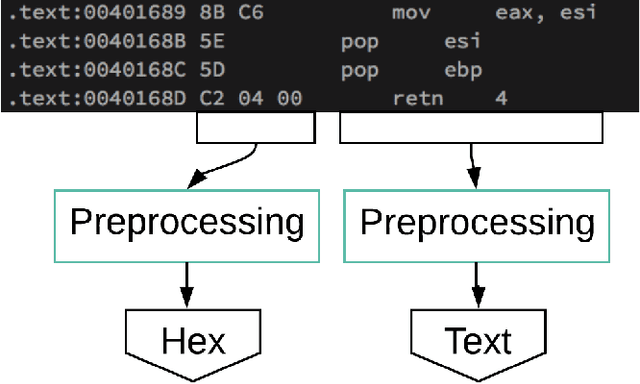



Criminals use malware to disrupt cyber-systems. The number of these malware-vulnerable systems is increasing quickly as common systems, such as vehicles, routers, and lightbulbs, become increasingly interconnected cyber-systems. To address the scale of this problem, analysts divide malware into classes and develop, for each class, a specialized defense. In this project we classified malware with machine learning. In particular, we used a supervised multi-class long short term memory (LSTM) model. We trained the algorithm with thousands of malware files annotated with class labels (the training set), and the algorithm learned patterns indicative of each class. We used disassembled malware files (provided by Microsoft) and separated the constituent data into parsed instructions, which look like human-readable machine code text, and raw bytes, which are hexadecimal values. We are interested in which format, text or hex, is more valuable as input for classification. To solve this, we investigated four cases: a text-only model, a hexadecimal-only model, a multi-input model using both text and hexadecimal inputs, and a model based on combining the individual results. We performed this investigation using the machine learning Python package Keras, which allows easily configurable deep learning architectures and training. We hoped to understand the trade-offs between the different formats. Due to the class imbalance in the data, we used multiple methods to compare the formats, using test accuracies, balanced accuracies (taking into account weights of classes), and an accuracy derived from tables of confusion. We found that the multi-input model, which allows learning on both input types simultaneously, resulted in the best performance. Our finding expedites malware classification research by providing researchers a suitable deep learning architecture to train a tailored version to their malware.