 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic data fusion using multi-input models for malware classification
Sep 21, 2019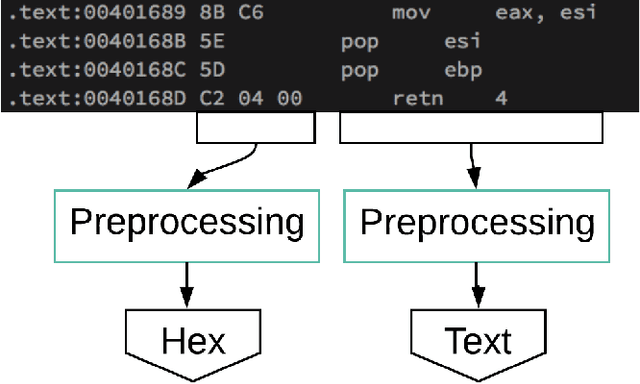



Criminals use malware to disrupt cyber-systems. The number of these malware-vulnerable systems is increasing quickly as common systems, such as vehicles, routers, and lightbulbs, become increasingly interconnected cyber-systems. To address the scale of this problem, analysts divide malware into classes and develop, for each class, a specialized defense. In this project we classified malware with machine learning. In particular, we used a supervised multi-class long short term memory (LSTM) model. We trained the algorithm with thousands of malware files annotated with class labels (the training set), and the algorithm learned patterns indicative of each class. We used disassembled malware files (provided by Microsoft) and separated the constituent data into parsed instructions, which look like human-readable machine code text, and raw bytes, which are hexadecimal values. We are interested in which format, text or hex, is more valuable as input for classification. To solve this, we investigated four cases: a text-only model, a hexadecimal-only model, a multi-input model using both text and hexadecimal inputs, and a model based on combining the individual results. We performed this investigation using the machine learning Python package Keras, which allows easily configurable deep learning architectures and training. We hoped to understand the trade-offs between the different formats. Due to the class imbalance in the data, we used multiple methods to compare the formats, using test accuracies, balanced accuracies (taking into account weights of classes), and an accuracy derived from tables of confusion. We found that the multi-input model, which allows learning on both input types simultaneously, resulted in the best performance. Our finding expedites malware classification research by providing researchers a suitable deep learning architecture to train a tailored version to their malware.
Multi-Level Anomaly Detection on Time-Varying Graph Data
Apr 20, 2015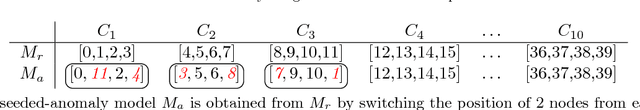
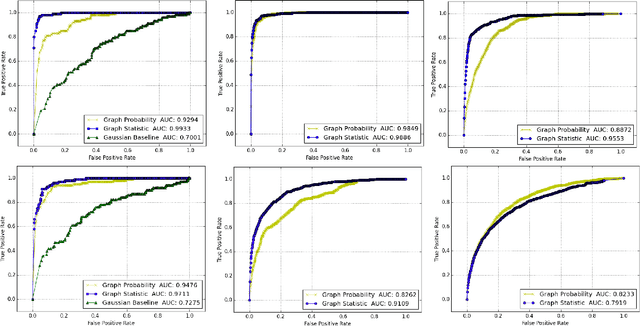
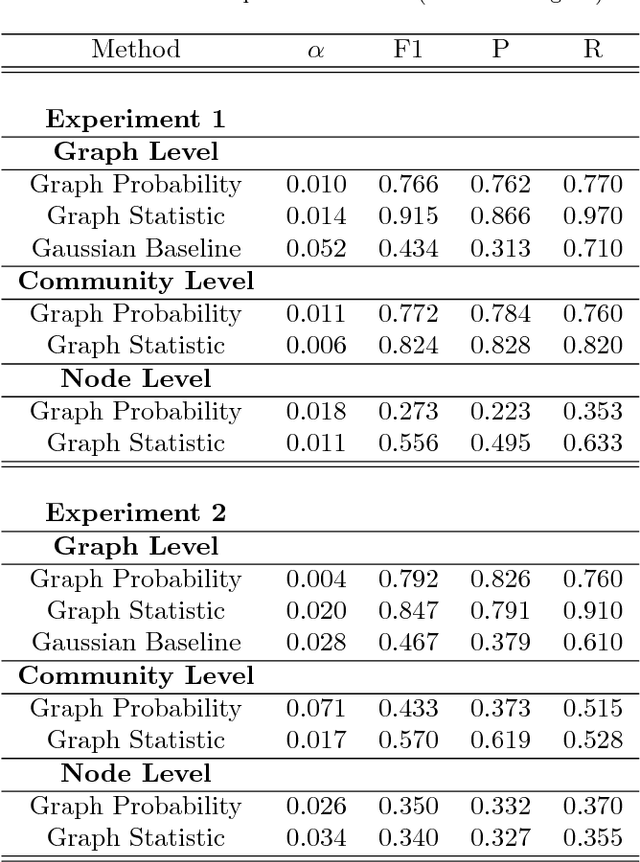

This work presents a novel modeling and analysis framework for graph sequences which addresses the challenge of detecting and contextualizing anomalies in labelled, streaming graph data. We introduce a generalization of the BTER model of Seshadhri et al. by adding flexibility to community structure, and use this model to perform multi-scale graph anomaly detection. Specifically, probability models describing coarse subgraphs are built by aggregating probabilities at finer levels, and these closely related hierarchical models simultaneously detect deviations from expectation. This technique provides insight into a graph's structure and internal context that may shed light on a detected event. Additionally, this multi-scale analysis facilitates intuitive visualizations by allowing users to narrow focus from an anomalous graph to particular subgraphs or nodes causing the anomaly. For evaluation, two hierarchical anomaly detectors are tested against a baseline Gaussian method on a series of sampled graphs. We demonstrate that our graph statistics-based approach outperforms both a distribution-based detector and the baseline in a labeled setting with community structure, and it accurately detects anomalies in synthetic and real-world datasets at the node, subgraph, and graph levels. To illustrate the accessibility of information made possible via this technique, the anomaly detector and an associated interactive visualization tool are tested on NCAA football data, where teams and conferences that moved within the league are identified with perfect recall, and precision greater than 0.786.