 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining neural networks using Metropolis Monte Carlo and an adaptive variant
May 16, 2022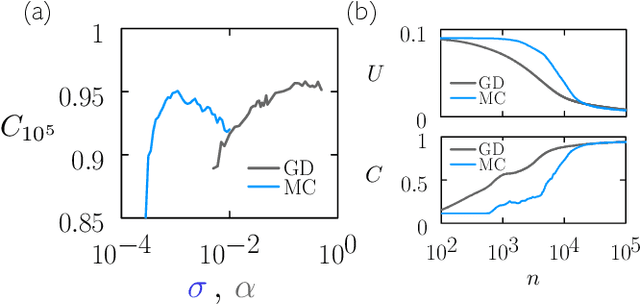
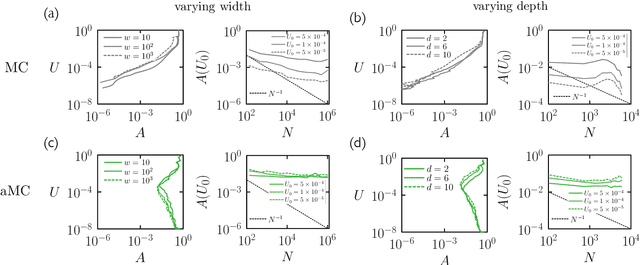
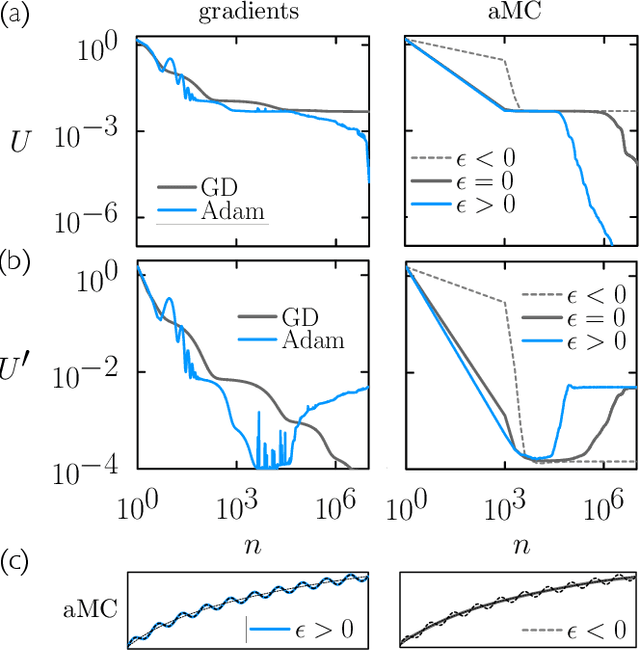
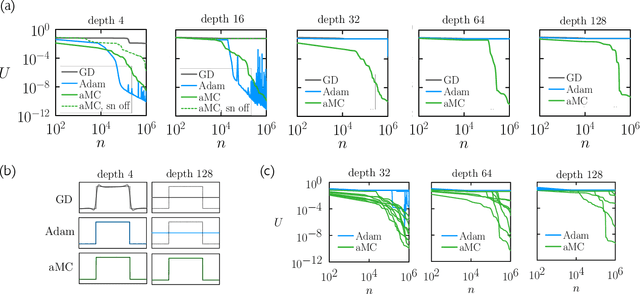
We examine the zero-temperature Metropolis Monte Carlo algorithm as a tool for training a neural network by minimizing a loss function. We find that, as expected on theoretical grounds and shown empirically by other authors, Metropolis Monte Carlo can train a neural net with an accuracy comparable to that of gradient descent, if not necessarily as quickly. The Metropolis algorithm does not fail automatically when the number of parameters of a neural network is large. It can fail when a neural network's structure or neuron activations are strongly heterogenous, and we introduce an adaptive Monte Carlo algorithm, aMC, to overcome these limitations. The intrinsic stochasticity of the Monte Carlo method allows aMC to train neural networks in which the gradient is too small to allow training by gradient descent. We suggest that, as for molecular simulation, Monte Carlo methods offer a complement to gradient-based methods for training neural networks, allowing access to a distinct set of network architectures and principles.
Correspondence between neuroevolution and gradient descent
Aug 15, 2020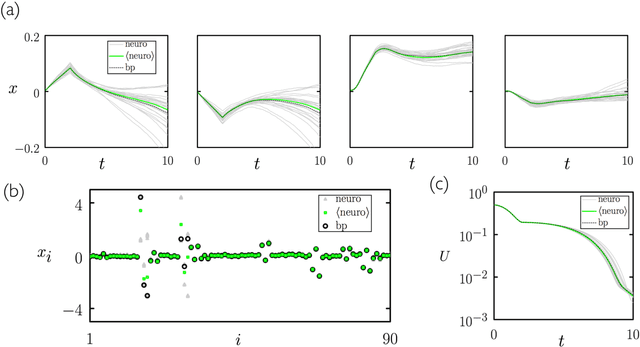
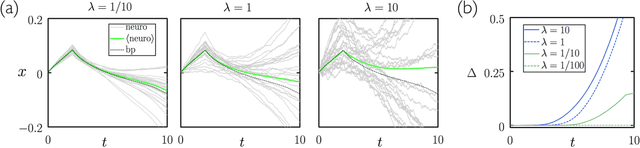
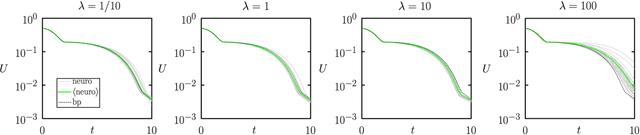
We show analytically that training a neural network by stochastic mutation or "neuroevolution" of its weights is equivalent, in the limit of small mutations, to gradient descent on the loss function in the presence of Gaussian white noise. Averaged over independent realizations of the learning process, neuroevolution is equivalent to gradient descent on the loss function. We use numerical simulation to show that this correspondence can be observed for finite mutations. Our results provide a connection between two distinct types of neural-network training, and provide justification for the empirical success of neuroevolution.