 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Capabilities of Multi-modal Reasoning Models with Synthetic Task Data
Jun 01, 2023The impressive advances and applications of large language and joint language-and-visual understanding models has led to an increased need for methods of probing their potential reasoning capabilities. However, the difficulty of gather naturally-occurring data for complex multi-modal reasoning tasks bottlenecks the evaluation of AI methods on tasks which are not already covered by an academic dataset. In this work, we leverage recent advances in high resolution text-to-image generation to develop a framework for generating evaluation data for multi-modal reasoning tasks. We apply this framework to generate context-dependent anomaly data, creating a synthetic dataset on a challenging task which is not well covered by existing datasets. We benchmark the performance of a state-of-the-art visual question answering (VQA) model against data generated with this method, and demonstrate that while the task is tractable, the model performs significantly worse on the context-dependent anomaly detection task than on standard VQA tasks.
Addressing Discrepancies in Semantic and Visual Alignment in Neural Networks
Jun 01, 2023



For the task of image classification, neural networks primarily rely on visual patterns. In robust networks, we would expect for visually similar classes to be represented similarly. We consider the problem of when semantically similar classes are visually dissimilar, and when visual similarity is present among non-similar classes. We propose a data augmentation technique with the goal of better aligning semantically similar classes with arbitrary (non-visual) semantic relationships. We leverage recent work in diffusion-based semantic mixing to generate semantic hybrids of two classes, and these hybrids are added to the training set as augmented data. We evaluate whether the method increases semantic alignment by evaluating model performance on adversarially perturbed data, with the idea that it should be easier for an adversary to switch one class to a similarly represented class. Results demonstrate that there is an increase in alignment of semantically similar classes when using our proposed data augmentation method.
Addressing Mistake Severity in Neural Networks with Semantic Knowledge
Nov 21, 2022



Robustness in deep neural networks and machine learning algorithms in general is an open research challenge. In particular, it is difficult to ensure algorithmic performance is maintained on out-of-distribution inputs or anomalous instances that cannot be anticipated at training time. Embodied agents will be deployed in these conditions, and are likely to make incorrect predictions. An agent will be viewed as untrustworthy unless it can maintain its performance in dynamic environments. Most robust training techniques aim to improve model accuracy on perturbed inputs; as an alternate form of robustness, we aim to reduce the severity of mistakes made by neural networks in challenging conditions. We leverage current adversarial training methods to generate targeted adversarial attacks during the training process in order to increase the semantic similarity between a model's predictions and true labels of misclassified instances. Results demonstrate that our approach performs better with respect to mistake severity compared to standard and adversarially trained models. We also find an intriguing role that non-robust features play with regards to semantic similarity.
Context-Dependent Anomaly Detection with Knowledge Graph Embedding Models
Mar 19, 2022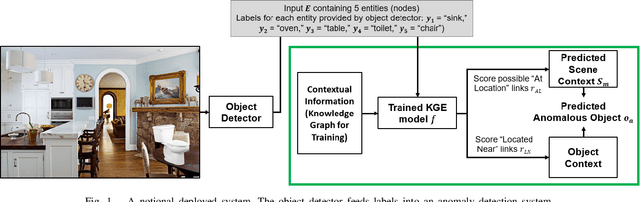
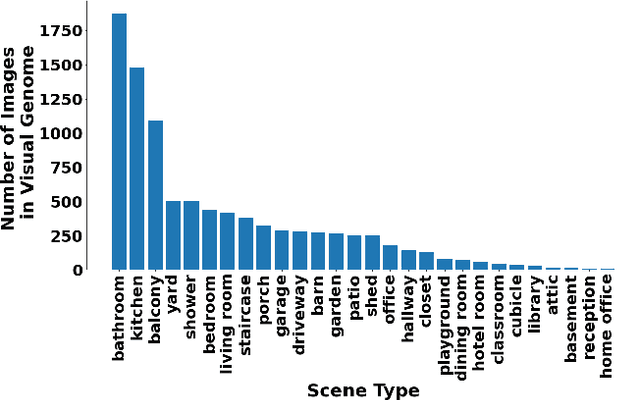
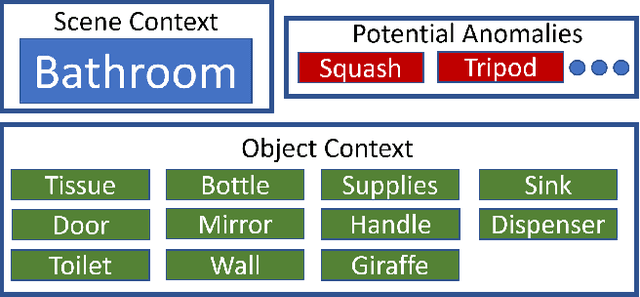
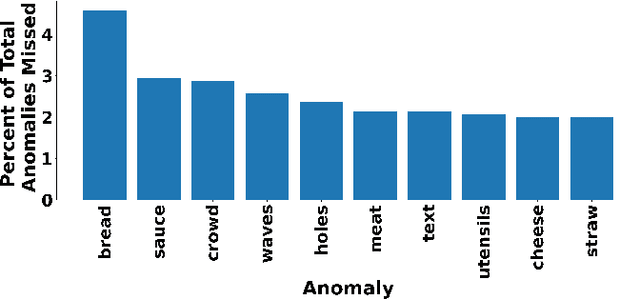
Increasing the semantic understanding and contextual awareness of machine learning models is important for improving robustness and reducing susceptibility to data shifts. In this work, we leverage contextual awareness for the anomaly detection problem. Although graphed-based anomaly detection has been widely studied, context-dependent anomaly detection is an open problem and without much current research. We develop a general framework for converting a context-dependent anomaly detection problem to a link prediction problem, allowing well-established techniques from this domain to be applied. We implement a system based on our framework that utilizes knowledge graph embedding models and demonstrates the ability to detect outliers using context provided by a semantic knowledge base. We show that our method can detect context-dependent anomalies with a high degree of accuracy and show that current object detectors can detect enough classes to provide the needed context for good performance within our example domain.
Fast Training of Deep Neural Networks Robust to Adversarial Perturbations
Jul 08, 2020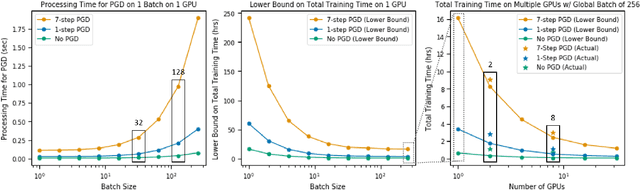
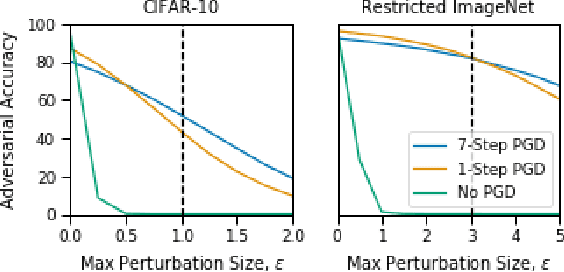


Deep neural networks are capable of training fast and generalizing well within many domains. Despite their promising performance, deep networks have shown sensitivities to perturbations of their inputs (e.g., adversarial examples) and their learned feature representations are often difficult to interpret, raising concerns about their true capability and trustworthiness. Recent work in adversarial training, a form of robust optimization in which the model is optimized against adversarial examples, demonstrates the ability to improve performance sensitivities to perturbations and yield feature representations that are more interpretable. Adversarial training, however, comes with an increased computational cost over that of standard (i.e., nonrobust) training, rendering it impractical for use in large-scale problems. Recent work suggests that a fast approximation to adversarial training shows promise for reducing training time and maintaining robustness in the presence of perturbations bounded by the infinity norm. In this work, we demonstrate that this approach extends to the Euclidean norm and preserves the human-aligned feature representations that are common for robust models. Additionally, we show that using a distributed training scheme can further reduce the time to train robust deep networks. Fast adversarial training is a promising approach that will provide increased security and explainability in machine learning applications for which robust optimization was previously thought to be impractical.