 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotically optimal regret in communicating Markov decision processes
May 23, 2025In this paper, we present a learning algorithm that achieves asymptotically optimal regret for Markov decision processes in average reward under a communicating assumption. That is, given a communicating Markov decision process $M$, our algorithm has regret $K(M) \log(T) + \mathrm{o}(\log(T))$ where $T$ is the number of learning steps and $K(M)$ is the best possible constant. This algorithm works by explicitly tracking the constant $K(M)$ to learn optimally, then balances the trade-off between exploration (playing sub-optimally to gain information), co-exploration (playing optimally to gain information) and exploitation (playing optimally to score maximally). We further show that the function $K(M)$ is discontinuous, which is a consequence challenge for our approach. To that end, we describe a regularization mechanism to estimate $K(M)$ with arbitrary precision from empirical data.
Logarithmic Regret of Exploration in Average Reward Markov Decision Processes
Feb 10, 2025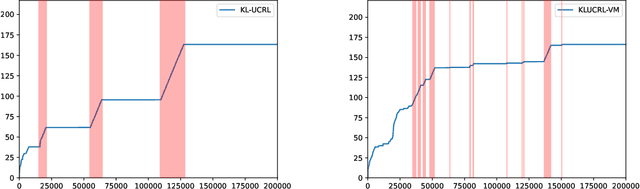
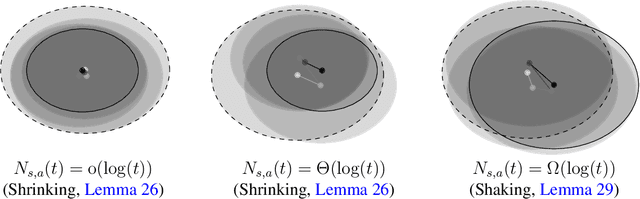
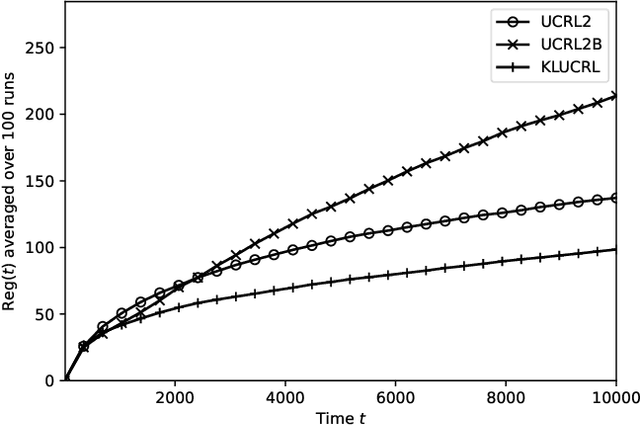
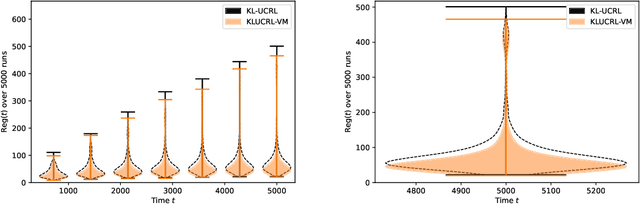
In average reward Markov decision processes, state-of-the-art algorithms for regret minimization follow a well-established framework: They are model-based, optimistic and episodic. First, they maintain a confidence region from which optimistic policies are computed using a well-known subroutine called Extended Value Iteration (EVI). Second, these policies are used over time windows called episodes, each ended by the Doubling Trick (DT) rule or a variant thereof. In this work, without modifying EVI, we show that there is a significant advantage in replacing (DT) by another simple rule, that we call the Vanishing Multiplicative (VM) rule. When managing episodes with (VM), the algorithm's regret is, both in theory and in practice, as good if not better than with (DT), while the one-shot behavior is greatly improved. More specifically, the management of bad episodes (when sub-optimal policies are being used) is much better under (VM) than (DT) by making the regret of exploration logarithmic rather than linear. These results are made possible by a new in-depth understanding of the contrasting behaviors of confidence regions during good and bad episodes.
Achieving Tractable Minimax Optimal Regret in Average Reward MDPs
Jun 03, 2024In recent years, significant attention has been directed towards learning average-reward Markov Decision Processes (MDPs). However, existing algorithms either suffer from sub-optimal regret guarantees or computational inefficiencies. In this paper, we present the first tractable algorithm with minimax optimal regret of $\widetilde{\mathrm{O}}(\sqrt{\mathrm{sp}(h^*) S A T})$, where $\mathrm{sp}(h^*)$ is the span of the optimal bias function $h^*$, $S \times A$ is the size of the state-action space and $T$ the number of learning steps. Remarkably, our algorithm does not require prior information on $\mathrm{sp}(h^*)$. Our algorithm relies on a novel subroutine, Projected Mitigated Extended Value Iteration (PMEVI), to compute bias-constrained optimal policies efficiently. This subroutine can be applied to various previous algorithms to improve regret bounds.
The Sliding Regret in Stochastic Bandits: Discriminating Index and Randomized Policies
Nov 30, 2023This paper studies the one-shot behavior of no-regret algorithms for stochastic bandits. Although many algorithms are known to be asymptotically optimal with respect to the expected regret, over a single run, their pseudo-regret seems to follow one of two tendencies: it is either smooth or bumpy. To measure this tendency, we introduce a new notion: the sliding regret, that measures the worst pseudo-regret over a time-window of fixed length sliding to infinity. We show that randomized methods (e.g. Thompson Sampling and MED) have optimal sliding regret, while index policies, although possibly asymptotically optimal for the expected regret, have the worst possible sliding regret under regularity conditions on their index (e.g. UCB, UCB-V, KL-UCB, MOSS, IMED etc.). We further analyze the average bumpiness of the pseudo-regret of index policies via the regret of exploration, that we show to be suboptimal as well.
The equivalence of dynamic and strategic stability under regularized learning in games
Nov 04, 2023


In this paper, we examine the long-run behavior of regularized, no-regret learning in finite games. A well-known result in the field states that the empirical frequencies of no-regret play converge to the game's set of coarse correlated equilibria; however, our understanding of how the players' actual strategies evolve over time is much more limited - and, in many cases, non-existent. This issue is exacerbated further by a series of recent results showing that only strict Nash equilibria are stable and attracting under regularized learning, thus making the relation between learning and pointwise solution concepts particularly elusive. In lieu of this, we take a more general approach and instead seek to characterize the \emph{setwise} rationality properties of the players' day-to-day play. To that end, we focus on one of the most stringent criteria of setwise strategic stability, namely that any unilateral deviation from the set in question incurs a cost to the deviator - a property known as closedness under better replies (club). In so doing, we obtain a far-reaching equivalence between strategic and dynamic stability: a product of pure strategies is closed under better replies if and only if its span is stable and attracting under regularized learning. In addition, we estimate the rate of convergence to such sets, and we show that methods based on entropic regularization (like the exponential weights algorithm) converge at a geometric rate, while projection-based methods converge within a finite number of iterations, even with bandit, payoff-based feedback.