 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle-transfer and Paraphrase: Looking for a Sensible Semantic Similarity Metric
Apr 10, 2020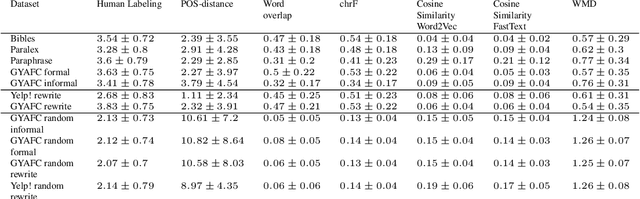
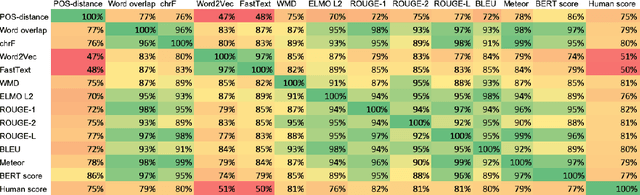
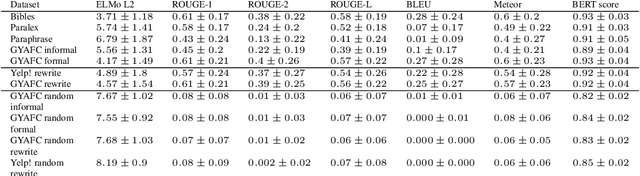
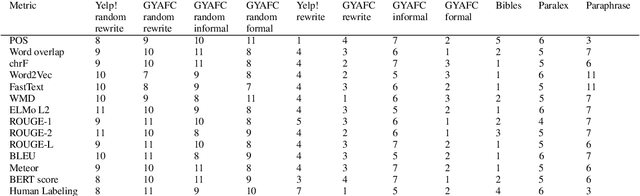
The rapid development of such natural language processing tasks as style transfer, paraphrase, and machine translation often calls for the use of semantic preservation metrics. In recent years a lot of methods to control the semantic similarity of two short texts were developed. This paper provides a comprehensive analysis for more than a dozen of such methods. Using a new dataset of fourteen thousand sentence pairs human-labeled according to their semantic similarity, we demonstrate that none of the metrics widely used in the literature is close enough to human judgment to be used on its own in these tasks. The recently proposed Word Mover's Distance (WMD), along with bilingual evaluation understudy (BLEU) and part-of-speech (POS) distance, seem to form a reasonable complex solution to measure semantic preservation in reformulated texts. We encourage the research community to use the ensemble of these metrics until a better solution is found.
Decomposing Textual Information For Style Transfer
Sep 26, 2019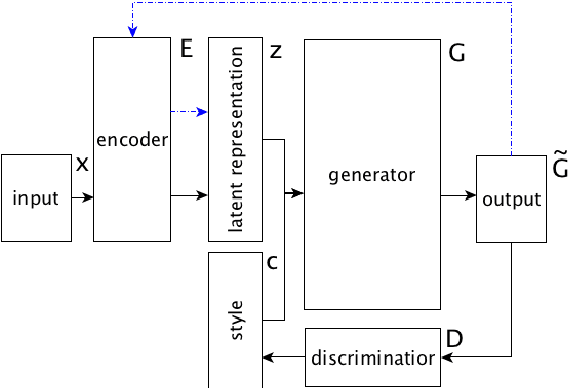
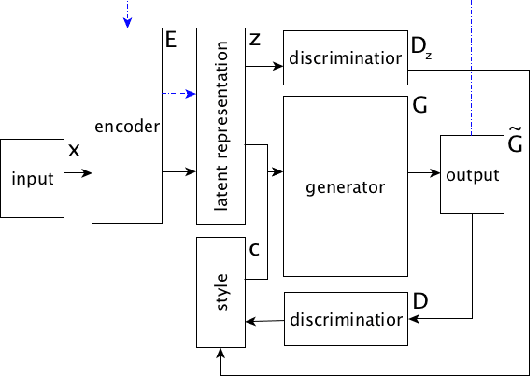
This paper focuses on latent representations that could effectively decompose different aspects of textual information. Using a framework of style transfer for texts, we propose several empirical methods to assess information decomposition quality. We validate these methods with several state-of-the-art textual style transfer methods. Higher quality of information decomposition corresponds to higher performance in terms of bilingual evaluation understudy (BLEU) between output and human-written reformulations.
Style Transfer for Texts: Retrain, Report Errors, Compare with Rewrites
Aug 29, 2019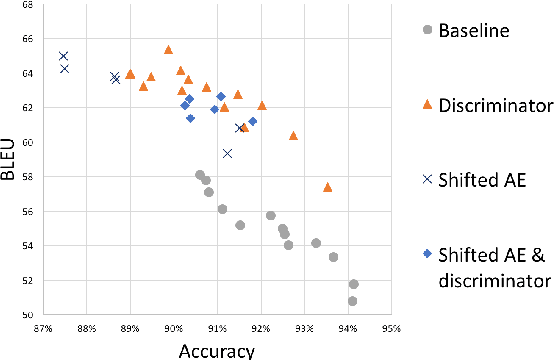
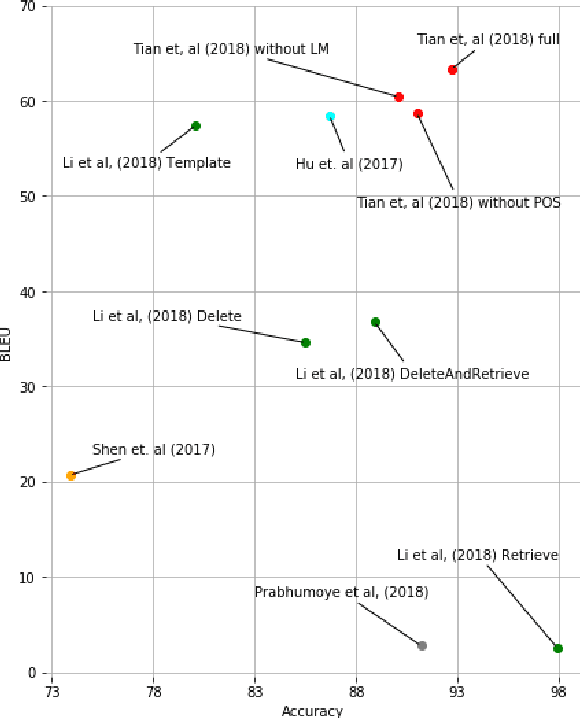
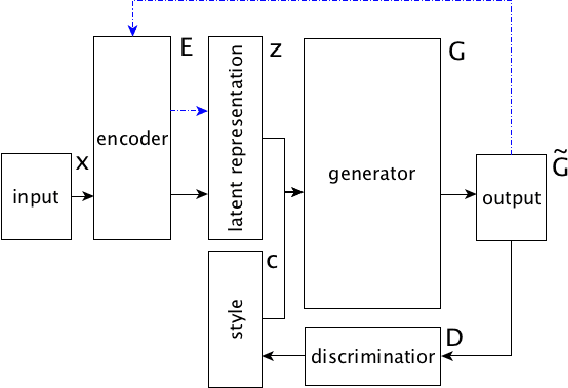
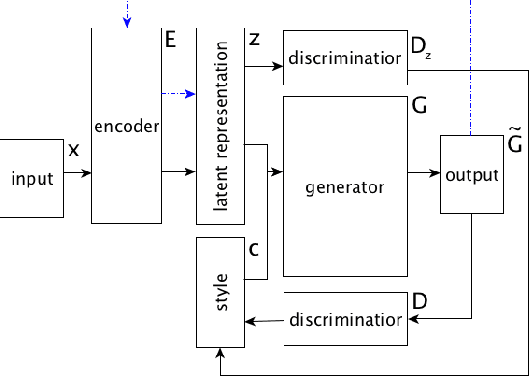
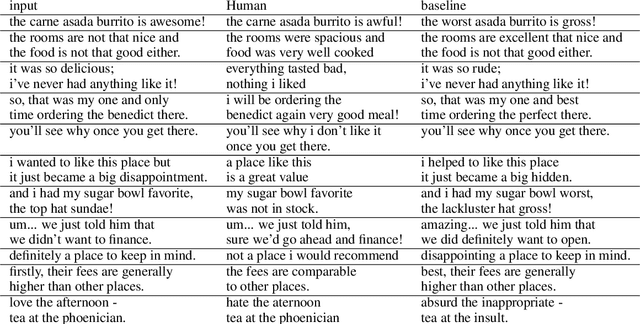
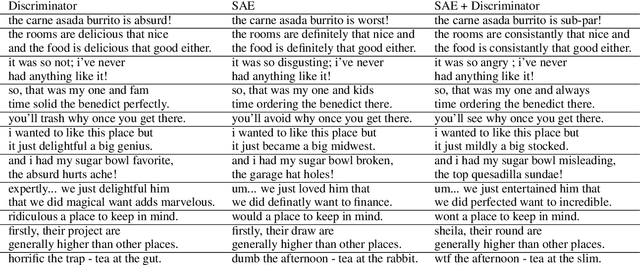
This paper shows that standard assessment methodology for style transfer has several significant problems. First, the standard metrics for style accuracy and semantics preservation vary significantly on different re-runs. Therefore one has to report error margins for the obtained results. Second, starting with certain values of bilingual evaluation understudy (BLEU) between input and output and accuracy of the sentiment transfer the optimization of these two standard metrics diverge from the intuitive goal of the style transfer task. Finally, due to the nature of the task itself, there is a specific dependence between these two metrics that could be easily manipulated. Under these circumstances, we suggest taking BLEU between input and human-written reformulations into consideration for benchmarks. We also propose three new architectures that outperform state of the art in terms of this metric.