 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle-transfer and Paraphrase: Looking for a Sensible Semantic Similarity Metric
Paper and Code
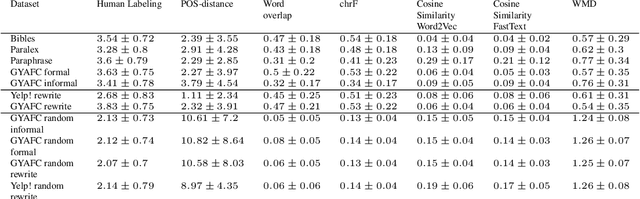
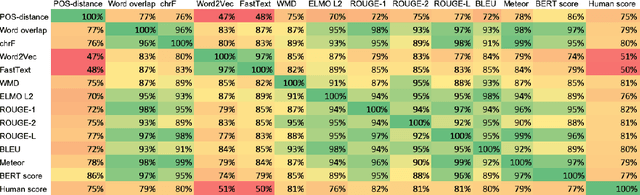
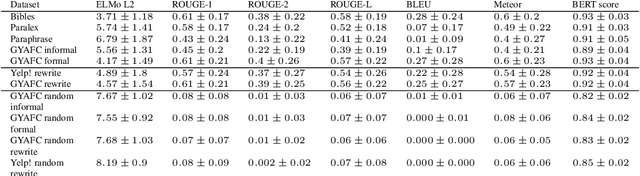
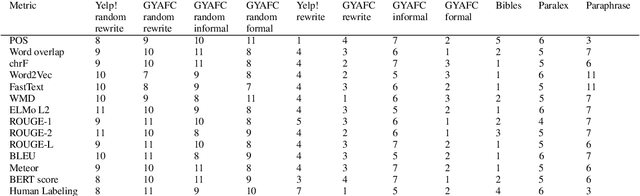
The rapid development of such natural language processing tasks as style transfer, paraphrase, and machine translation often calls for the use of semantic preservation metrics. In recent years a lot of methods to control the semantic similarity of two short texts were developed. This paper provides a comprehensive analysis for more than a dozen of such methods. Using a new dataset of fourteen thousand sentence pairs human-labeled according to their semantic similarity, we demonstrate that none of the metrics widely used in the literature is close enough to human judgment to be used on its own in these tasks. The recently proposed Word Mover's Distance (WMD), along with bilingual evaluation understudy (BLEU) and part-of-speech (POS) distance, seem to form a reasonable complex solution to measure semantic preservation in reformulated texts. We encourage the research community to use the ensemble of these metrics until a better solution is found.