 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimation of Food Intake Quantity Using Inertial Signals from Smartwatches
Feb 10, 2025Accurate monitoring of eating behavior is crucial for managing obesity and eating disorders such as bulimia nervosa. At the same time, existing methods rely on multiple and/or specialized sensors, greatly harming adherence and ultimately, the quality and continuity of data. This paper introduces a novel approach for estimating the weight of a bite, from a commercial smartwatch. Our publicly-available dataset contains smartwatch inertial data from ten participants, with manually annotated start and end times of each bite along with their corresponding weights from a smart scale, under semi-controlled conditions. The proposed method combines extracted behavioral features such as the time required to load the utensil with food, with statistical features of inertial signals, that serve as input to a Support Vector Regression model to estimate bite weights. Under a leave-one-subject-out cross-validation scheme, our approach achieves a mean absolute error (MAE) of 3.99 grams per bite. To contextualize this performance, we introduce the improvement metric, that measures the relative MAE difference compared to a baseline model. Our method demonstrates a 17.41% improvement, while the adapted state-of-the art method shows a -28.89% performance against that same baseline. The results presented in this work establish the feasibility of extracting meaningful bite weight estimates from commercial smartwatch inertial sensors alone, laying the groundwork for future accessible, non-invasive dietary monitoring systems.
Prediabetes detection in unconstrained conditions using wearable sensors
Oct 03, 2024Prediabetes is a common health condition that often goes undetected until it progresses to type 2 diabetes. Early identification of prediabetes is essential for timely intervention and prevention of complications. This research explores the feasibility of using wearable continuous glucose monitoring along with smartwatches with embedded inertial sensors to collect glucose measurements and acceleration signals respectively, for the early detection of prediabetes. We propose a methodology based on signal processing and machine learning techniques. Two feature sets are extracted from the collected signals, based both on a dynamic modeling of the human glucose-homeostasis system and on the Glucose curve, inspired by three major glucose related blood tests. Features are aggregated per individual using bootstrap. Support Vector Machines are used to classify normoglycemic vs. prediabetic individuals. We collected data from 22 participants for evaluation. The results are highly encouraging, demonstrating high sensitivity and precision. This work is a proof of concept, highlighting the potential of wearable devices in prediabetes assessment. Future directions involve expanding the study to a larger, more diverse population and exploring the integration of CGM and smartwatch functionalities into a unified device. Automated eating detecting algorithms can also be used.
On the Out-Of-Distribution Robustness of Self-Supervised Representation Learning for Phonocardiogram Signals
Dec 01, 2023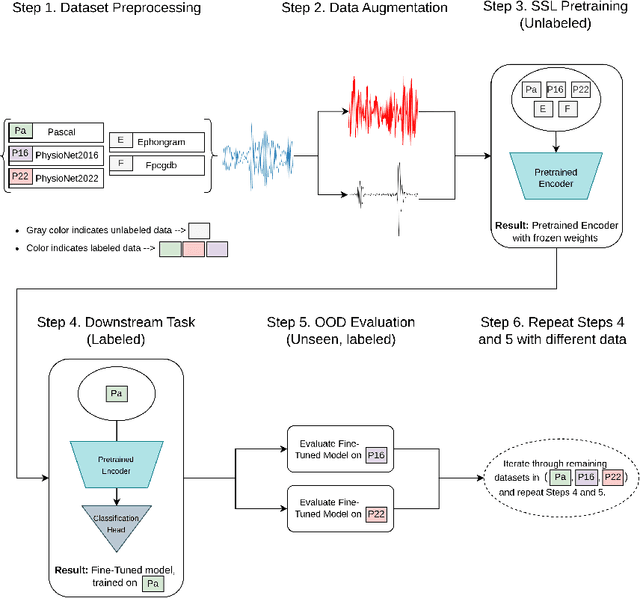
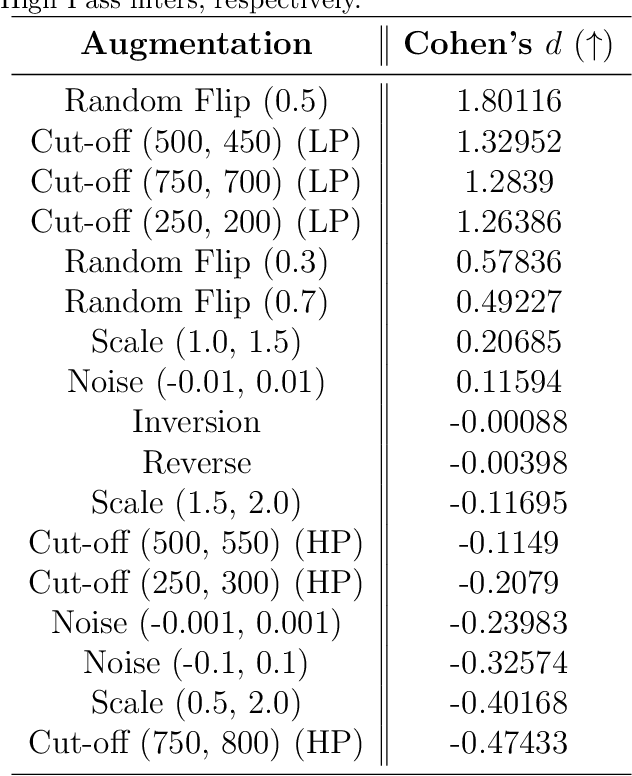
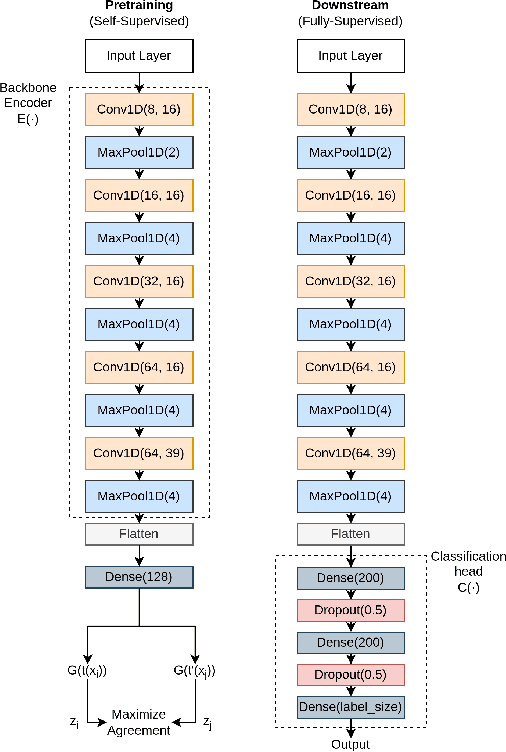
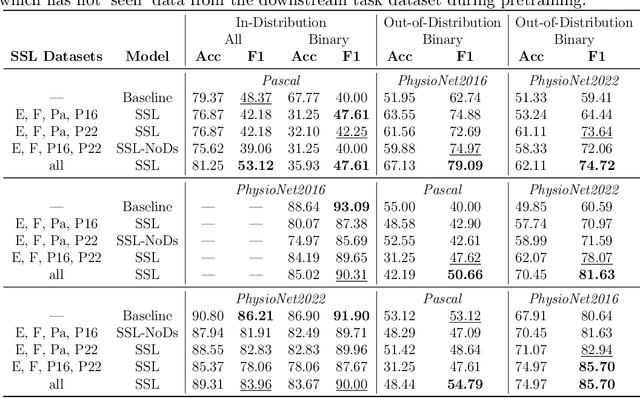
Objective: Despite the recent increase in research activity, deep-learning models have not yet been widely accepted in medicine. The shortage of high-quality annotated data often hinders the development of robust and generalizable models, which do not suffer from degraded effectiveness when presented with newly-collected, out-of-distribution (OOD) datasets. Methods: Contrastive Self-Supervised Learning (SSL) offers a potential solution to the scarcity of labeled data as it takes advantage of unlabeled data to increase model effectiveness and robustness. In this research, we propose applying contrastive SSL for detecting abnormalities in phonocardiogram (PCG) samples by learning a generalized representation of the signal. Specifically, we perform an extensive comparative evaluation of a wide range of audio-based augmentations and evaluate trained classifiers on multiple datasets across different downstream tasks. Results: We experimentally demonstrate that, depending on its training distribution, the effectiveness of a fully-supervised model can degrade up to 32% when evaluated on unseen data, while SSL models only lose up to 10% or even improve in some cases. Conclusions: Contrastive SSL pretraining can assist in providing robust classifiers which can generalize to unseen, OOD data, without relying on time- and labor-intensive annotation processes by medical experts. Furthermore, the proposed extensive evaluation protocol sheds light on the most promising and appropriate augmentations for robust PCG signal processing. Significance: We provide researchers and practitioners with a roadmap towards producing robust models for PCG classification, in addition to an open-source codebase for developing novel approaches.
Listen to your heart: A self-supervised approach for detecting murmur in heart-beat sounds for the Physionet 2022 challenge
Aug 31, 2022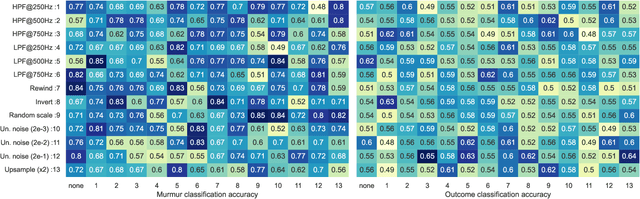
Heart murmurs are abnormal sounds present in heartbeats, caused by turbulent blood flow through the heart. The PhysioNet 2022 challenge targets automatic detection of murmur from audio recordings of the heart and automatic detection of normal vs. abnormal clinical outcome. The recordings are captured from multiple locations around the heart. Our participation investigates the effectiveness of self-supervised learning for murmur detection. We evaluate the use of a backbone CNN, whose layers are trained in a self-supervised way with data from both this year's and the 2016 challenge. We use two different augmentations on each training sample, and normalized temperature-scaled cross-entropy loss. We experiment with different augmentations to learn effective phonocardiogram representations. To build the final detectors we train two classification heads, one for each challenge task. We present evaluation results for all combinations of the available augmentations, and for our multiple-augmentation approach.
Chewing Detection from Commercial Smart-glasses
Aug 11, 2022
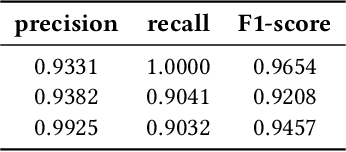
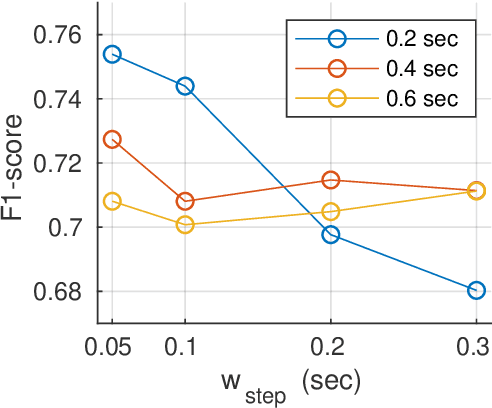
Automatic dietary monitoring has progressed significantly during the last years, offering a variety of solutions, both in terms of sensors and algorithms as well as in terms of what aspect or parameters of eating behavior are measured and monitored. Automatic detection of eating based on chewing sounds has been studied extensively, however, it requires a microphone to be mounted on the subject's head for capturing the relevant sounds. In this work, we evaluate the feasibility of using an off-the-shelf commercial device, the Razer Anzu smart-glasses, for automatic chewing detection. The smart-glasses are equipped with stereo speakers and microphones that communicate with smart-phones via Bluetooth. The microphone placement is not optimal for capturing chewing sounds, however, we find that it does not significantly affect the detection effectiveness. We apply an algorithm from literature with some adjustments on a challenging dataset that we have collected in house. Leave-one-subject-out experiments yield promising results, with an F1-score of 0.96 for the best case of duration-based evaluation of eating time.
* 6 pages, 4 figures, 1 table, conference
Intake Monitoring in Free-Living Conditions: Overview and Lessons we Have Learned
Jun 04, 2022
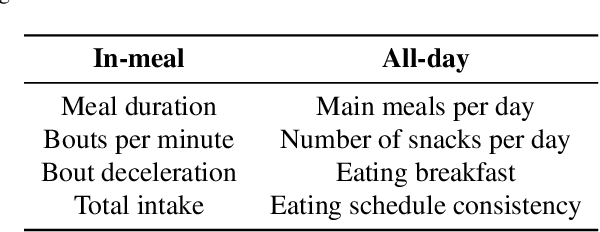
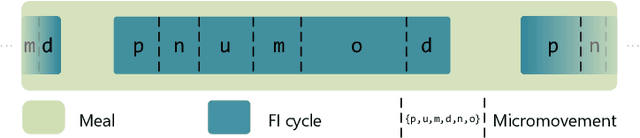

The progress in artificial intelligence and machine learning algorithms over the past decade has enabled the development of new methods for the objective measurement of eating, including both the measurement of eating episodes as well as the measurement of in-meal eating behavior. These allow the study of eating behavior outside the laboratory in free-living conditions, without the need for video recordings and laborious manual annotations. In this paper, we present a high-level overview of our recent work on intake monitoring using a smartwatch, as well as methods using an in-ear microphone. We also present evaluation results of these methods in challenging, real-world datasets. Furthermore, we discuss use-cases of such intake monitoring tools for advancing research in eating behavior, for improving dietary monitoring, as well as for developing evidence-based health policies. Our goal is to inform researchers and users of intake monitoring methods regarding (i) the development of new methods based on commercially available devices, (ii) what to expect in terms of effectiveness, and (iii) how these methods can be used in research as well as in practical applications.
Self-Supervised Feature Learning of 1D Convolutional Neural Networks with Contrastive Loss for Eating Detection Using an In-Ear Microphone
Aug 03, 2021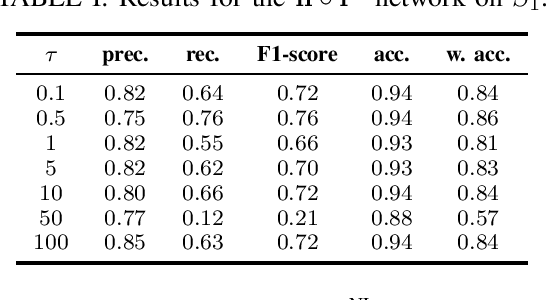
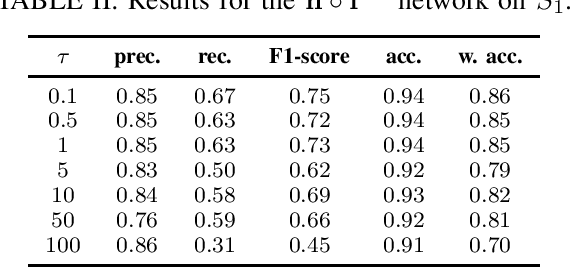
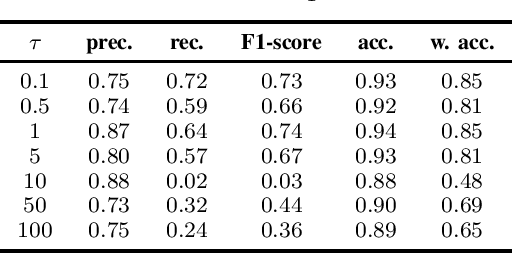
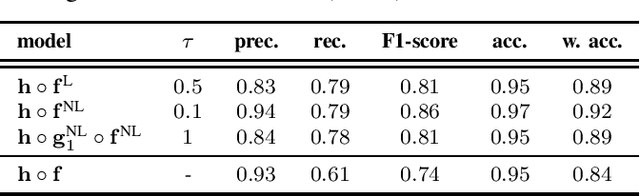
The importance of automated and objective monitoring of dietary behavior is becoming increasingly accepted. The advancements in sensor technology along with recent achievements in machine-learning--based signal-processing algorithms have enabled the development of dietary monitoring solutions that yield highly accurate results. A common bottleneck for developing and training machine learning algorithms is obtaining labeled data for training supervised algorithms, and in particular ground truth annotations. Manual ground truth annotation is laborious, cumbersome, can sometimes introduce errors, and is sometimes impossible in free-living data collection. As a result, there is a need to decrease the labeled data required for training. Additionally, unlabeled data, gathered in-the-wild from existing wearables (such as Bluetooth earbuds) can be used to train and fine-tune eating-detection models. In this work, we focus on training a feature extractor for audio signals captured by an in-ear microphone for the task of eating detection in a self-supervised way. We base our approach on the SimCLR method for image classification, proposed by Chen et al. from the domain of computer vision. Results are promising as our self-supervised method achieves similar results to supervised training alternatives, and its overall effectiveness is comparable to current state-of-the-art methods. Code is available at https://github.com/mug-auth/ssl-chewing .
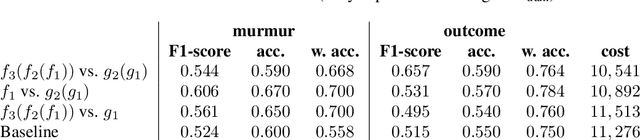
Bite-Weight Estimation Using Commercial Ear Buds
Aug 02, 2021
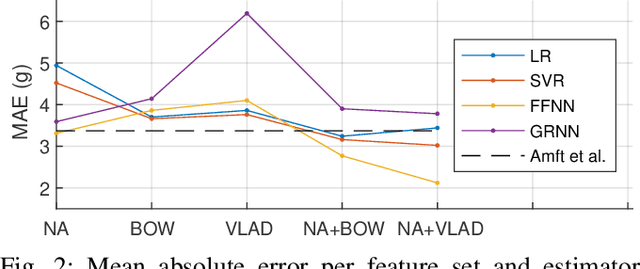
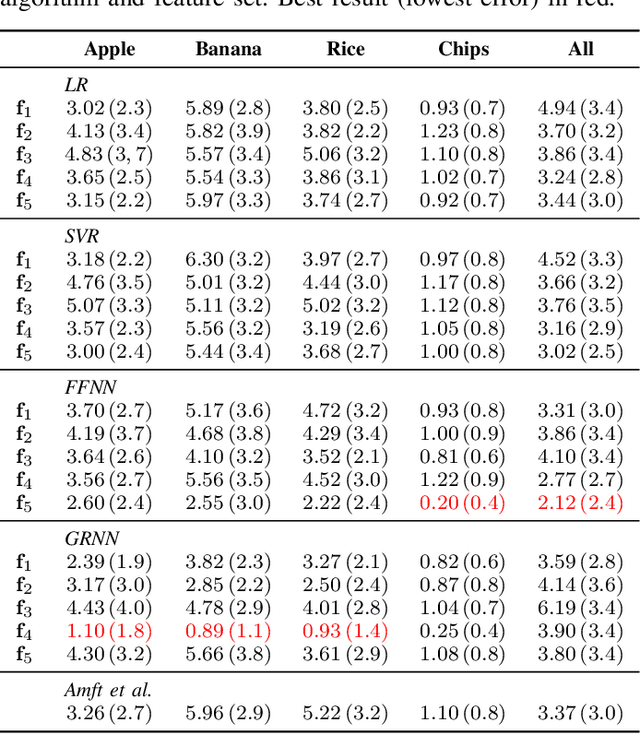
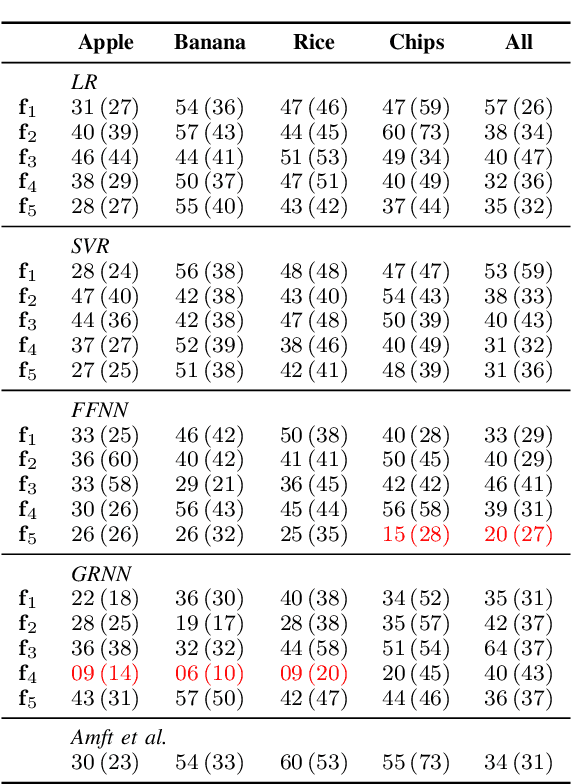
While automatic tracking and measuring of our physical activity is a well established domain, not only in research but also in commercial products and every-day life-style, automatic measurement of eating behavior is significantly more limited. Despite the abundance of methods and algorithms that are available in bibliography, commercial solutions are mostly limited to digital logging applications for smart-phones. One factor that limits the adoption of such solutions is that they usually require specialized hardware or sensors. Based on this, we evaluate the potential for estimating the weight of consumed food (per bite) based only on the audio signal that is captured by commercial ear buds (Samsung Galaxy Buds). Specifically, we examine a combination of features (both audio and non-audio features) and trainable estimators (linear regression, support vector regression, and neural-network based estimators) and evaluate on an in-house dataset of 8 participants and 4 food types. Results indicate good potential for this approach: our best results yield mean absolute error of less than 1 g for 3 out of 4 food types when training food-specific models, and 2.1 g when training on all food types together, both of which improve over an existing literature approach.
Recognition of food-texture attributes using an in-ear microphone
May 20, 2021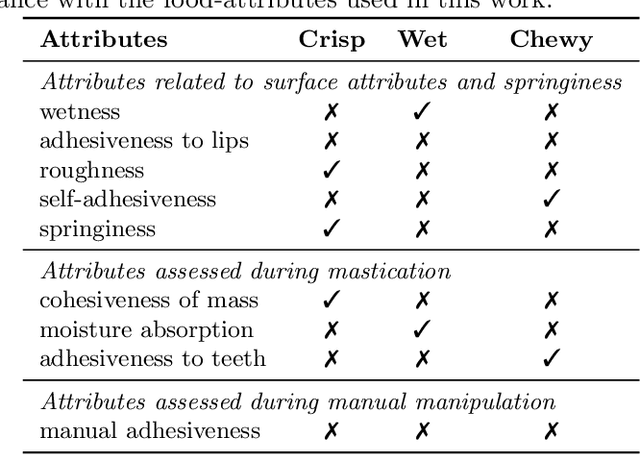
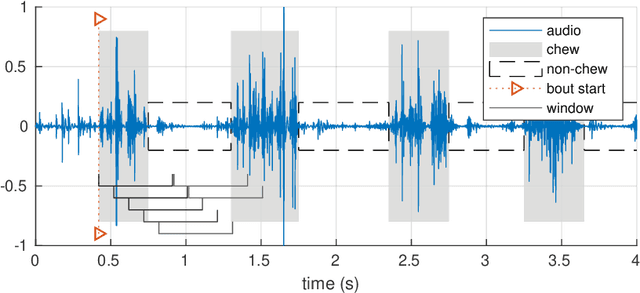

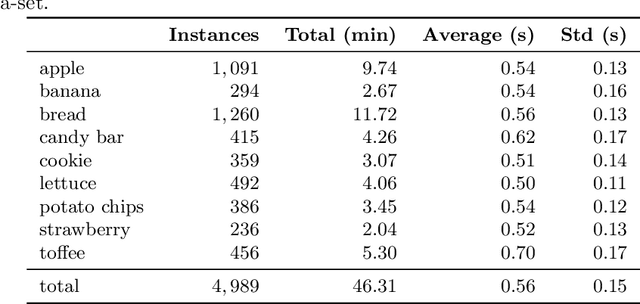
Food texture is a complex property; various sensory attributes such as perceived crispiness and wetness have been identified as ways to quantify it. Objective and automatic recognition of these attributes has applications in multiple fields, including health sciences and food engineering. In this work we use an in-ear microphone, commonly used for chewing detection, and propose algorithms for recognizing three food-texture attributes, specifically crispiness, wetness (moisture), and chewiness. We use binary SVMs, one for each attribute, and propose two algorithms: one that recognizes each texture attribute at the chew level and one at the chewing-bout level. We evaluate the proposed algorithms using leave-one-subject-out cross-validation on a dataset with 9 subjects. We also evaluate them using leave-one-food-type-out cross-validation, in order to examine the generalization of our approach to new, unknown food types. Our approach performs very well in recognizing crispiness (0.95 weighted accuracy on new subjects and 0.93 on new food types) and demonstrates promising results for objective and automatic recognition of wetness and chewiness.