 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Out-Of-Distribution Robustness of Self-Supervised Representation Learning for Phonocardiogram Signals
Paper and Code
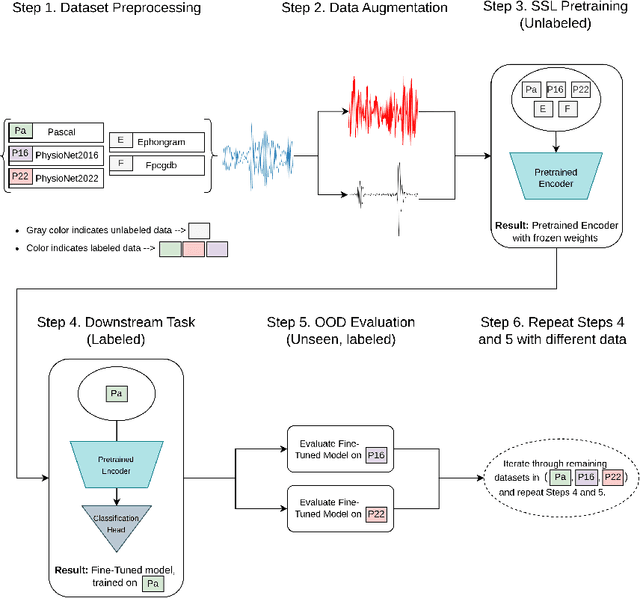
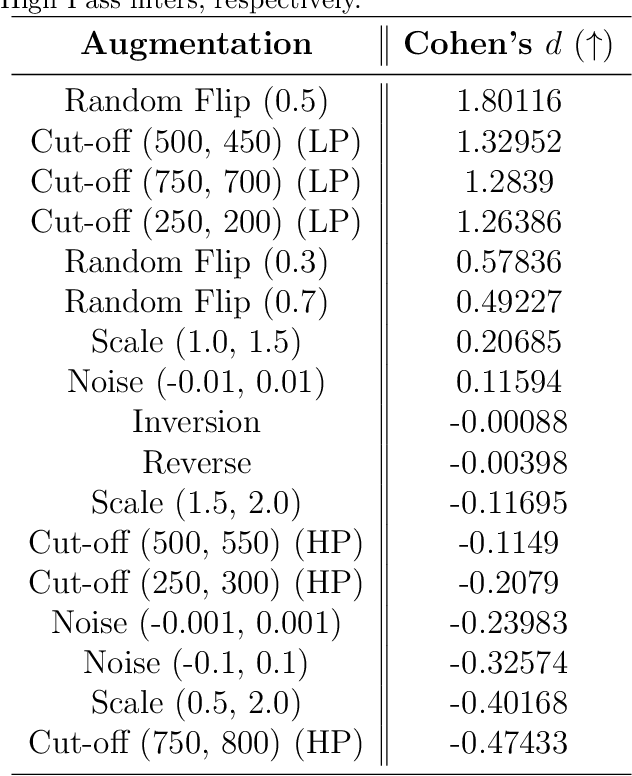
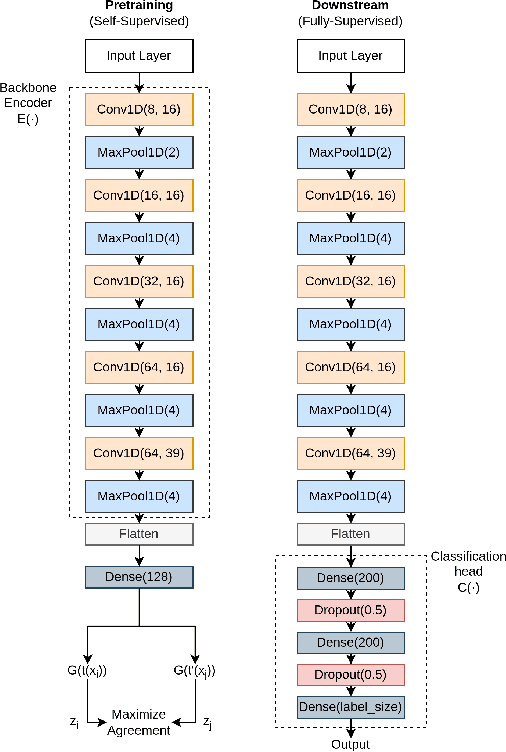
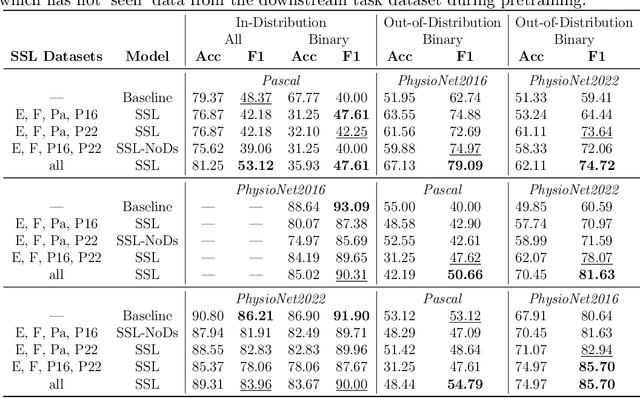
Objective: Despite the recent increase in research activity, deep-learning models have not yet been widely accepted in medicine. The shortage of high-quality annotated data often hinders the development of robust and generalizable models, which do not suffer from degraded effectiveness when presented with newly-collected, out-of-distribution (OOD) datasets. Methods: Contrastive Self-Supervised Learning (SSL) offers a potential solution to the scarcity of labeled data as it takes advantage of unlabeled data to increase model effectiveness and robustness. In this research, we propose applying contrastive SSL for detecting abnormalities in phonocardiogram (PCG) samples by learning a generalized representation of the signal. Specifically, we perform an extensive comparative evaluation of a wide range of audio-based augmentations and evaluate trained classifiers on multiple datasets across different downstream tasks. Results: We experimentally demonstrate that, depending on its training distribution, the effectiveness of a fully-supervised model can degrade up to 32% when evaluated on unseen data, while SSL models only lose up to 10% or even improve in some cases. Conclusions: Contrastive SSL pretraining can assist in providing robust classifiers which can generalize to unseen, OOD data, without relying on time- and labor-intensive annotation processes by medical experts. Furthermore, the proposed extensive evaluation protocol sheds light on the most promising and appropriate augmentations for robust PCG signal processing. Significance: We provide researchers and practitioners with a roadmap towards producing robust models for PCG classification, in addition to an open-source codebase for developing novel approaches.