 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFood Image Classification and Segmentation with Attention-based Multiple Instance Learning
Aug 22, 2023The demand for accurate food quantification has increased in the recent years, driven by the needs of applications in dietary monitoring. At the same time, computer vision approaches have exhibited great potential in automating tasks within the food domain. Traditionally, the development of machine learning models for these problems relies on training data sets with pixel-level class annotations. However, this approach introduces challenges arising from data collection and ground truth generation that quickly become costly and error-prone since they must be performed in multiple settings and for thousands of classes. To overcome these challenges, the paper presents a weakly supervised methodology for training food image classification and semantic segmentation models without relying on pixel-level annotations. The proposed methodology is based on a multiple instance learning approach in combination with an attention-based mechanism. At test time, the models are used for classification and, concurrently, the attention mechanism generates semantic heat maps which are used for food class segmentation. In the paper, we conduct experiments on two meta-classes within the FoodSeg103 data set to verify the feasibility of the proposed approach and we explore the functioning properties of the attention mechanism.
Intake Monitoring in Free-Living Conditions: Overview and Lessons we Have Learned
Jun 04, 2022
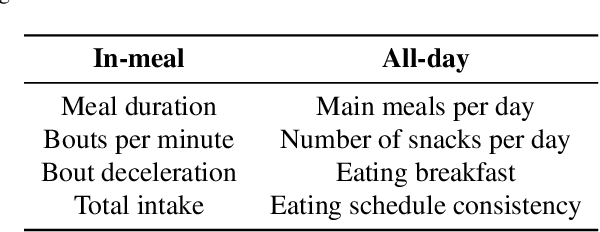
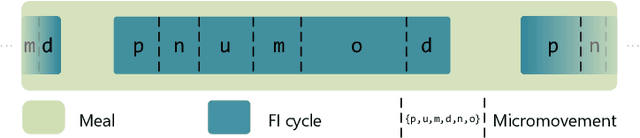

The progress in artificial intelligence and machine learning algorithms over the past decade has enabled the development of new methods for the objective measurement of eating, including both the measurement of eating episodes as well as the measurement of in-meal eating behavior. These allow the study of eating behavior outside the laboratory in free-living conditions, without the need for video recordings and laborious manual annotations. In this paper, we present a high-level overview of our recent work on intake monitoring using a smartwatch, as well as methods using an in-ear microphone. We also present evaluation results of these methods in challenging, real-world datasets. Furthermore, we discuss use-cases of such intake monitoring tools for advancing research in eating behavior, for improving dietary monitoring, as well as for developing evidence-based health policies. Our goal is to inform researchers and users of intake monitoring methods regarding (i) the development of new methods based on commercially available devices, (ii) what to expect in terms of effectiveness, and (iii) how these methods can be used in research as well as in practical applications.
Span error bound for weighted SVM with applications in hyperparameter selection
Sep 17, 2018
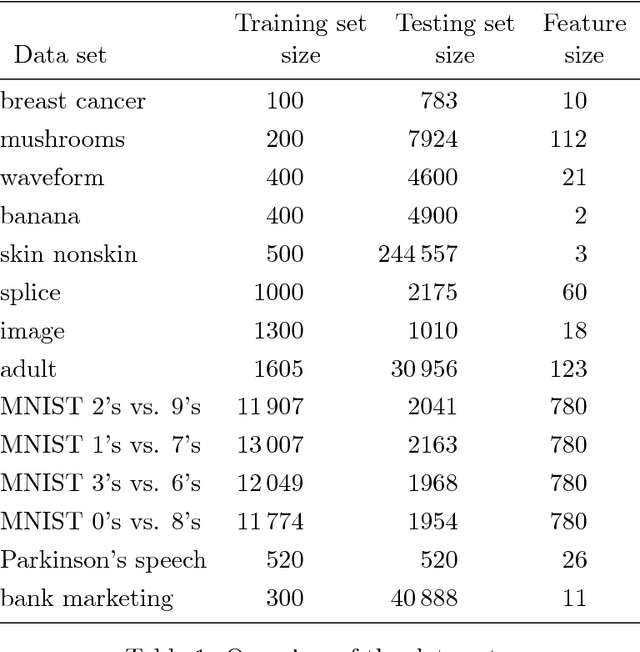
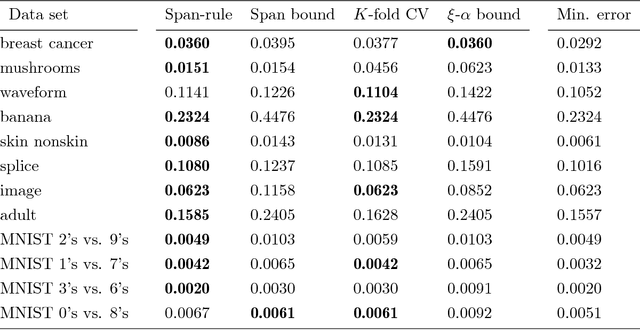
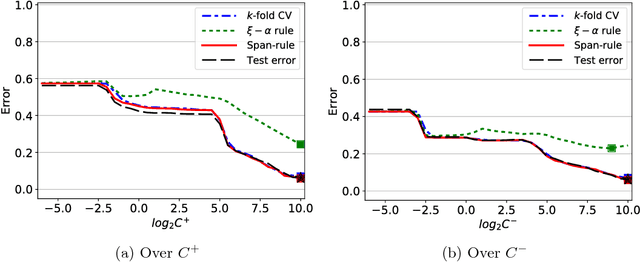
Weighted SVM (or fuzzy SVM) is the most widely used SVM variant owning its effectiveness to the use of instance weights. Proper selection of the instance weights can lead to increased generalization performance. In this work, we extend the span error bound theory to weighted SVM and we introduce effective hyperparameter selection methods for the weighted SVM algorithm. The significance of the presented work is that enables the application of span bound and span-rule with weighted SVM. The span bound is an upper bound of the leave-one-out error that can be calculated using a single trained SVM model. This is important since leave-one-out error is an almost unbiased estimator of the test error. Similarly, the span-rule gives the actual value of the leave-one-out error. Thus, one can apply span bound and span-rule as computationally lightweight alternatives of leave-one-out procedure for hyperparameter selection. The main theoretical contributions are: (a) we prove the necessary and sufficient condition for the existence of the span of a support vector in weighted SVM; and (b) we prove the extension of span bound and span-rule to weighted SVM. We experimentally evaluate the span bound and the span-rule for hyperparameter selection and we compare them with other methods that are applicable to weighted SVM: the $K$-fold cross-validation and the ${\xi}-{\alpha}$ bound. Experiments on 14 benchmark data sets and data sets with importance scores for the training instances show that: (a) the condition for the existence of span in weighted SVM is satisfied almost always; (b) the span-rule is the most effective method for weighted SVM hyperparameter selection; (c) the span-rule is the best predictor of the test error in the mean square error sense; and (d) the span-rule is efficient and, for certain problems, it can be calculated faster than $K$-fold cross-validation.