 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Confidence Ellipsoids and Applications to Robust Subspace Recovery
Dec 19, 2025

We study the problem of finding confidence ellipsoids for an arbitrary distribution in high dimensions. Given samples from a distribution $D$ and a confidence parameter $α$, the goal is to find the smallest volume ellipsoid $E$ which has probability mass $\Pr_{D}[E] \ge 1-α$. Ellipsoids are a highly expressive class of confidence sets as they can capture correlations in the distribution, and can approximate any convex set. This problem has been studied in many different communities. In statistics, this is the classic minimum volume estimator introduced by Rousseeuw as a robust non-parametric estimator of location and scatter. However in high dimensions, it becomes NP-hard to obtain any non-trivial approximation factor in volume when the condition number $β$ of the ellipsoid (ratio of the largest to the smallest axis length) goes to $\infty$. This motivates the focus of our paper: can we efficiently find confidence ellipsoids with volume approximation guarantees when compared to ellipsoids of bounded condition number $β$? Our main result is a polynomial time algorithm that finds an ellipsoid $E$ whose volume is within a $O(β)^{γd}$ multiplicative factor of the volume of best $β$-conditioned ellipsoid while covering at least $1-O(α/γ)$ probability mass for any $γ< α$. We complement this with a computational hardness result that shows that such a dependence seems necessary up to constants in the exponent. The algorithm and analysis uses the rich primal-dual structure of the minimum volume enclosing ellipsoid and the geometric Brascamp-Lieb inequality. As a consequence, we obtain the first polynomial time algorithm with approximation guarantees on worst-case instances of the robust subspace recovery problem.
Online Conformal Prediction with Efficiency Guarantees
Jul 03, 2025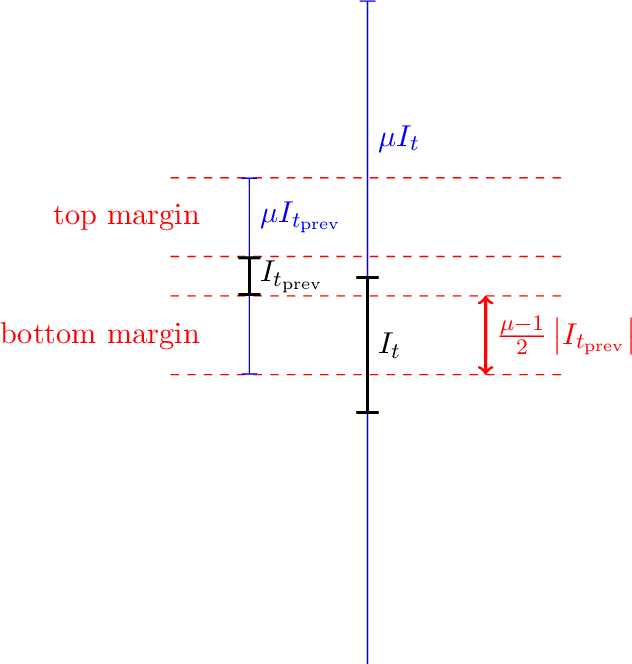
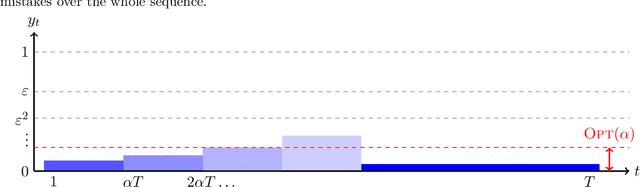
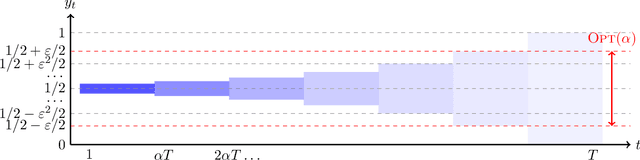
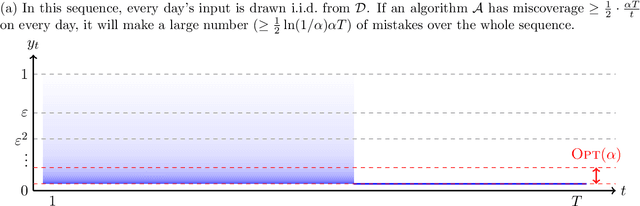
We study the problem of conformal prediction in a novel online framework that directly optimizes efficiency. In our problem, we are given a target miscoverage rate $\alpha > 0$, and a time horizon $T$. On each day $t \le T$ an algorithm must output an interval $I_t \subseteq [0, 1]$, then a point $y_t \in [0, 1]$ is revealed. The goal of the algorithm is to achieve coverage, that is, $y_t \in I_t$ on (close to) a $(1 - \alpha)$-fraction of days, while maintaining efficiency, that is, minimizing the average volume (length) of the intervals played. This problem is an online analogue to the problem of constructing efficient confidence intervals. We study this problem over arbitrary and exchangeable (random order) input sequences. For exchangeable sequences, we show that it is possible to construct intervals that achieve coverage $(1 - \alpha) - o(1)$, while having length upper bounded by the best fixed interval that achieves coverage in hindsight. For arbitrary sequences however, we show that any algorithm that achieves a $\mu$-approximation in average length compared to the best fixed interval achieving coverage in hindsight, must make a multiplicative factor more mistakes than $\alpha T$, where the multiplicative factor depends on $\mu$ and the aspect ratio of the problem. Our main algorithmic result is a matching algorithm that can recover all Pareto-optimal settings of $\mu$ and number of mistakes. Furthermore, our algorithm is deterministic and therefore robust to an adaptive adversary. This gap between the exchangeable and arbitrary settings is in contrast to the classical online learning problem. In fact, we show that no single algorithm can simultaneously be Pareto-optimal for arbitrary sequences and optimal for exchangeable sequences. On the algorithmic side, we give an algorithm that achieves the near-optimal tradeoff between the two cases.
Computing High-dimensional Confidence Sets for Arbitrary Distributions
Apr 03, 2025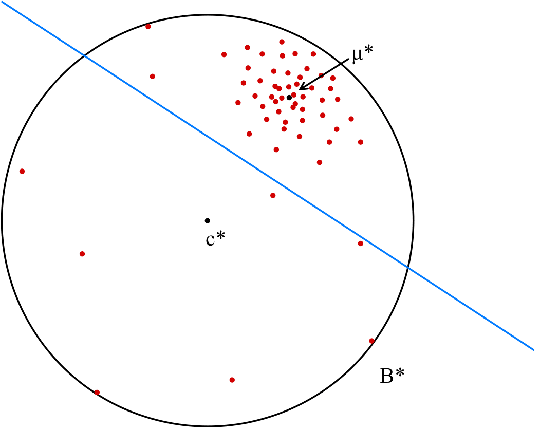
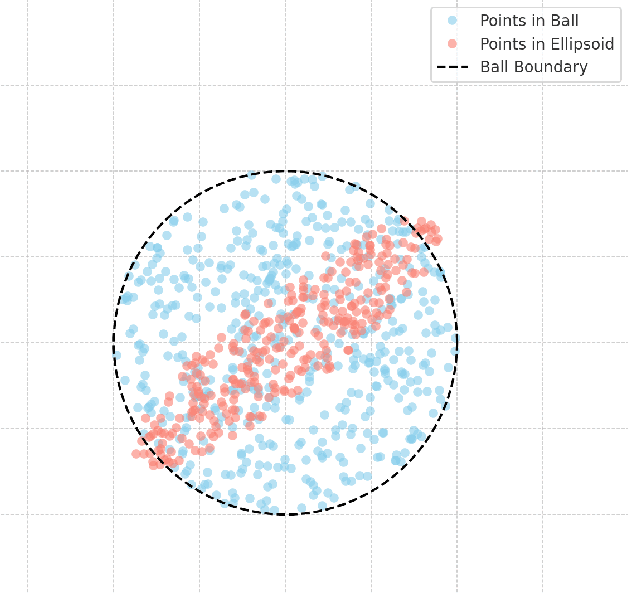


We study the problem of learning a high-density region of an arbitrary distribution over $\mathbb{R}^d$. Given a target coverage parameter $\delta$, and sample access to an arbitrary distribution $D$, we want to output a confidence set $S \subset \mathbb{R}^d$ such that $S$ achieves $\delta$ coverage of $D$, i.e., $\mathbb{P}_{y \sim D} \left[ y \in S \right] \ge \delta$, and the volume of $S$ is as small as possible. This is a central problem in high-dimensional statistics with applications in finding confidence sets, uncertainty quantification, and support estimation. In the most general setting, this problem is statistically intractable, so we restrict our attention to competing with sets from a concept class $C$ with bounded VC-dimension. An algorithm is competitive with class $C$ if, given samples from an arbitrary distribution $D$, it outputs in polynomial time a set that achieves $\delta$ coverage of $D$, and whose volume is competitive with the smallest set in $C$ with the required coverage $\delta$. This problem is computationally challenging even in the basic setting when $C$ is the set of all Euclidean balls. Existing algorithms based on coresets find in polynomial time a ball whose volume is $\exp(\tilde{O}( d/ \log d))$-factor competitive with the volume of the best ball. Our main result is an algorithm that finds a confidence set whose volume is $\exp(\tilde{O}(d^{2/3}))$ factor competitive with the optimal ball having the desired coverage. The algorithm is improper (it outputs an ellipsoid). Combined with our computational intractability result for proper learning balls within an $\exp(\tilde{O}(d^{1-o(1)}))$ approximation factor in volume, our results provide an interesting separation between proper and (improper) learning of confidence sets.
Volume Optimality in Conformal Prediction with Structured Prediction Sets
Feb 23, 2025Conformal Prediction is a widely studied technique to construct prediction sets of future observations. Most conformal prediction methods focus on achieving the necessary coverage guarantees, but do not provide formal guarantees on the size (volume) of the prediction sets. We first prove an impossibility of volume optimality where any distribution-free method can only find a trivial solution. We then introduce a new notion of volume optimality by restricting the prediction sets to belong to a set family (of finite VC-dimension), specifically a union of $k$-intervals. Our main contribution is an efficient distribution-free algorithm based on dynamic programming (DP) to find a union of $k$-intervals that is guaranteed for any distribution to have near-optimal volume among all unions of $k$-intervals satisfying the desired coverage property. By adopting the framework of distributional conformal prediction (Chernozhukov et al., 2021), the new DP based conformity score can also be applied to achieve approximate conditional coverage and conditional restricted volume optimality, as long as a reasonable estimator of the conditional CDF is available. While the theoretical results already establish volume-optimality guarantees, they are complemented by experiments that demonstrate that our method can significantly outperform existing methods in many settings.
Competitive strategies to use "warm start" algorithms with predictions
May 06, 2024We consider the problem of learning and using predictions for warm start algorithms with predictions. In this setting, an algorithm is given an instance of a problem, and a prediction of the solution. The runtime of the algorithm is bounded by the distance from the predicted solution to the true solution of the instance. Previous work has shown that when instances are drawn iid from some distribution, it is possible to learn an approximately optimal fixed prediction (Dinitz et al, NeurIPS 2021), and in the adversarial online case, it is possible to compete with the best fixed prediction in hindsight (Khodak et al, NeurIPS 2022). In this work we give competitive guarantees against stronger benchmarks that consider a set of $k$ predictions $\mathbf{P}$. That is, the "optimal offline cost" to solve an instance with respect to $\mathbf{P}$ is the distance from the true solution to the closest member of $\mathbf{P}$. This is analogous to the $k$-medians objective function. In the distributional setting, we show a simple strategy that incurs cost that is at most an $O(k)$ factor worse than the optimal offline cost. We then show a way to leverage learnable coarse information, in the form of partitions of the instance space into groups of "similar" instances, that allows us to potentially avoid this $O(k)$ factor. Finally, we consider an online version of the problem, where we compete against offline strategies that are allowed to maintain a moving set of $k$ predictions or "trajectories," and are charged for how much the predictions move. We give an algorithm that does at most $O(k^4 \ln^2 k)$ times as much work as any offline strategy of $k$ trajectories. This algorithm is deterministic (robust to an adaptive adversary), and oblivious to the setting of $k$. Thus the guarantee holds for all $k$ simultaneously.
The Predicted-Deletion Dynamic Model: Taking Advantage of ML Predictions, for Free
Jul 17, 2023The main bottleneck in designing efficient dynamic algorithms is the unknown nature of the update sequence. In particular, there are some problems, like 3-vertex connectivity, planar digraph all pairs shortest paths, and others, where the separation in runtime between the best partially dynamic solutions and the best fully dynamic solutions is polynomial, sometimes even exponential. In this paper, we formulate the predicted-deletion dynamic model, motivated by a recent line of empirical work about predicting edge updates in dynamic graphs. In this model, edges are inserted and deleted online, and when an edge is inserted, it is accompanied by a "prediction" of its deletion time. This models real world settings where services may have access to historical data or other information about an input and can subsequently use such information make predictions about user behavior. The model is also of theoretical interest, as it interpolates between the partially dynamic and fully dynamic settings, and provides a natural extension of the algorithms with predictions paradigm to the dynamic setting. We give a novel framework for this model that "lifts" partially dynamic algorithms into the fully dynamic setting with little overhead. We use our framework to obtain improved efficiency bounds over the state-of-the-art dynamic algorithms for a variety of problems. In particular, we design algorithms that have amortized update time that scales with a partially dynamic algorithm, with high probability, when the predictions are of high quality. On the flip side, our algorithms do no worse than existing fully-dynamic algorithms when the predictions are of low quality. Furthermore, our algorithms exhibit a graceful trade-off between the two cases. Thus, we are able to take advantage of ML predictions asymptotically "for free.''
Memory Bounds for the Experts Problem
Apr 21, 2022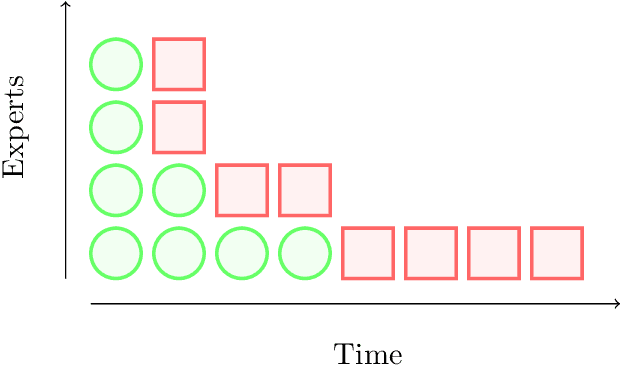
Online learning with expert advice is a fundamental problem of sequential prediction. In this problem, the algorithm has access to a set of $n$ "experts" who make predictions on each day. The goal on each day is to process these predictions, and make a prediction with the minimum cost. After making a prediction, the algorithm sees the actual outcome on that day, updates its state, and then moves on to the next day. An algorithm is judged by how well it does compared to the best expert in the set. The classical algorithm for this problem is the multiplicative weights algorithm. However, every application, to our knowledge, relies on storing weights for every expert, and uses $\Omega(n)$ memory. There is little work on understanding the memory required to solve the online learning with expert advice problem, or run standard sequential prediction algorithms, in natural streaming models, which is especially important when the number of experts, as well as the number of days on which the experts make predictions, is large. We initiate the study of the learning with expert advice problem in the streaming setting, and show lower and upper bounds. Our lower bound for i.i.d., random order, and adversarial order streams uses a reduction to a custom-built problem using a novel masking technique, to show a smooth trade-off for regret versus memory. Our upper bounds show novel ways to run standard sequential prediction algorithms in rounds on small "pools" of experts, thus reducing the necessary memory. For random-order streams, we show that our upper bound is tight up to low order terms. We hope that these results and techniques will have broad applications in online learning, and can inspire algorithms based on standard sequential prediction techniques, like multiplicative weights, for a wide range of other problems in the memory-constrained setting.