 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe-Planner: A Single-Outcome Replanner for Computing Strong Cyclic Policies in Fully Observable Non-Deterministic Domains
Sep 23, 2021
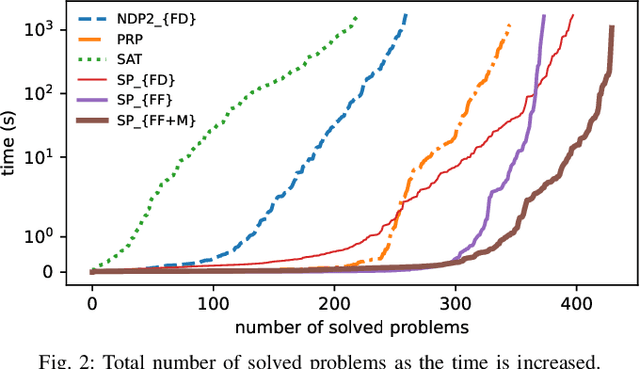
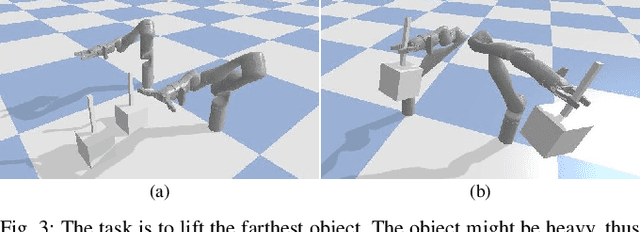
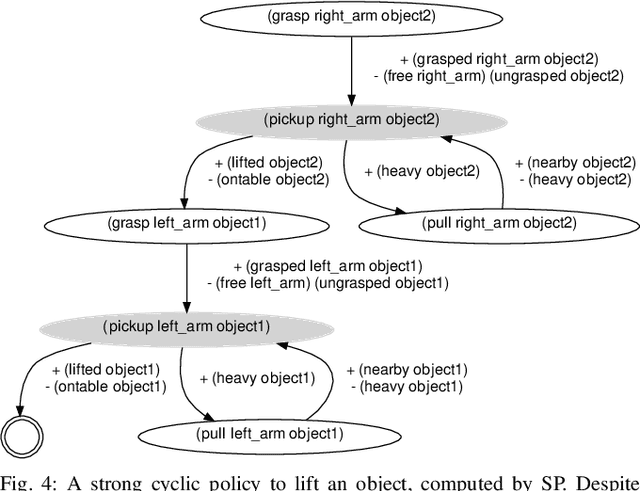
Replanners are efficient methods for solving non-deterministic planning problems. Despite showing good scalability, existing replanners often fail to solve problems involving a large number of misleading plans, i.e., weak plans that do not lead to strong solutions, however, due to their minimal lengths, are likely to be found at every replanning iteration. The poor performance of replanners in such problems is due to their all-outcome determinization. That is, when compiling from non-deterministic to classical, they include all compiled classical operators in a single deterministic domain which leads replanners to continually generate misleading plans. We introduce an offline replanner, called Safe-Planner (SP), that relies on a single-outcome determinization to compile a non-deterministic domain to a set of classical domains, and ordering heuristics for ranking the obtained classical domains. The proposed single-outcome determinization and the heuristics allow for alternating between different classical domains. We show experimentally that this approach can allow SP to avoid generating misleading plans but to generate weak plans that directly lead to strong solutions. The experiments show that SP outperforms state-of-the-art non-deterministic solvers by solving a broader range of problems. We also validate the practical utility of SP in real-world non-deterministic robotic tasks.
Computing the Scope of Applicability for Acquired Task Knowledge in Experience-Based Planning Domains
Mar 13, 2019


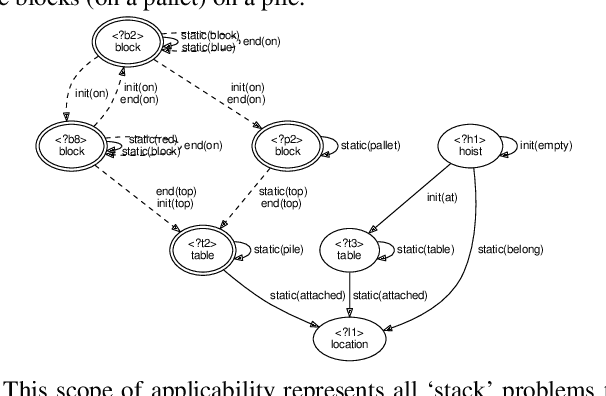
Experience-based planning domains have been proposed to improve problem solving by learning from experience. They rely on acquiring and using task knowledge, i.e., activity schemata, for generating solutions to problem instances in a class of tasks. Using Three-Valued Logic Analysis (TVLA), we extend previous work to generate a set of conditions that determine the scope of applicability of an activity schema. The inferred scope is a bounded representation of a set of problems of potentially unbounded size, in the form of a 3-valued logical structure, which is used to automatically find an applicable activity schema for solving task problems. We validate this work in two classical planning domains.
Learning Task Knowledge and its Scope of Applicability in Experience-Based Planning Domains
Mar 05, 2019



Experience-based planning domains (EBPDs) have been recently proposed to improve problem solving by learning from experience. EBPDs provide important concepts for long-term learning and planning in robotics. They rely on acquiring and using task knowledge, i.e., activity schemata, for generating concrete solutions to problem instances in a class of tasks. Using Three-Valued Logic Analysis (TVLA), we extend previous work to generate a set of conditions as the scope of applicability for an activity schema. The inferred scope is a bounded representation of a set of problems of potentially unbounded size, in the form of a 3-valued logical structure, which allows an EBPD system to automatically find an applicable activity schema for solving task problems. We demonstrate the utility of our approach in a set of classes of problems in a simulated domain and a class of real world tasks in a fully physically simulated PR2 robot in Gazebo.