 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing $αμ$
Jan 29, 2021



$\alpha\mu$ is a search algorithm which repairs two defaults of Perfect Information Monte Carlo search: strategy fusion and non locality. In this paper we optimize $\alpha\mu$ for the game of Bridge, avoiding useless computations. The proposed optimizations are general and apply to other imperfect information turn-based games. We define multiple optimizations involving Pareto fronts, and show that these optimizations speed up the search. Some of these optimizations are cuts that stop the search at a node, while others keep track of which possible worlds have become redundant, avoiding unnecessary, costly evaluations. We also measure the benefits of parallelizing the double dummy searches at the leaves of the $\alpha\mu$ search tree.
Construction and Elicitation of a Black Box Model in the Game of Bridge
May 04, 2020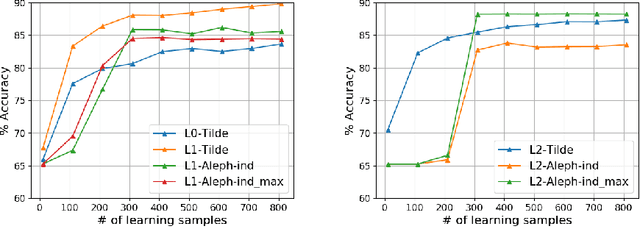
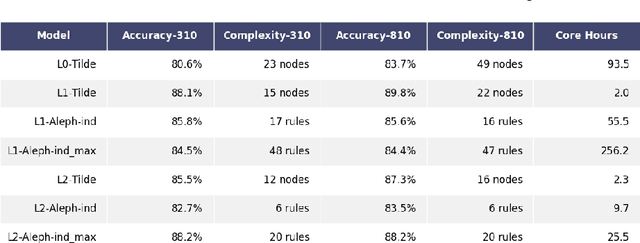
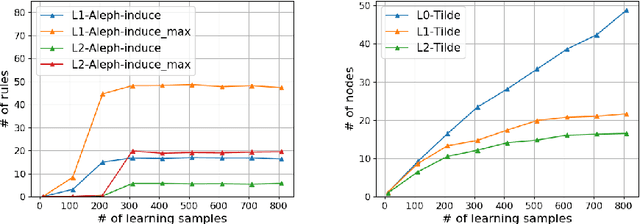

We address the problem of building a decision model for a specific bidding situation in the game of Bridge. We propose the following multi-step methodology i) Build a set of examples for the decision problem and use simulations to associate a decision to each example ii) Use supervised relational learning to build an accurate and readable model iii) Perform a joint analysis between domain experts and data scientists to improve the learning language, including the production by experts of a handmade model iv) Build a better, more readable and accurate model.
The αμ Search Algorithm for the Game of Bridge
Nov 18, 2019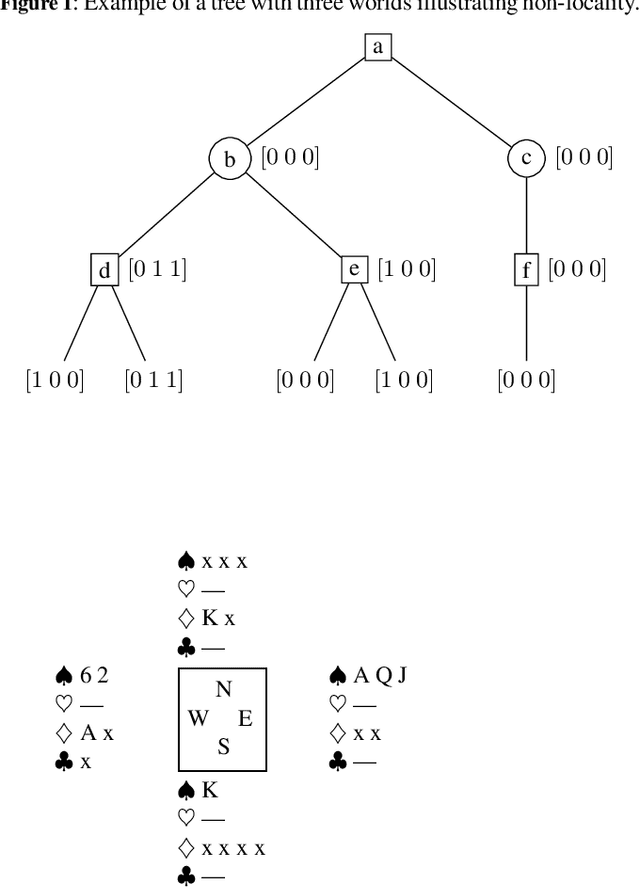
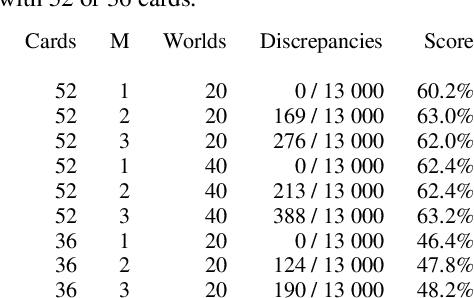
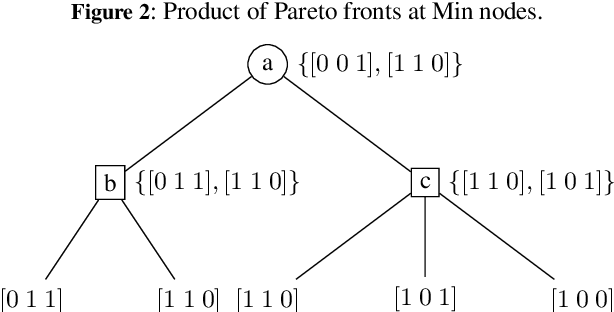
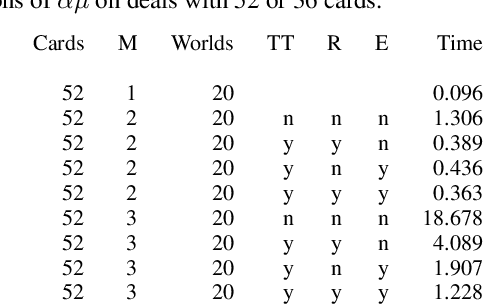
{\alpha}{\mu} is an anytime heuristic search algorithm for incomplete information games that assumes perfect information for the opponents. {\alpha}{\mu} addresses the strategy fusion and non-locality problems encountered by Perfect Information Monte Carlo sampling. In this paper {\alpha}{\mu} is applied to the game of Bridge.
Logical settings for concept learning from incomplete examples in First Order Logic
Jul 20, 2006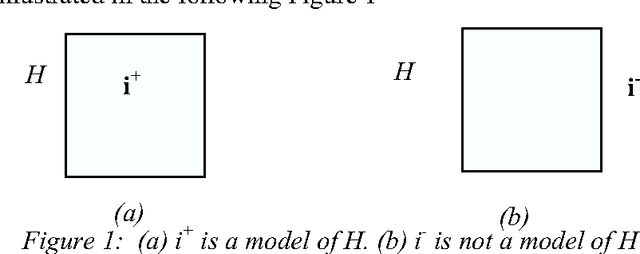
We investigate here concept learning from incomplete examples. Our first purpose is to discuss to what extent logical learning settings have to be modified in order to cope with data incompleteness. More precisely we are interested in extending the learning from interpretations setting introduced by L. De Raedt that extends to relational representations the classical propositional (or attribute-value) concept learning from examples framework. We are inspired here by ideas presented by H. Hirsh in a work extending the Version space inductive paradigm to incomplete data. H. Hirsh proposes to slightly modify the notion of solution when dealing with incomplete examples: a solution has to be a hypothesis compatible with all pieces of information concerning the examples. We identify two main classes of incompleteness. First, uncertainty deals with our state of knowledge concerning an example. Second, generalization (or abstraction) deals with what part of the description of the example is sufficient for the learning purpose. These two main sources of incompleteness can be mixed up when only part of the useful information is known. We discuss a general learning setting, referred to as "learning from possibilities" that formalizes these ideas, then we present a more specific learning setting, referred to as "assumption-based learning" that cope with examples which uncertainty can be reduced when considering contextual information outside of the proper description of the examples. Assumption-based learning is illustrated on a recent work concerning the prediction of a consensus secondary structure common to a set of RNA sequences.