 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogical settings for concept learning from incomplete examples in First Order Logic
Jul 20, 2006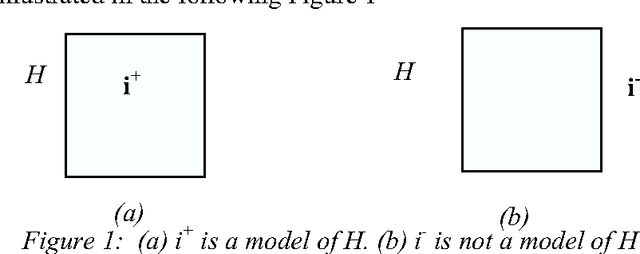
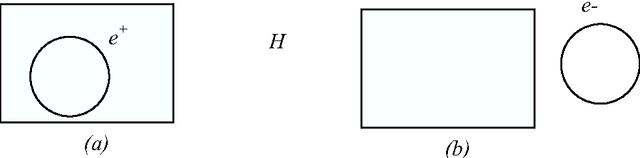
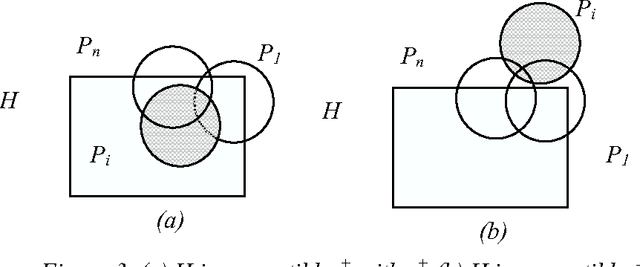
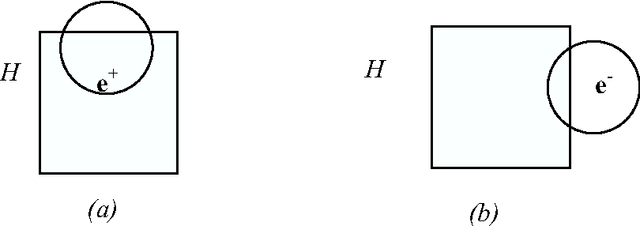
We investigate here concept learning from incomplete examples. Our first purpose is to discuss to what extent logical learning settings have to be modified in order to cope with data incompleteness. More precisely we are interested in extending the learning from interpretations setting introduced by L. De Raedt that extends to relational representations the classical propositional (or attribute-value) concept learning from examples framework. We are inspired here by ideas presented by H. Hirsh in a work extending the Version space inductive paradigm to incomplete data. H. Hirsh proposes to slightly modify the notion of solution when dealing with incomplete examples: a solution has to be a hypothesis compatible with all pieces of information concerning the examples. We identify two main classes of incompleteness. First, uncertainty deals with our state of knowledge concerning an example. Second, generalization (or abstraction) deals with what part of the description of the example is sufficient for the learning purpose. These two main sources of incompleteness can be mixed up when only part of the useful information is known. We discuss a general learning setting, referred to as "learning from possibilities" that formalizes these ideas, then we present a more specific learning setting, referred to as "assumption-based learning" that cope with examples which uncertainty can be reduced when considering contextual information outside of the proper description of the examples. Assumption-based learning is illustrated on a recent work concerning the prediction of a consensus secondary structure common to a set of RNA sequences.