 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHiSeg: Capturing Uncertainty in Medical Image Segmentation
Jun 07, 2019

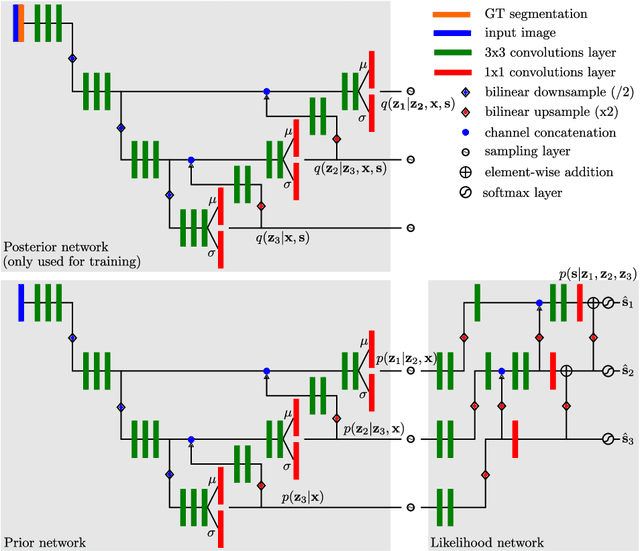

Segmentation of anatomical structures and pathologies is inherently ambiguous. For instance, structure borders may not be clearly visible or different experts may have different styles of annotating. The majority of current state-of-the-art methods do not account for such ambiguities but rather learn a single mapping from image to segmentation. In this work, we propose a novel method to model the conditional probability distribution of the segmentations given an input image. We derive a hierarchical probabilistic model, in which separate latent spaces are responsible for modelling the segmentation at different resolutions. Inference in this model can be efficiently performed using the variational autoencoder framework. We show that our proposed method can be used to generate significantly more realistic and diverse segmentation samples compared to recent related work, both, when trained with annotations from a single or multiple annotators.